Introducción
La fragmentación de la roca es un pilar fundamental en la viabilidad económica y la eficiencia operativa de cualquier proyecto minero (Xie et al., 2021; Zamora-Paredes et al., 2020). La voladura, como etapa inicial de conminución, impacta directamente los costos y la productividad de operaciones subsiguientes como carga, transporte, trituración y molienda (Yakovlev et al., 2024). Una fragmentación óptima es crucial (Aryafar et al., 2020), pero la presencia de rocas sobredimensionadas aumenta costos por voladuras secundarias y genera impactos ambientales como polvo y vibraciones (Su & Ma, 2022) (Guerrero-Rodriguez et al., 2024). De hecho, más del 70 % de la energía explosiva se desperdicia en efectos adversos, en lugar de contribuir a una fragmentación efectiva. Tradicionalmente, la predicción se ha basado en modelos empíricos como Rosin-Rammler o Kuz-Ram (Vu & Bao, 2021); no obstante, estos métodos son limitados por su dependencia de trabajo manual, sesgos de datos y la incapacidad de capturar las complejas relaciones no lineales y propiedades de la masa rocosa (Ohadi et al., 2020).
Para superar estas limitaciones, la inteligencia artificial (IA) se presenta como una alternativa prometedora en la ingeniería minera (Saadoun et al., 2024). Los modelos de IA, con su capacidad de autoaprendizaje y reconocimiento de patrones no lineales, permiten predicciones más precisas y la optimización de los diseños de voladura (Leng et al., 2020). El presente estudio propone el desarrollo de un modelo predictivo aplicando técnicas de IA para la fragmentación de roca en voladuras a cielo abierto. Para optimizar los parámetros de voladura y lograr una rotura de roca más efectiva, se evalúan tres algoritmos de aprendizaje automático (Random Forest, Support Vector Machine y Kernel Ridge Regression) con el fin de reducir costos y minimizar impactos ambientales (Zhao et al., 2024). La contribución concreta de este trabajo es
una herramienta de software predictiva confiable y precisa con una interfaz gráfica de usuario que permitirá ajustar proactivamente la voladura, mejorando la eficiencia operativa, la productividad y la recuperación del mineral, mientras se mitigan los daños económicos y ecológicos (Górriz et al., 2023).
Metodología
Trabajo previo
El análisis comparativo de once investigaciones sobre fragmentación revela una amplia variedad de metodologías utilizadas y variables seleccionadas, las cuales se ven afectadas por los objetivos particulares y el contexto geográfico y operativo de cada uno de los trabajos. La fuente de los datos difiere en gran medida: hay investigaciones que se centran en una única área, mientras que otras incluyen varias regiones y naciones, como Chile, Turquía, Perú, Finlandia, Cuba y Zambia, o incluso abarcan escalas a nivel global, lo que influye en la cantidad y el tipo de información analizada. Respecto a las metodologías, la Figura 1 destaca la aplicación de técnicas de IA y modelos empíricos.
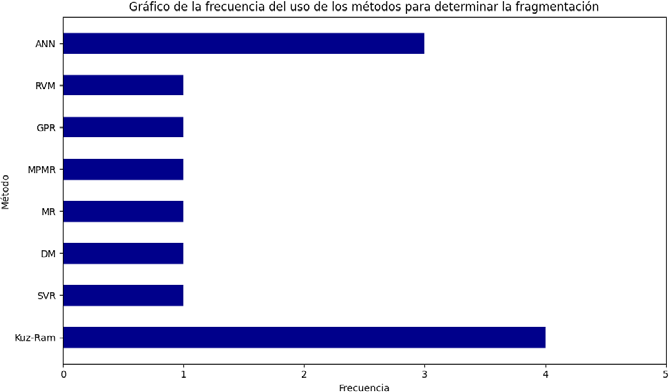 Figura 1
Frecuencia de los modelos empleados en las investigaciones analizadas
Figura 1
Frecuencia de los modelos empleados en las investigaciones analizadas
La red neuronal artificial (ANN) utilizada en tres investigaciones (Amoako et al., 2022; de Castro, 2021; Rosales-Huamani et al., 2020) y el modelo Kuz-Ram aplicado en cuatro (Bunga et al., 2020; Castro, 2021; Mwango, 2019; Rojas Linares, 2018) son los más frecuentes, lo que indica su versatilidad y establecimiento. Métodos alternativos comprenden la máquina de vectores de relevancia (RVM), la regresión de procesos Gaussianos (GPR), la regresión de probabilidad minimax (MPMR), la regresión múltiple y la matriz de decisión, cada uno con sus respectivos fundamentos teóricos. No obstante, ellos están limitados por la adaptabilidad al tipo de roca y la presentación de los resultados, ya que no facilitan una mejor visualización para el usuario final.
Propuesta
A diferencia de los trabajos anteriores, este estudio busca cuantificar la fragmentación durante voladuras considerando diferentes tipos de rocas. Incorpora nueve categorías de litologías, que incluyen ígneas, metamórficas y sedimentarias, con el fin de analizar el comportamiento de los materiales geológicos. Además, se seleccionaron los tres algoritmos de IA con la mayor
precisión reportada en la literatura, que son evaluados y comparados, tanto entre ellos como con un método convencional ampliamente utilizado. Posteriormente, se desarrolla una aplicación de software para optimizar la calidad del producto, implementando un sistema de retroalimentación constante. En esencia, la metodología sigue los pasos del aprendizaje automático (ML) clásico, agrupados en dos grandes etapas: datos y modelo, tal como se ilustra en la Figura 2.
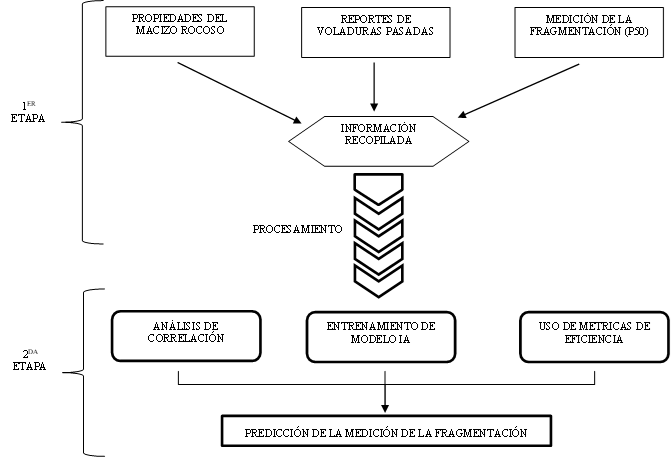 Figura 2
Flujograma de la metodología empleada para el proyecto
Figura 2
Flujograma de la metodología empleada para el proyecto
La primera etapa se dedica al conjunto de datos, donde se recopilan y analizan datos de caracterización geotécnica, registros históricos y mediciones de fragmentación para obtener métricas como el tamaño crítico P(50), para identificar inconsistencias por variaciones geológicas o errores. La segunda etapa corresponde a los métodos de procesamiento de estos datos. Aquí se utilizan modelos matemáticos y algoritmos de IA para correlacionar variables como dureza del material y parámetros de diseño, para predecir resultados y mejorar la planificación. Este enfoque reduce incertidumbre, optimiza eficiencia energética y económica y se adapta a diversos contextos mineros, priorizando sostenibilidad. La integración de datos experimentales, simulaciones y registros históricos asegura robustez, ajustando factores como separación de barrenos o cantidad de explosivo para maximizar recursos y minimizar costos. A continuación, se explican con más detalle los datos y modelos utilizados.
