Introducción
El suicidio constituye un problema crítico de salud pública que tiene como resultado la pérdida de aproximadamente 703.000 vidas anualmente, con un número significativamente mayor de personas que intentan llevarlo a cabo. Cada caso representa una tragedia que impacta de manera profunda a las familias, a las comunidades y a las naciones dejando una huella duradera en los seres queridos de las víctimas. Este fenómeno puede presentarse en cualquier etapa de la vida, y en el 2019, se consolidó como la cuarta causa de muerte entre jóvenes de 15 a 29 años en el mundo (Organización Mundial de la Salud, 2021).
El suicidio se define como un acto intencional mediante el cual una persona busca provocar su propia muerte a través de comportamientos autoinfligidos con la expectativa o intención de un desenlace fatal. Este fenómeno ha sido analizado desde múltiples perspectivas. Particularmente, desde el enfoque sociológico se considera una acción, ya sea positiva o negativa, ejecutada por el individuo con pleno conocimiento de sus consecuencias mortales (Blanco, 2020). Desde la perspectiva médica, el suicidio se interpreta como una respuesta a un malestar psicológico o emocional complejo, en el que la persona percibe esta acción como la mejor solución a sus problemas (Rangel-Villafaña y Jurado-Cárdenas, 2022).
Por otro lado, la conducta suicida comprende una amplia gama de comportamientos, que incluyen el suicidio consumado, el intento de suicidio y la ideación suicida. El suicidio consumado se refiere a un acto deliberado de autolesión que culmina en la muerte de la persona (Pastor et al., 2023). El intento de suicidio, por otra parte, implica un acto autolesivo donde la persona tiene la intención de causar su propia muerte, pero que no culmina en un desenlace fatal, aunque puede ocasionar lesiones de diversa gravedad (Mojica et al., 2023). La ideación suicida, en cambio, se manifiesta a través de pensamientos recurrentes, planes y preparativos orientados hacia el suicidio, lo que refleja un profundo nivel de angustia (Moutier, 2023).
Para identificar adecuadamente el riesgo de suicidio, es esencial realizar una evaluación exhaustiva de los factores de riesgo específicos de cada individuo. A medida que estos factores se acumulan, aumenta la probabilidad de que la persona desarrolle pensamientos o comportamientos suicidas. Sin embargo, es crucial recordar que incluso en ausencia de factores de riesgo evidentes no se puede descartar que la persona exhiba conductas suicidas en algún momento. Esto destaca la complejidad del fenómeno y la necesidad de un enfoque integral, personalizado en la evaluación y manejo del riesgo de suicidio (González, 2023).
En Bogotá, según el estudio de Rodríguez et al. (2023) sobre los resultados de la Encuesta Nacional de Salud Mental, se identificaron varios factores clave asociados con la conducta suicida. Entre los más destacados se encuentran la presencia de trastornos mentales, especialmente la depresión, y los rasgos de personalidad limítrofe. También se señalan factores sociodemográficos, como tener más de 45 años, estar desempleado, vivir solo, y tener antecedentes familiares de suicidio o intentos previos. Además, el consumo de alcohol y tabaco, la percepción negativa de la salud mental, y la experiencia de eventos vitales adversos fueron reconocidos como factores de riesgo significativos.
En los últimos años, el análisis de la conducta suicida ha sido abordado desde perspectivas estadísticas y computacionales con resultados prometedores. Cifuentes et al. (2024), por ejemplo, desarrollaron un modelo de pronóstico regional para los intentos de suicidio en la ciudad de Medellín, Antioquia. Los autores encontraron que el modelo paramétrico cúbico estacional con errores ARMA (0,5) ofreció los mejores resultados de pronóstico, presentando un margen de error del 12% en comparación con las observaciones reales. Este enfoque destaca el potencial de las técnicas avanzadas de modelado para mejorar la precisión en la predicción de conductas suicidas a nivel regional.
De manera complementaria, Guzmán y Gélvez (2024) utilizaron el algoritmo de Random Forest para identificar factores asociados a intentos suicidas, evidenciando su eficacia en la clasificación. No obstante, si bien Random Forest es robusto ante el sobreajuste y útil para interpretar la importancia de variables, su desempeño puede degradarse cuando se enfrenta a conjuntos de datos con fuerte desequilibrio de clases o cuando se requiere una optimización fina del error. En comparación, estudios recientes han demostrado que XGBoost (Extreme Gradient Boosting) supera a Random Forest en precisión y velocidad, especialmente en contextos donde los datos presentan ruido, valores atípicos o múltiples variables categóricas y continuas (Espinosa-Zúñiga, 2020; Imani et al., 2025).