Datos
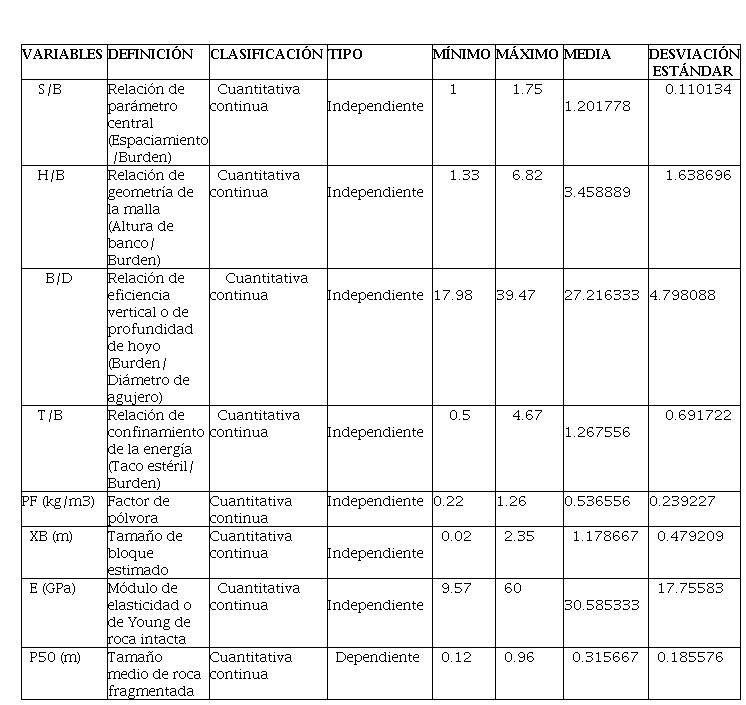
Los datos se recopilaron a partir de una investigación detallada realizada por hudaverdi et al. (2006), que abarca un total de 97 registros de diversas partes del mundo, asegurando así una adecuada representatividad. Cada registro incluye ocho factores principales que afectan la fragmentación y el rendimiento en las voladuras (Tabla 1): espaciamiento/burden (S/B), altura de banco/burden (H/B), burden/diámetro de barreno (B/D), stemming/burden (T/B), factor de pólvora (PF), tamaño de bloque in situ (XB), módulo de elasticidad (E) y tamaño medio de fragmentación (P50) como variable dependiente.
Tabla 1
Variables del conjunto de datos y sus indicadores estadísticos más importantes
| VARIABLES | DEFINICIÓN | CLASIFICACIÓN | TIPO | MÍNIMO | MÁXIMO | MEDIA | DESVIACIÓNESTÁNDAR |
| S/B | Relación de parámetro central (Espaciamiento /Burden) | Cuantitativa continua | Independiente | 1 | 1.75 | 1.201778 | 0.110134 |
| H/B | Relación de geometría de la malla (Altura de banco/ Burden) | Cuantitativa continua | Independiente | 1.33 | 6.82 | 3.458889 | 1.638696 |
| B/D | Relación de eficiencia vertical o de profundidad de hoyo (Burden/ Diámetro de agujero) | Cuantitativa continua | Independiente | 17.98 | 39.47 | 27.216333 | 4.798088 |
| T/B | Relación de confinamiento de la energía (Taco estéril/ Burden) | Cuantitativa continua | Independiente | 0.5 | 4.67 | 1.267556 | 0.691722 |
| PF (kg/m3) | Factor de pólvora | Cuantitativa continua | Independiente | 0.22 | 1.26 | 0.536556 | 0.239227 |
| XB (m) | Tamaño de bloque estimado | Cuantitativa continua | Independiente | 0.02 | 2.35 | 1.178667 | 0.479209 |
| E (GPa) | Módulo de elasticidad o de Young de roca intacta | Cuantitativa continua | Independiente | 9.57 | 60 | 30.585333 | 17.75583 |
| P50 (m) | Tamaño medio de roca fragmentada | Cuantitativa continua | Dependiente | 0.12 | 0.96 | 0.315667 | 0.185576 |
Aunque el número de registros es limitado, ya que su contenido es único, especializado y de difícil acceso, este conjunto de datos es particularmente relevante para el estudio. Mediante el uso de unidades del Sistema Internacional, se crearon relaciones sólidas para modelos de predicción que son útiles en situaciones geotécnicas y mineras. El análisis estadístico expone las conexiones entre las variables, enfatizando la desviación estándar. Un valor elevado en el módulo de elasticidad (E = 17. 755830 GPa) indica una alta variabilidad, lo que influye en la capacidad para realizar predicciones. En contraste, el reducido valor del factor de pólvora (PF = 0. 239227 kg/m³) sugiere una uniformidad que propicia resultados consistentes.
Métodos
Kuz-Ram
Es un modelo empírico muy utilizado en la minería, anticipa cómo se fragmentan las rocas después de las explosiones, mejorando las operaciones en la planta al calcular cómo se distribuirán los tamaños de los fragmentos (Hekmat et al., 2019). Se fundamenta en criterios tales como el factor geológico (volabilidad), diseño de voladura (burden, espaciamiento, altura del banco) y propiedades del material explosivo (cantidad, tipo, densidad) (López et al., 2003). El tamaño promedio del fragmento (P50) se determina utilizando la Ec. 1 (Kuznetsov, 1973). Para optimizar la granulometría, se modifican el burden y el espaciamiento, lo que incrementa la productividad. La validación confronta las predicciones con el análisis de imágenes (Split Desktop, WipFrag), lo que permite realizar ajustes para incrementar la precisión (Das et al.,2023(, A pesar de que Kuz-Ram es sencillo de aplicar y valioso para los diseños iniciales, puede sobreestimar el tamaño de los fragmentos en algunas rocas, dependiendo de la calidad de los datos y del factor de la roca (Lawal, 2021), Los modelos ajustados y los elementos de correción optimizan su calibración y alineación de los resultados experimentales.