Castillo-Zúñiga et al. (2022) aplicaron redes neuronales recurrentes para analizar expresiones de riesgo suicida en sitios web demostrando el potencial del procesamiento del lenguaje natural. No obstante, estos modelos requieren grandes volúmenes de datos etiquetados y capacidades computacionales considerables, lo que puede limitar su aplicabilidad en contextos institucionales con recursos limitados. De manera similar, estudios como el de Rodríguez-Esparza et al. (2021) integraron análisis de emociones y redes sociales, pero su enfoque es más exploratorio que predictivo, lo que reduce su utilidad para generar alertas tempranas a partir de datos institucionales. Además, se han aplicado algoritmos de conglomerado y redes neuronales artificiales para evaluar y predecir perfiles de adolescentes con intención suicida (Reyes-Ruiz et al., 2019).
En este contexto, el modelo XGBoost se presenta como una alternativa metodológica para la predicción de la conducta suicida. Su capacidad para manejar datos heterogéneos, su tolerancia al ruido, su efectividad en la detección de interacciones complejas entre variables, así como su rendimiento frente a modelos lineales y de árboles convencionales, lo convierten en una opción adecuada para contextos urbanos (Kumar et al., 2022). Además, su versatilidad ha sido validada en estudios recientes de salud mental y epidemiología (Ehtemam et al., 2024), en los que ha mostrado un desempeño destacado en la predicción de eventos raros o de baja frecuencia, como los intentos suicidas.
A partir de lo expuesto, se evidencia que, pese a los avances en la comprensión de la conducta suicida desde diferentes enfoques, aún persiste una brecha significativa en el uso de herramientas tecnológicas que permitan analizar y proyectar este fenómeno. La complejidad del suicidio, sumada a la multiplicidad de factores que lo rodean y a la variabilidad de su manifestación en el tiempo, dificulta la detección temprana de patrones clave para una intervención oportuna. Aunque algunas investigaciones han empleado modelos estadísticos y técnicas de aprendizaje automático, todavía se carece de enfoques que integren series temporales para el análisis predictivo de esta conducta. Esta carencia limita la capacidad de las instituciones locales para fundamentar sus decisiones en datos y desarrollar estrategias preventivas eficaces y contextualizadas.
Teniendo en cuenta lo anterior, el objetivo de este proyecto investigativo es analizar los datos sobre conducta suicida en la ciudad de Bogotá, Colombia, y predecir tendencias mediante series temporales utilizando algoritmos de machine learning. Para ello, se han recolectado y procesado datos históricos relacionados con casos de conducta suicida provenientes de diversas fuentes, con el fin de identificar patrones y tendencias a lo largo del tiempo.
Metodología
Para el proceso de análisis de datos, se emplea el método KDD (Knowledge Discovery in Databases), que estructura la minería de datos a través de una serie de etapas lineales definidas. Este método se basa en la extracción de patrones en forma de reglas o funciones a partir de los datos, lo que facilita su análisis para el usuario. El proceso generalmente implica el preprocesamiento de datos, la realización de la minería de datos y la presentación de los resultados obtenidos (Rodríguez et al., 2024).
Este método comprende varios pasos cruciales: la selección de datos, el preprocesamiento, la transformación, la minería de datos propiamente dicha, y la interpretación y evaluación de los resultados. La selección de datos implica identificar y elegir el subconjunto de datos relevante para el análisis. Durante el preprocesamiento, los datos se limpian y preparan para mejorar su calidad y manejabilidad. La transformación de datos convierte los datos en formatos adecuados para el análisis, como la normalización, agregación o generación de nuevas variables (Torres, 2021).
En la etapa de minería de datos, se aplican técnicas específicas, como algoritmos de clasificación, regresión o clustering, para extraer patrones y conocimientos valiosos. Finalmente, la interpretación y la evaluación de los resultados aseguran que los hallazgos sean precisos y útiles y que permitan la toma de decisiones informadas (Ramos-Serrano, 2021). Este enfoque sistemático permite extraer información significativa y accionable de grandes volúmenes de datos optimizando el proceso de descubrimiento de conocimiento en bases de datos (Sánchez et al., 2023).