Random Forest
Es un algoritmo de aprendizaje automático; se caracteriza por su eficacia en la predicción de la fragmentación de rocas en los procesos de voladuras mineras, lo que permite optimizar los procesos y aumentar la eficiencia (Shafl, 2024). Comienza recolectando información de campo, como características geomecánicas (resistencia uniaxial y módulo de elasticidad), parámetros relacionados con la voladura (distancia entre agujeros/carga y factor de carga) y datos empíricos (promedio del tamaño de los fragmentos) (Hu et al., 2023). Se entrena un conjunto de árboles de decisión utilizando subconjuntos aleatorios de datos, aplicando la técnica de bootstrapping y la selección aleatoria de variables, con el fin de disminuir las correlaciones y mejorar la robustez (Raj et al., 2024). Se establece el hiperparámetro de número de estimadores (número de árboles) para prevenir el sobreajuste (Zhao et al., 2024). Validado con indicadores como el error cuadrático medio y el coeficiente de determinación, el modelo Random Forest presenta una mayor precisión en comparación con otros modelos. Además, identifica variables clave a través de análisis de sensibilidad y optimiza diseños de voladura, logrando las distribuciones granulométricas deseadas y aumentando la productividad en minería (Y. L. Zhang et al., 2024).
Support Vector Regressor
El algoritmo SVR se distingue por su exactitud en la predicción de la fragmentación de rocas durante las voladuras, superando a los modelos empíricos convencionales (Rabbani et al., 2024). Comienza con la recopilación de datos, que debe incluir los parámetros de voladura, las propiedades geomecánicas y métricas tales como P50 o P80 (Hasanipanah et al., 2018). Estos conjuntos de datos, que están separados en grupos de entrenamiento y de prueba, se obtuvieron a partir de explosiones reales (Li et al., 2021). El modelo SVR es entrenado para estimar el tamaño de los fragmentos, adecuando el hiperparámetro de regularización C (Miao et al., 2021). Su rendimiento se valora mediante indicadores tales como el Error Cuadrático Medio.
Kernel Ridge Regression
La regresión KRR es una técnica de aprendizaje automático utilizada para modelar relaciones no lineales en la predicción de la fragmentación de rocas durante voladuras mineras, destacándose por su alta precisión (Wu et al., 2024). Emplea funciones de kernel para trasladar datos a espacios dimensionales más altos y aplica regularización ridge para prevenir el sobreajuste, lo que mejora la solidez de las predicciones (Lin, 2023). El procedimiento inicia con la recopilación de datos a partir de investigaciones de campo o simulaciones, separándolos en grupos de entrenamiento y de prueba (R. Zhang et al., 2023). Se entrena el modelo KRR optimizando el hiperparámetro de coeficiente de kernel. Métodos como KRR autoadaptativo mejoran el rendimiento, medido con métricas estándar, garantizando así pronósticos precisos y consistentes (Yin et al., 2020).
Resultados y Discusión
Análisis estadístico
La Figura 3 representa el diagrama de pairplot, que muestra conexiones relevantes entre las variables del estudio, dispuestas de acuerdo con su tipo y fuerza. En las correlaciones positivas, se detectaron desde débiles a moderadas (0.31 a 0.48), destacando XB-P50 y E-P50 (ambas 0.48), las cuales evidenciaron tendencias claramente en aumento y un agrupamiento notable de los puntos. Por otra parte, T/B-P50 (0.42) y H/B-T/B (0.39) mostraron una concentración inferior. Respecto a las correlaciones pequeñas (0.15 a 0.20), como S/B-H/B (0.16) y XB-E (0.20), se observó una considerable dispersión. Dado que los coeficientes de correlación van de moderados a bajos, no existe una multicolinealidad significativa entre las variables. Por ello, se justifica su uso en un modelo predictivo, donde se definen claramente los roles de variable independiente y dependiente.
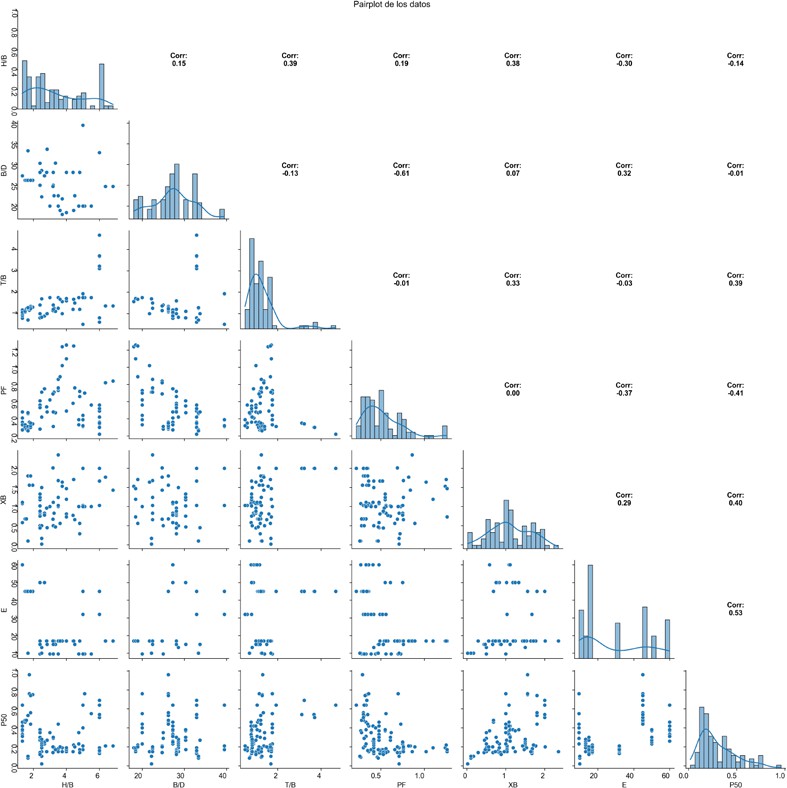 Figura 3
Pairplot de los datos de entrada y salida
Figura 3
Pairplot de los datos de entrada y salida
Los histogramas en diagonal del pairplot apoyaron este análisis, exhibiendo distribuciones asimétricas (S/B con sesgo hacia la derecha), uniformes (H/B entre 2.5 y 5) y simétricas (XB centrado en valores promedios). En situaciones de correlaciones negativas, estas fluctuaron entre bajas (-0.22 a -0.45) y moderadamente altas (-0.60), destacándose PF-B/D (-0.60) como la más robusta, con una clara tendencia a la baja, seguida por PF-P50 (-0.45) y PF-XB (-0.41). Las relaciones débiles negativas (B/D-T/B: -0.10; T/B-PF: -0.03) exhibieron patrones que se
asemejan a la aleatoriedad; además, los histogramas destacaron características relevantes en la distribución: B/D se concentra entre 20 y 40, T/B presenta un sesgo hacia la izquierda y P50 tiene una distribución ajustada alrededor de un valor medio. Al exhibir patrones que no siguen una línea recta, estos diagramas confirman la ausencia de una correlación lineal, lo cual justifica plenamente la implementación de un modelo de IA para capturar la complejidad inherente de estas relaciones.
El gráfico de caja y bigotes (Figura 4) ilustra la distribución logarítmica de las variables S/B, H/B, B/D, T/B, PF, XB, E y P50. En el caso de S/B, B/D y P50, existe una importante concentración, con cajas compactas; S/B presenta una mediana cercana a 10¹ y un rango limitado (10⁰-10¹). En comparación, H/B, T/B, PF, XB y E exhiben una dispersión más amplia. H/B presenta un 50 % central extenso, con una mediana de 10¹, en tanto que T/B y XB exhiben amplios rangos intercuartílicos y medianas próximas a 10⁰. Los valores atípicos de S/B, T/B y PF (círculos) muestran desviaciones importantes, lo que refleja la variabilidad presente en los datos.
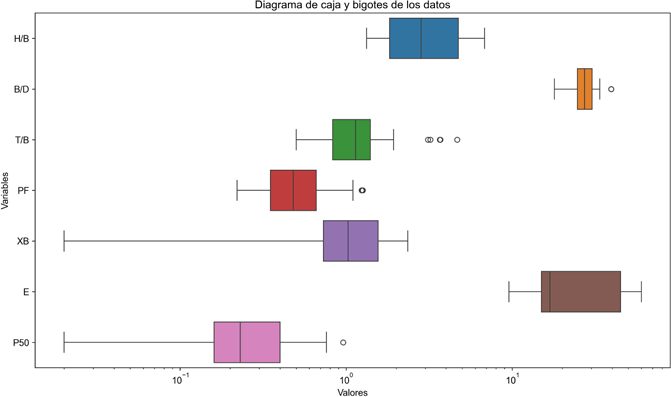 Figura 4
Diagrama de caja y bigotes de las variables del estudio
Figura 4
Diagrama de caja y bigotes de las variables del estudio
Aunque los diagramas de caja resaltan la variabilidad y la presencia de valores atípicos que sugieren comportamientos inusuales, estos son escasos y, por lo tanto, no afectan significativamente al modelo, obviando la necesidad de un análisis especial. Esta variabilidad, particularmente en P50 y el factor de pólvora, subraya la diversidad de reacciones de cada unidad litológica a la explosión, lo que resalta la importancia de desarrollar modelos adaptativos para optimizar los procesos mineros.
Entrenamiento de los algoritmos de IA
El entrenamiento de los tres modelos de IA revela las variaciones en su habilidad para hacer predicciones (Figura 5). El modelo SVR (línea roja) muestra una gran consistencia, con valores de objetivo alrededor de 0.26 y sin cambios significativos. Por otra parte, KRR (verde) muestra valores cercanos a cero, con un ligero incremento al inicio, permaneciendo casi constante, lo que indica una reacción mínima. Por otro lado, RF (azul) exhibe una conducta más activa, con cambios destacados y picos que sobrepasan el 0.60, logrando una mejor comprensión de las variaciones del objetivo. En relación con los tiempos de procesamiento, el modelo RF requiere 0.152 segundos para el entrenamiento y 0.254 segundos para la predicción. KRR es más eficiente, con un tiempo de entrenamiento de 0.296 segundos y un tiempo de predicción de 0.154 segundos. SVR, aunque se asemeja a KRR en su proceso de entrenamiento, requiere 0.506 segundos para realizar la predicción. RF se caracteriza por su capacidad de adaptación, mientras que KRR y SVR proporcionan mayor estabilidad, aunque son menos receptivos a las varicaciones en los datos.
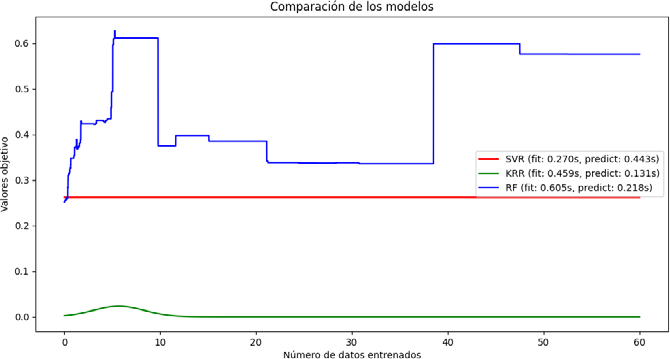 Figura 5
Comparación del rendimiento de los modelos de IA empleados
Figura 5
Comparación del rendimiento de los modelos de IA empleados
Por otra parte, en la Figura 6, el modelo KRR presenta un comportamiento más inestable y es muy sensible a la cantidad de datos que se le suministran. Se pueden observar picos de error en los valores intermedios, particularmente cerca de las 20 muestras, donde el MSE excede 0.09. A pesar de que su desempeño presenta una ligera mejora más adelante, nunca consigue igualar la precisión del SVR ni del RF, lo que sugiere modificaciones en su regularización o en las funciones kernel que emplea. Respecto al modelo RF, muestra una trayectoria más variable, particularmente entre las 20 y 55 muestras, lo que podría indicar una inclinación al sobreajuste en conjuntos pequeños o medianamente grandes. No obstante, a partir de las 60 muestras, el error se reduce considerablemente y se mantiene alrededor de 0.025, convirtiéndose en uno de los más destacados en esa sección del gráfico.
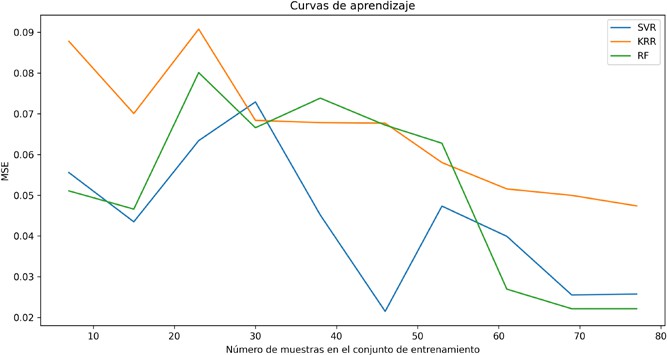 Figura 6
Curvas de aprendizaje de cada uno de los modelos empleados
Figura 6
Curvas de aprendizaje de cada uno de los modelos empleados
En la Figura 7, el gráfico de la izquierda (a) ilustra el MSE durante el entrenamiento. Se observa que el modelo RF sobresale, alcanzando el menor error con un valor de 0.0017638. Por otro lado, el modelo KRR presentó el MSE más elevado, aproximadamente 0.0116156, lo que sugiere que no se adaptó con la misma eficacia a los datos de entrenamiento. El modelo SVR se encontró en una posición intermedia, con un MSE aproximado de 0.0064449. El gráfico de la derecha (b) muestra un conjunto de resultados que se alinean con la métrica mencionada anteriormente. El modelo RF obtuvo el R2 más alto (95.38 %), lo que indica que este modelo es capaz de explicar una gran parte de la variación en los datos de entrenamiento. En contraste, el modelo KRR presentó el valor de R2 más bajo, cercano a 69.60 %, que señala menor habilidad para captar la varianza. Una vez más, el modelo SVR se situó en el medio, obteniendo un R2 de 83.13 %.