Fase uno: selección de los datos
En esta etapa, se realiza la búsqueda y selección de conjuntos de datos relevantes sobre la temática en estudio publicados en bases de datos o repositorios de acceso abierto. Es fundamental asegurar que esta información esté debidamente anonimizada para evitar la identificación de las personas involucradas en los casos (Decreto 1743 de 2016). Además, se debe garantizar que los datos provengan de fuentes primarias (Guzmán, 2021) y que sean válidos, es decir, que cumplan con criterios de exactitud, estructura e integridad. La fiabilidad también es crucial, y se refiere a la coherencia y repetibilidad de las observaciones realizadas sobre los datos (IBM, 17 de enero de 2024).
Igualmente, la transparencia es fundamental para el desarrollo ético de los sistemas, ya que permite que desarrolladores, usuarios y personas afectadas comprendan su funcionamiento y eficacia. Para promover la participación pública, la información sobre el sistema debe presentarse de forma clara, accesible y comprensible (Guzmán y Gélvez, 2024). El estudio no involucró la recolección directa de datos personales ni intervenciones con seres humanos, por lo que no requirió consentimiento informado. Este trabajo se alinea con las directrices de la Declaración de Helsinki y con las normativas nacionales e institucionales vigentes para el uso ético de datos secundarios en investigaciones sociales y de salud pública. Las bases de datos de consulta así (ver tabla 1):
Tabla 1
Repositorios de datos abiertos
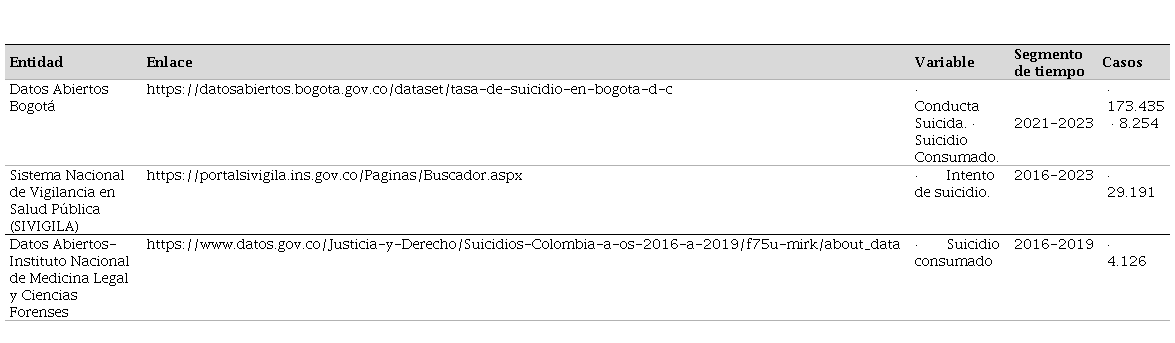 Nota. Información de los data set seleccionados.
Nota. Información de los data set seleccionados.
La selección de los datos se fundamentó en criterios de pertinencia temática, disponibilidad pública, cobertura temporal y calidad estructural de los registros. Se priorizaron fuentes oficiales y primarias generadoras del dato, tales como Datos Abiertos de Bogotá, el Sistema Nacional de Vigilancia en Salud Pública (SIVIGILA) y el Instituto Nacional de Medicina Legal y Ciencias Forenses, por su reconocimiento institucional, fiabilidad y actualización periódica. Estas fuentes contienen registros directos relacionados con conductas suicidas, intentos y suicidios consumados, lo que permite una cobertura integral del fenómeno.
Fase dos: preprocesamiento de los datos
Esta etapa implica un análisis exhaustivo del conjunto de datos seleccionado en la fase anterior. Aquí se aplican operaciones y técnicas necesarias para eliminar ruido, inconsistencias o redundancias presentes en los datos. El objetivo principal de esta fase es preparar los datos para la posterior aplicación de algoritmos asegurando su calidad y coherencia (Calvache-Fernández et al., 2018).
Esta tarea se realiza utilizando Python y librerías como Pandas, NumPy, Matplotlib y Plotly. Estas herramientas permiten la depuración y visualización de datos de manera eficiente. En esta fase, se examinan los tipos de datos, se eliminan las columnas irrelevantes, y se identifican y eliminan los datos nulos, así como aquellos que generan ruido. Además, se definen y determinan los tipos de errores, se buscan e identifican las instancias con errores y se corrigen (García-González et al., 2019).