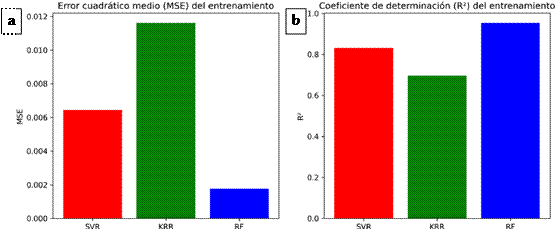 Figura 7
Métricas de evaluación para el análisis de los algoritmos empleados
Figura 7
Métricas de evaluación para el análisis de los algoritmos empleados
Evaluación
La Figura 8 muestra la conexión y las discrepancias entre un grupo de valores reales y aquellos que se obtienen de la ecuación Kuz-Ram, a lo largo de un índice de datos. Los valores reales, indicados con puntos grises, exhiben una disposición predominantemente horizontal. En contraste, los valores estimados por la ecuación, representados como puntos azules, normalmente siguen el mismo rumbo que los valores reales en la mayor parte de los puntos de datos, permaneciendo cerca del eje. No obstante, existe una marcada diferencia en algunos segmentos, particularmente entre los índices 30 y 40, donde la ecuación sugiere valores que son considerablemente más elevados que los reales, alcanzando máximos que exceden los 2500 e incluso sobrepasando los 3500. Esta discrepancia pone de relieve la limitación del modelo predictivo para entender la dinámica esencial en esos puntos concretos, aunque, en la mayoría del conjunto de datos, la ecuación parece ajustarse con notable precisión a los valores observados.
La Figura 9 presenta una comparación del desempeño de los tres algoritmos de aprendizaje automático en la predicción de valores frente a los valores reales. Se observa que los tres métodos de IA son capaces, en gran parte, de coincidir con los valores reales, lo que indica que han logrado identificar algunas pautas en los datos fundamentales. No obstante, se pueden notar variaciones en su capacidad de predicción; en ciertos segmentos del índice de datos, el modelo RF puede coincidir más estrechamente con los valores reales que los otros, mientras que, en otros, se aprecia una desviación más evidente. A medida que el índice de datos avanza, hay variaciones en la precisión, con cambios que muestran las particularidades y habilidades específicas de cada algoritmo para generalizar a partir de los datos utilizados en su entrenamiento.
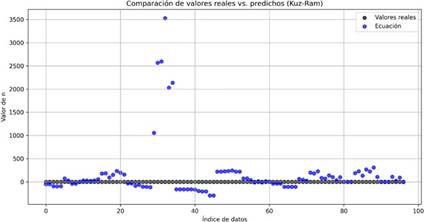 Figura 8
Comparativa entre los valores predichos por la ecuación Kuz-Ram y los valores reales
Figura 8
Comparativa entre los valores predichos por la ecuación Kuz-Ram y los valores reales
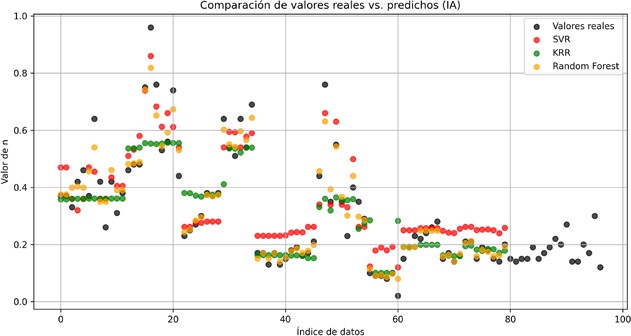 Figura 9
Comparativa entre los valores predichos por los modelos IA y los valores reales
Figura 9
Comparativa entre los valores predichos por los modelos IA y los valores reales
En la valoración de los modelos de IA, la capacidad de adaptación y la eficiencia en el uso de computadoras son aspectos fundamentales que muestran una narrativa compleja acerca del desempeño de RF, SVR y KRR. El modelo RF, similar a un camaleón digital, muestra una destacada habilidad para seguir el comportamiento de la variable objetivo, variando de forma significativa y, en numerosas ocasiones, aproximándose con una notable precisión a los valores reales del proceso de fragmentación. Esta capacidad de predicción, demostrada por su mínimo MSE durante el proceso de entrenamiento y un R2 que se aproxima a la perfección (cercano a 0.98), lo establece como un estándar en la comprensión de la complejidad de los datos, alcanzando un porcentaje de efectividad en el ajuste del 95 % o superior.
No obstante, esta habilidad para predecir implica un precio. Al examinar las métricas temporales, el modelo RF es el más lento en la etapa de predicción, exhibiendo tiempos de ejecución consistentemente más elevados que sus equivalentes SVR y KRR (superando 10−2 segundos en la mayoría de los tamaños de entrenamiento), además de mostrar un mayor tiempo de ajuste en ciertos intervalos. La característica fundamental del RF, que analiza un conjunto de árboles para efectuar cada predicción, conlleva una mayor necesidad de capacidad de procesamiento. En situaciones donde la respuesta inmediata es esencial, esto podría comprometer su funcionalidad práctica. Por lo tanto, RF hace que la predicción sea más comprensible al mostrar la realidad: su debilidad se encuentra en el tiempo que requiere para ofrecer sus pronósticos, un aspecto que no se puede ignorar en el ámbito de una aplicación práctica en minería.
Aplicación
El buen desempeño de nuestros modelos de IA ha sido transformado en una solución tangible: una aplicación de software desarrollada en Python y Visual Studio Code. Esta herramienta práctica para predecir la fragmentación de rocas ofrece una interfaz que logra, a través de un botón, conectar los modelos entrenados, previamente guardados y codificados en un archivo binario (.pkl), permitiendo que, al presionar el botón, el sistema decodifique este archivo, reconstruyendo el modelo en memoria para procesar los datos de entrada del usuario y realizar el cálculo eficiente del tamaño medio de fragmentación de la roca. La Figura 10 muestra la interfaz del usuario, que se estructura en tres vistas diferentes, cada una enfocada en un aspecto esencial del estudio de parámetros en voladura y la valoración de modelos de IA. Su diseño está concebido para promover la interacción con las personas, con el propósito de hacer más comprensible la complejidad de los datos y los algoritmos, proporcionando una visión de la mente que subyace a la fragmentación de la roca.
En la primera pantalla (a), denominada "Parámetros de Análisis", observamos un panel de control bastante accesible que facilita enormemente la introducción de datos para el usuario. Se tiene la posibilidad de cargar documentos que contienen información específica sobre perforación y voladura. Existen opciones como "Modo de Entrada", que aparenta señalar si la información es histórica o si corresponde a un diseño reciente, y "Opción", que sugiere una elección de diversos escenarios de análisis, siendo “Opción 1”, la relación de "Parámetros de Entrada" comprende variables esenciales tales como "S/B" (Relación Espaciamiento/Burden), "H/B" (Relación Altura de banco/Burden) , “B/D” (Relación Burden/Diámetro de agujero), "PF" (Factor de pólvora), "XB" (Tamaño de bloque) y "E" (Módulo de elasticidad) y “Opción 2” considerando las variables "B (m)" (Burden), "D (m)" (Diámetro de agujero), "S (m)" (Espaciamiento), "H" (Altura del banco), "T" (Taco inerte), "PF" (Factor de pólvora), "XB" (Tamaño de bloque) y "E" (Módulo de elasticidad). Esta parte se presenta como la introducción de la interfaz, el espacio donde el operador puede utilizar su comprensión del terreno y de la voladura en el sistema. Asimismo, en la esquina superior derecha, se encuentra una sección titulada “Parámetros de Entrada Utilizados”, que proporciona conceptos breves sobre cada variable, actuando como un glosario en el mismo lugar. Esto facilita la comprensión de la terminología técnica, permitiendo al usuario interactuar con mayor seguridad en el vocabulario del franqueo de roca. Los "Parámetros de Patrones" y "Radios de Influencia Conceptual" ofrecen un contexto adicional, definiendo las configuraciones habituales y las consecuencias espaciales de la voladura, lo cual refleja la realidad física de la mina.
La segunda sección (b), denominada "Visualizaciones", nos invita a descubrir el interesante ámbito de la comprensión espacial de los patrones de perforación. En este lugar, podemos observar dos diagramas esquemáticos: uno que representa un "Patrón Rectangular (S vs B)" y otro que representa un "Patrón Triangular (S vs B)". Estos gráficos, con radios de n metros, no solo ilustran la disposición geométrica de la malla de perforación, sino que también nos facilitan la comprensión de la "Influencia en Malla Rectangular" e "Influencia en Malla Triangular" mediante representaciones de la fragmentación conceptual. Esta parte es un claro ejemplo de cómo la interfaz funciona como un traductor visual: transforma cifras y conceptos en imágenes que un ingeniero puede entender y con las que puede interactuar en su mente. La habilidad de observar el impacto de la malla es fundamental, ya que permite al usuario entender rápidamente cómo la organización de los barrenos influye en la distribución de la energía explosiva y, por lo tanto, en la fragmentación. En este punto, la abstracción matemática se convierte en algo concreto.
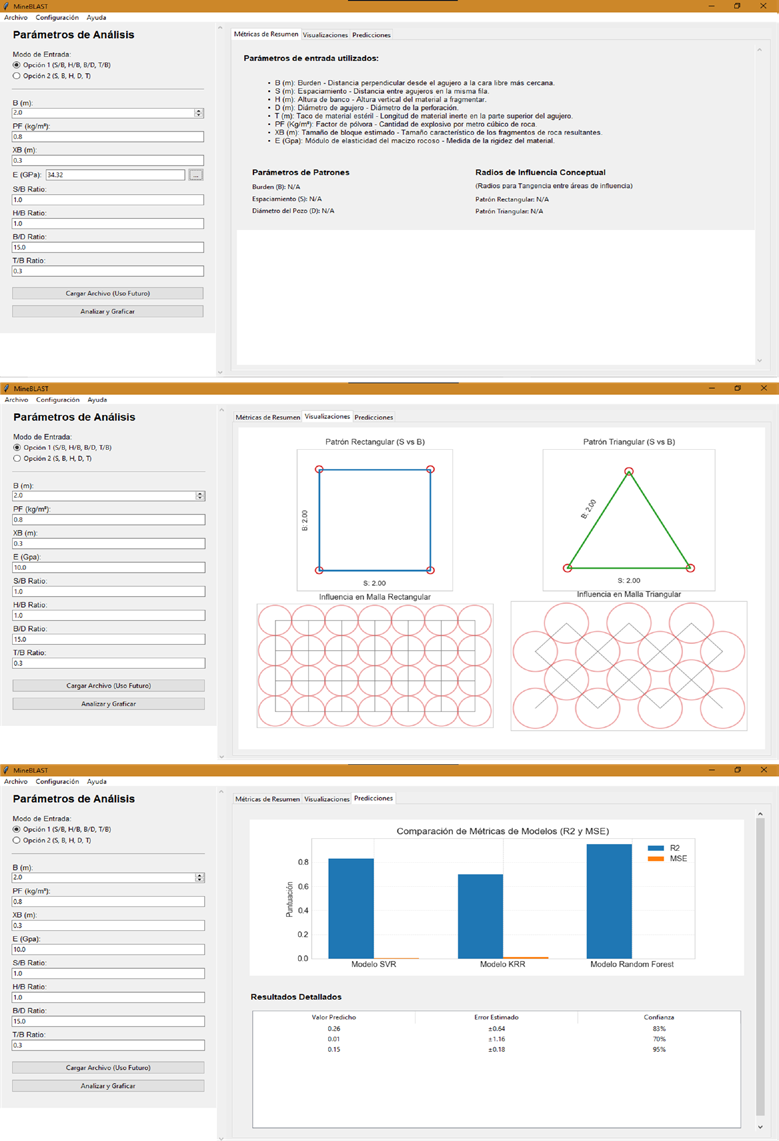 Figura 10
Interfaz gráfica de la aplicación y ejemplo de cálculo del tamaño medio de fragmentación
Figura 10
Interfaz gráfica de la aplicación y ejemplo de cálculo del tamaño medio de fragmentación
Interfaz gráfica de la aplicación y ejemplo de cálculo del tamaño medio de fragmentación Finalmente, la tercera vista (c), "Predicciones", representa el punto más importante del proceso de análisis, en el que los modelos de IA presentan sus conclusiones. A continuación, se muestra un gráfico de barras titulado "Comparación de Métricas de Modelos (R2 y MSE)", que resume el rendimiento de los modelos SVR, KRR y RF. En esta plataforma, los datos estadísticos se presentan de manera visualmente atractiva: el modelo RF se destaca como el mejor en R2, alcanzando aproximadamente 0.98, y exhibe un MSE notablemente bajo, lo que sugiere un ajuste casi ideal a los datos de entrenamiento. SVR presenta un R2 de aproximadamente 0.8, mientras que KRR se encuentra ligeramente rezagado. Este panel funciona como la decisión del jurado algorítmico, permitiendo al usuario reconocer de manera rápida qué modelo ha demostrado ser el más efectivo para predecir la fragmentación. Más adelante, la parte titulada "Resultados Detallados" proporciona un análisis más exhaustivo de las predicciones, exhibiendo "Valor Predicho" de P50, "Desviación Estimada" y "Confianza", lo que proporciona una dimensión adicional de interpretación y permite al usuario comprender el pronóstico.