Fase tres: transformación de los datos
En esta etapa, se compila la información sobre ideación suicida en un único conjunto de datos proveniente de diversas fuentes. Las transformaciones suelen implicar modificaciones sintácticas. Además, se reduce el tamaño del conjunto de datos identificando las características más significativas en función del objetivo del análisis. Se pueden aplicar métodos de transformación para disminuir el número de variables consideradas o para encontrar representaciones alternativas de los datos (Orozco et al., 2021).
Resultados
Fase cuatro: minería de datos
En la etapa de modelado, se emplean métodos avanzados para descubrir patrones ocultos en los datos que sean válidos, novedosos, potencialmente útiles y comprensibles (Joyanes, 2019). Para ello, se realiza un estudio descriptivo que permite conocer y visualizar el comportamiento del fenómeno.
Intento de suicidio
Durante el período de monitoreo, que abarca desde el 2016 —cuando se comenzó a observar el comportamiento de la intención suicida en Colombia mediante el Sistema Nacional de Vigilancia en Salud Pública (SIVIGILA)— hasta el 2023 —el último año de actualización—, se han registrado en Bogotá un total de 29.191 casos. Los años con el mayor número de casos son el 2023, con un 20.7%, seguido por el 2022 con un 19.6%, el 2021 con un 15.6%, el 2020 con un 10.4%, el 2016 con un 9.8%, el 2017 con un 8.1%, el 2018 con un 7.9%, y el 2019 con un 7.5%. Esta estadística revela una tendencia creciente en la incidencia del fenómeno en los últimos años. Además, en el 2023 se reportan aproximadamente 16.5 casos diarios en la capital del país, datos que se exponen así (ver figura 1):
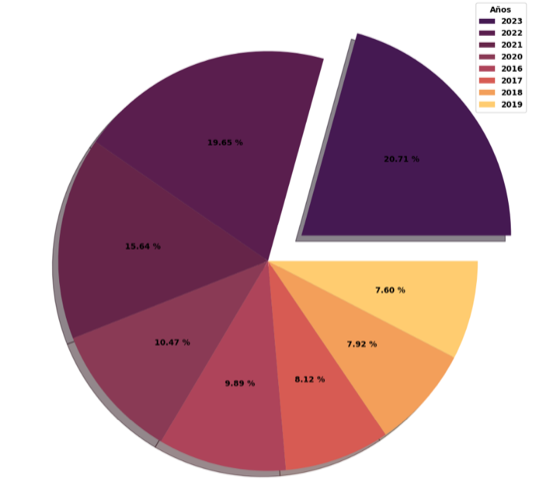 Figura 1
Comportamiento de los casos de intento de suicidio a lo largo de los años (2016-2023)
Nota. La gráfica muestra el porcentaje de casos de intento de suicidio a lo largo de los años.
Figura 1
Comportamiento de los casos de intento de suicidio a lo largo de los años (2016-2023)
Nota. La gráfica muestra el porcentaje de casos de intento de suicidio a lo largo de los años.
En cuanto al género, las mujeres representan el 64.9% de los intentos de suicidio, mientras que los hombres constituyen el 35.1%. En términos de nacionalidad, el 97% de los casos corresponden a ciudadanos colombianos, seguidos por un 2% de venezolanos, un 0.01% de brasileños y un 0.004% de personas provenientes de España, Estados Unidos, Francia y Nicaragua. En relación con la edad, los casos se clasifican por etapas de desarrollo, mostrando que la juventud presenta el mayor número de casos (9,954), seguida por la adultez (9,566), la adolescencia (8,522), las personas mayores (672), la infancia (468) y la primera infancia (9), estudio que se muestra a continuación (ver figura 2):
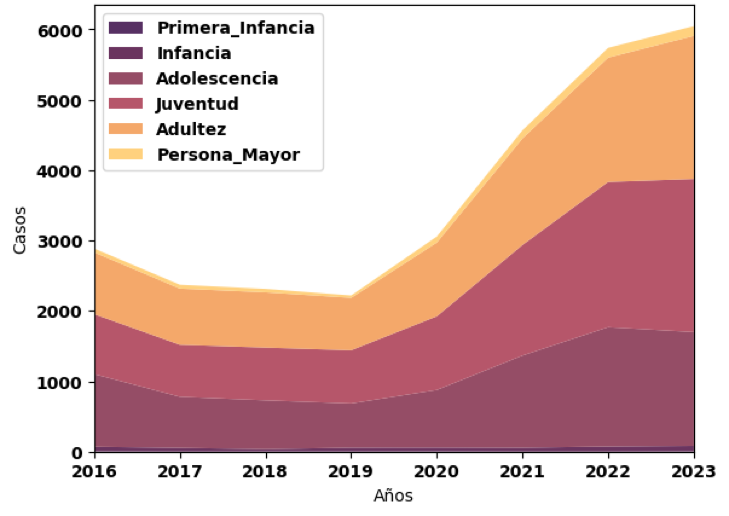 Figura 2
Casos de intento de suicidio en relación con las etapas del desarrollo
Nota. Los casos se clasifican de acuerdo con las siguientes etapas del desarrollo humano: primera infancia (0-5 años), infancia (6-11 años), adolescencia (12-18 años), juventud (19-26 años), adultez (27-59 años) y personas mayores (60 años y más).