Conclusiones
Este estudio ha demostrado la implementación de los algoritmos Random Forest (RF), Support Vector Regressor (SVR) y Kernel Ridge Regressor (KRR) para la predicción de la fragmentación óptima de la roca en minería, lo que mejora considerablemente la eficiencia operativa. Los resultados indican que RF superó a los demás en términos de precisión, logrando un error cuadrático medio bajo que ronda el 0.13 % y un valor R² cercano a los valores objetivo del conjunto de datos.
El mejor desempeño de los modelos de IA y su habilidad para capturar las complejas interrelaciones entre los parámetros de perforación y voladura (espaciamiento, burden, diámetro de agujero, altura de banco y taco de estéril), de la roca (módulo de elasticidad) y el tamaño medio de los fragmentos (P50), demuestran que son una alternativa más conveniente que el método de estimación convencional.
Los bajos valores de MSE obtenidos por los modelos de IA confirman que los factores geotécnicos y operativos son predictores válidos para la fragmentación de las rocas. Este hallazgo es relevante, ya que demuestra la capacidad de los modelos para manejar la variabilidad inherente a la composición litológica. Además, la matriz de correlación muestra conexiones significativas, como la relación inversa entre el factor de pólvora y la relación carga/diámetro, el módulo de elasticidad o el tamaño promedio de fragmentación (P50), indicando que un mayor uso de pólvora tiende a reducir estos valores.
Se resalta la importancia de contar con una aplicación que convierta resultados complicados de modelos de IA en información comprensible. Mostrar gráficos de fragmentación y previsiones, permite a los usuarios trabajar con datos, simular situaciones de voladura y modificar parámetros geotécnicos, asistiendo a estudiantes y profesionales sin necesitar conocimientos profundos en decisiones cotidianas en minería.
Si bien los modelos presentados han demostrado su eficacia, su rendimiento podría optimizarse al aumentar la calidad y la cantidad de los datos de entrenamiento. Aunque la recolección de datos asociados con el uso de explosivos es un desafío por la escasa accesibilidad y la alta sensibilidad, se sugieren indicadores clave de desempeño (KPI) del proceso de voladura, el precio del material (USD/Ton) y los gastos que conlleva extraerlo. Además, el resultado P50 se puede complementar con sus homólogos P20 y P80, permitiendo trazar una curva granulométrica aproximada.
Finalmente, los estudios futuros pueden identificar y caracterizar otros factores influyentes para la fragmentación (ej. RMR, Q de Barton) ligados al tipo de roca, lo cual es esencial para mejorar los diseños de voladuras, minimizar la incertidumbre y garantizar resultados fiables en las operaciones mineras.
Referencias
Amoako, R., Jha, A., & Zhong, S. (2022). Rock Fragmentation Prediction Using an Artificial Neural Network and Support Vector Regression Hybrid Approach. Mining, 2(2), 233–247. https://doi.org/10.3390/ mining2020013
Aryafar, A., Rahimdel, M. J., & Tavakkoli, E. (2020). Selection of the most proper drilling and blasting pattern by using madm methods (A case study: Sangan iron ore mine, iran). Rudarsko Geolosko Naftni Zbornik, 35(3), 97–108. https://doi.org/10.17794/rgn.2020.3.10
Bunga, A. P., Noguel, J. A. O., & Quesada, R. W. (2019). Predicción y evaluación de la granulometría de la pila de material obtenido en las voladuras en la mina Prediction and assessment of material gradation obtained through blasting in Polymetallic Castellano mine , Pinar del Río , Cuba. Ciencia & Futuro, 10(1), 37–49. https://doi.org/ISSN 2306-823X
Das, R. K., Dhekne, P. Y., & Murmu, S. (2023). Development of a Multiplication Factor for the Kuz-Ram Model to Match the Fragment Size Obtained from Wipfrag Image Analysis. Journal of Mines, Metals and Fuels, 71(12), 2414–2425. https://doi.org/10.18311/jmmf/2023/34116
de Castro, D. F. (2021). Comparative analysis of fragmentation models for undeground blasting. UNDERGROUND MINING ENGINEERING 39 (2021) 29-42 UNIVERSITY OF BELGRADE - FACULTY OF MINING AND GEOLOGYFACULTY OF MINING AND GEOLOGY, 39(39), 29–42. https://doi.org/10.5937/
Górriz, J. M., Álvarez-Illán, I., Álvarez-Marquina, A., Arco, J. E., Atzmueller, M., Ballarini, F., Barakova, E., Bologna, G., Bonomini, P., Castellanos-Dominguez, G., Castillo-Barnes, D., Cho, S. B., Contreras, R., Cuadra, J. M., Domínguez, E., Domínguez-Mateos, F., Duro, R. J., Elizondo, D., Fernández-Caballero, A., … Ferrández-Vicente, J. M. (2023). Computational approaches to Explainable Artificial Intelligence: Advances in theory, applications and trends. Information Fusion, 100(July), 101945. https://doi. org/10.1016/j.inffus.2023.101945
Guerrero-Rodriguez, B., Salvador-Meneses, J., Garcia-Rodriguez, J., & Mejia-Escobar, C. (2024). Improving Landslides Prediction: Meteorological Data Preprocessing Based on Supervised and Unsupervised Learning. Cybernetics and Systems, 55(6), 1332–1356. https://doi.org/10.1080/01969722.2023.2240647
Hasanipanah, M., Amnieh, H. B., Arab, H., & Zamzam, M. S. (2018). Feasibility of PSO–ANFIS model to estimate rock fragmentation produced by mine blasting. Neural Computing and Applications, 30, 1015–1024. https://doi.org/10.1007/s00521-016-2746-1
Hekmat, A., Munoz, S., & Gomez, R. (2019). Prediction of Rock Fragmentation Based on a Modified Kuz-Ram Model. En Proceedings of the 27th International Symposium on Mine Planning and Equipment Selection - MPES 2018 (pp. 69–79). Springer International Publishing. https://doi.org/10.1007/978-3-319-99220-4_6
Hu, J., Song, Z., Si, J., Cao, G., Nie, L., & Chen, A. (2023). Prediction of Rock Mass Parameters Based on PCA and Random Forest Method. Geotechnical and Geological Engineering, 41, 4629–4640. https://doi. org/10.1007/s10706-023-02536-z
Hudaverdi, T., Kulatilake, P. H. S. W., & Kuzu, C. (2006). Prediction of blast fragmentation using multivariate analysis procedures. International Journal for Numerical and Analytical Methods in Geomechanics, 30(13), 1303–1336. https://doi.org/https://doi.org/10.1002/nag.957
Kuznetsov, V. M. (1973). The mean diameter of fragments formed by blasting rock. Journal of Mining Science, 9(2), 144–148. https://link.springer.com/article/10.1007/BF02506177
Lawal, A. I. (2021). A new modification to the Kuz-Ram model using the fragment size predicted by image analysis. International Journal of Rock Mechanics and Mining Sciences, 138. https://doi.org/10.1016/j. ijrmms.2020.104595
Leng, Z., Fan, Y., Gao, Q., & Hu, Y. (2020). Evaluation and optimization of blasting approaches to reducing oversize boulders and toes in open-pit mine. International Journal of Mining Science and Technology, 30(3), 373–380. https://doi.org/10.1016/j.ijmst.2020.03.010
Li, E., Yang, F., Ren, M., Zhang, X., Zhou, J., & Khandelwal, M. (2021). Prediction of blasting mean fragment size using support vector regression combined with five optimization algorithms. Journal of Rock Mechanics and Geotechnical Engineering, 13(6), 1380–1397. https://doi.org/10.1016/j.jrmge.2021.07.013
Lin, S.-B. (2023). Adaptive Parameter Selection for Kernel Ridge Regression.
López, E., López, C., Ortiz, F., & Pernia, J. (2003). Manual de Perforación y Voladura de Rocas. En Ingeopress.
Miao, Y., Zhang, Y., Wu, D., Li, K., Yan, X., & Lin, J. (2021). Rock Fragmentation Size Distribution Prediction and Blasting Parameter Optimization Based on the Muck-Pile Model. En Mining, Metallurgy and Exploration (Vol. 38, pp. 1071–1080). Springer Science and Business Media Deutschland GmbH. https:// doi.org/10.1007/s42461-021-00384-0
Mwango, V. (2015). Optimization of Blasting Parameters-A case study of Nchanga Open Pits. INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH, 4(September 2015), 45–51. https://doi.org/ ISSN 2277-8616
Ohadi, B., Sun, X., Esmaieli, K., & Consens, M. P. (2020). Predicting blast-induced outcomes using random forest models of multi-year blasting data from an open pit mine. Bulletin of Engineering Geology and the Environment, 79(1), 329–343. https://doi.org/10.1007/s10064-019-01566-3
Rabbani, A., Samadi, H., Fissha, Y., Agarwal, S. P., Balsara, S., Rai, A., Kawamura, Y., & Sharma, S. (2024). A comprehensive study on the application of soft computing methods in predicting and evaluating rock fragmentation in an opencast mining. Earth Science Informatics, 17(6), 6019–6034. https://doi. org/10.1007/s12145-024-01488-z
Raj, A. K., Choudhary, B. S., & Deressa, G. W. (2024). Prediction of Rock Fragmentation for Surface Mine Blasting Through Machine Learning Techniques. Journal of The Institution of Engineers (India): Series D. https:// doi.org/10.1007/s40033-024-00812-7
Rojas Linares, E. L. (2018). Un nuevo enfoque predictivo de la fragmentación en la Voladura de Rocas. Industrial Data, 21(1), 17–26. https://doi.org/10.15381/idata.v21i1.14907
Rosales-Huamani, J. A., Perez-Alvarado, R. S., Rojas-Villanueva, U., & Castillo-Sequera, J. L. (2020). Design of a predictive model of rock breakage by blasting using artificial neural networks. Symmetry, 12(9), 1–17. https://doi.org/10.3390/SYM12091405
Saadoun, A., Boukarm, R., Fredj, M., Menacer, K., Boudjellal, D., Hafsaoui, A., & Yilmaz, I. (2024). Optimal Blast Design Considering the Effects of Geometric Blasting Parameters on Rock Fragmentation : A Case Study. In World Summit: Civil Engineering-Architecture-Urban Planning Congress, 1, 136–146. https:// doi.org/10.3897/ap.7.e0146
Shafl, A. (2024, octubre 1). Random Forest Classification with Scikit-Learn. datacamp. https://www.datacamp. com/tutorial/random-forests-classifier-python
Su, H., & Ma, S. (2022). Study on the stability of high and steep slopes under deep bench blasting vibration in open-
Vu, T., & Bao, T. (2021). Development of a predictive model of rock fragmentation for Nui Phao open-pit mine in Vietnam using multiple-output Neural Networks and Monte Carlo Dropout technique. ResearchSquare, 1, 1–14. https://doi.org/https://doi.org/10.21203/rs.3.rs-171960/v1
Wu, Z., Wu, Y., Weng, L., Li, M., Wang, Z., & Chu, Z. (2024). Machine learning approach to predicting the macro- mechanical properties of rock from the meso-mechanical parameters. Computers and Geotechnics, 166. https://doi.org/10.1016/j.compgeo.2023.105933
Xie, C., Nguyen, H., Bui, X. N., Choi, Y., Zhou, J., & Nguyen-Trang, T. (2021). Predicting rock size distribution in mine blasting using various novel soft computing models based on meta-heuristics and machine learning algorithms. Geoscience Frontiers, 12(3), 101108. https://doi.org/10.1016/j.gsf.2020.11.005
Yakovlev, V. L., Zharikov, S. N., Regotunov, A. S., & Kutuev, V. A. (2024). Methodological basis for adaptation of the drilling and blasting parameters to changing mining and geological conditions when mining complex-structured deposits. Mining Industry Journal (Gornay Promishlennost), 6, 89–97. https://doi. org/10.30686/1609-9192-2024-6-89-97
Yin, R., Liu, Y., Wang, W., & Meng, D. (2020). Sketch Kernel Ridge Regression Using Circulant Matrix: Algorithm and Theory. IEEE Transactions on Neural Networks and Learning Systems, 31, 3512–3524. https://doi. org/10.1109/TNNLS.2019.2944959
Zamora-Paredes, V., Arauzo-Gallardo, L., Raymundo-Ibanez, C., & Perez, M. (2020). Optimal mesh design methodology considering geometric parameters for rock fragmentation in open-pit mining in the Southern Andes of Peru. IOP Conference Series: Materials Science and Engineering, 758(1). https://doi. org/10.1088/1757-899X/758/1/012015
Zhang, R., Li, Y., & Gui, Y. (2023). Prediction of rock blasting induced air overpressure using a self-adaptive weighted kernel ridge regression. Applied Soft Computing, 148. https://doi.org/10.1016/j.asoc.2023.110851
Zhang, Y. L., Qin, Y. G., Armaghsni, D. J., Monjezi, M., & Zhou, J. (2024). Enhancing rock fragmentation prediction in mining operations: A Hybrid GWO-RF model with SHAP interpretability. Journal of Central South University, 31(8), 2916–2929. https://doi.org/10.1007/s11771-024-5699-z
Zhao, J., Li, D., Zhou, J., Armaghani, D. J., & Zhou, A. (2024). Performance evaluation of rock fragmentation prediction based on RF-BOA, AdaBoost-BOA, GBoost-BOA, and ERT-BOA hybrid models. Deep Underground Science and Engineering, 4, 3–17. https://doi.org/10.1002/dug2.12089




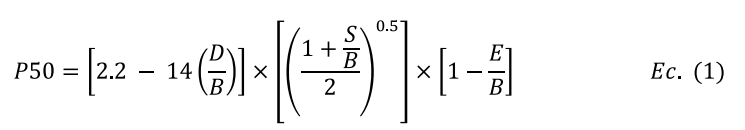 (1)
(1)