Figura 2
Casos de intento de suicidio en relación con las etapas del desarrollo
Nota. Los casos se clasifican de acuerdo con las siguientes etapas del desarrollo humano: primera infancia (0-5 años), infancia (6-11 años), adolescencia (12-18 años), juventud (19-26 años), adultez (27-59 años) y personas mayores (60 años y más).
En cuanto a la ubicación de los intentos de suicidio, el 99.4% se registraron en cabeceras municipales, el 0.3% en centros poblados y el 0.2% en áreas rurales dispersas. En relación con el régimen de salud, el 72% de los casos pertenecen al régimen contributivo, el 19% al régimen subsidiado y el 8.6% a otros tipos de regímenes. En términos de ocupación, las personas dedicadas a actividades domésticas representan el mayor número de casos, con un 35.6%, seguidas por trabajadores de servicios de protección (15.3%), estudiantes (12.6%), jubilados (10.7%) y ocupaciones no especificadas (8.3%), entre otras.
En cuanto a la hospitalización, el 67.4% de los pacientes fueron ingresados, mientras que el 32.5% recibieron atención y fueron enviados a sus hogares. Respecto de las unidades primarias generadoras de datos (UPGD) que han reportado el mayor número de casos durante el período estudiado, el USS Simón Bolívar Subred Norte ESE ocupa el primer lugar, con el 5.6% de los casos, seguido por la Clínica Universitaria Colombia-Teusaquillo con un 4.5% y por el Hospital Universitario San Ignacio con un 4.2%, entre otros. Cabe aclarar que todos los casos son registrados por una entidad clínica.
Ideación suicida
En relación con la ideación suicida, la Secretaría Distrital de Salud ha registrado datos desde el 2012 hasta el 2023, reportándolos de manera general. Durante este período, se identificaron 120.822 casos de ideación suicida. El análisis revela una tendencia ascendente, alcanzando su punto máximo en el 2023 con un 23.2% de los casos. Las proporciones para los años anteriores son las siguientes: 2022 con un 20.3%, 2021 con un 12.6%, 2020 con un 8.4%, 2019 con un 8.7%, 2018 con un 6.9%, 2017 con un 4.4%, 2016 con un 4.1%, 2015 con un 3.9%, 2014 con un 3.3%, 2013 con un 2.3% y 2012 con un 1.3%. Estos datos se representan en la figura 3:
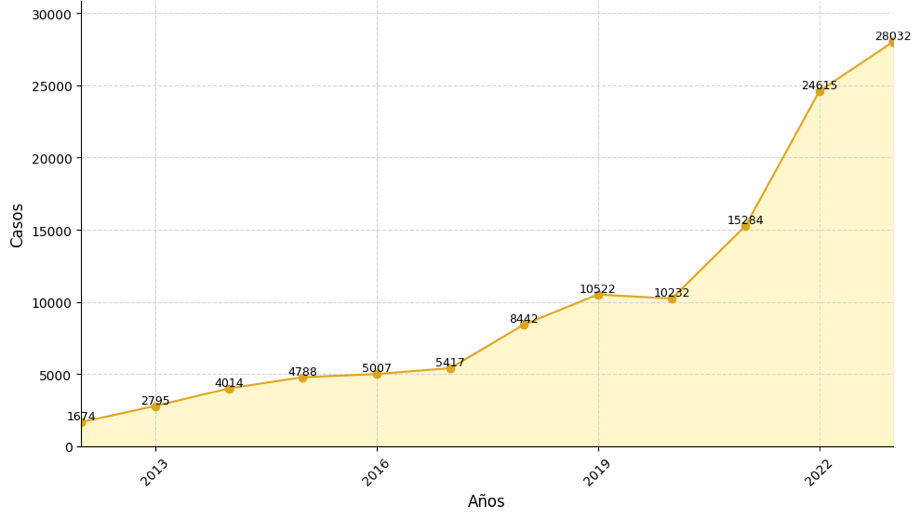 Figura 3
Casos de ideación suicida en el transcurso de los años (2012-2023)
Figura 3
Casos de ideación suicida en el transcurso de los años (2012-2023)
Con respecto a la etapa del desarrollo más afectada por el fenómeno de la ideación suicida, se observa que la adolescencia repunta con un 36.4%, seguida por la juventud, con el 27.1%; la adultez, con el 23.1%; la infancia, con el 9.8%; las personas mayores, con el 3.2%; y la primera infancia, con el 0.2%. Asimismo, las localidades con mayor número de casos registrados son Kennedy, con un 13.5%; Bosa, con un 11.6%; Suba, con 11.2%; Ciudad Bolívar, con un 10.5%; y Engativá, con un 8.9%.
Casos de suicidio
Entre el 2012 y el 2023, se registraron un total de 4.126 casos de suicidio consumado. Este fenómeno mostró un incremento notable en los años 2022 (10,3%), 2023 (10,1%), 2019 (10,0%), 2018 (9,3%) y 2021 (9,0%). La tasa promedio durante este período fue de 5.0 por cada 100.000 habitantes. Las localidades más afectadas fueron Kennedy (11,9%), Suba (11,1%), Ciudad Bolívar (10,2%), Engativá (9,3%) y Usaquén (8,7%). Estos datos se representan en el siguiente mapa (ver figura 4):
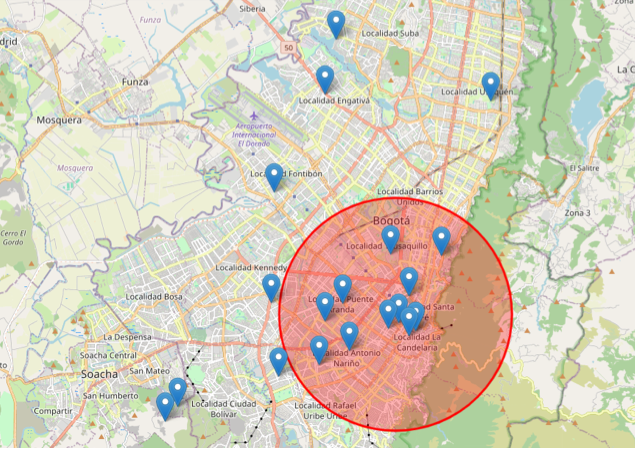 Figura 4
Casos reportados de suicidio consumado por localidades
Nota. Mapa de la ciudad de Bogotá que muestra la ubicación con la mayor concentración de casos de suicidio.
Figura 4
Casos reportados de suicidio consumado por localidades
Nota. Mapa de la ciudad de Bogotá que muestra la ubicación con la mayor concentración de casos de suicidio.
Para determinar el género más afectado por los suicidios, se realizó un análisis de los casos entre el 2016 y el 2019. Los resultados indican que los hombres presentan una mayor letalidad, con un 77.3%, en comparación con las mujeres, que registran un 22.6%. En cuanto a la distribución de casos por días de la semana, los sábados muestran la mayor incidencia con un 13.4%, seguidos por los miércoles (12.3%) y los domingos (9.5%). En relación con los meses, marzo presenta el mayor número de casos, con un 5.5%; seguido por febrero, con un 4.9%; y por octubre, con un 4.7%.
Fase cinco: modelado de datos
Análisis predictivo mediante series temporales con algoritmos de machine learning
Para el análisis predictivo, se utilizan cuatro algoritmos de machine learning con el propósito de desarrollar proyecciones sobre la evolución de los casos de intento de suicidio en los próximos dos años. Es así como se desarrolla un análisis descriptivo de los datos, en el que se aplica la prueba Dickey-Fuller (ADF), la cual permite verificar la estacionalidad en una serie de tiempo (Quinde-Rosales et al., 2019). El análisis arroja como resultado que el p-valor es de 0.04; como este valor está por debajo del umbral comúnmente usado, de 0.05, se considera que hay suficiente evidencia para afirmar que la serie es estacionaria.
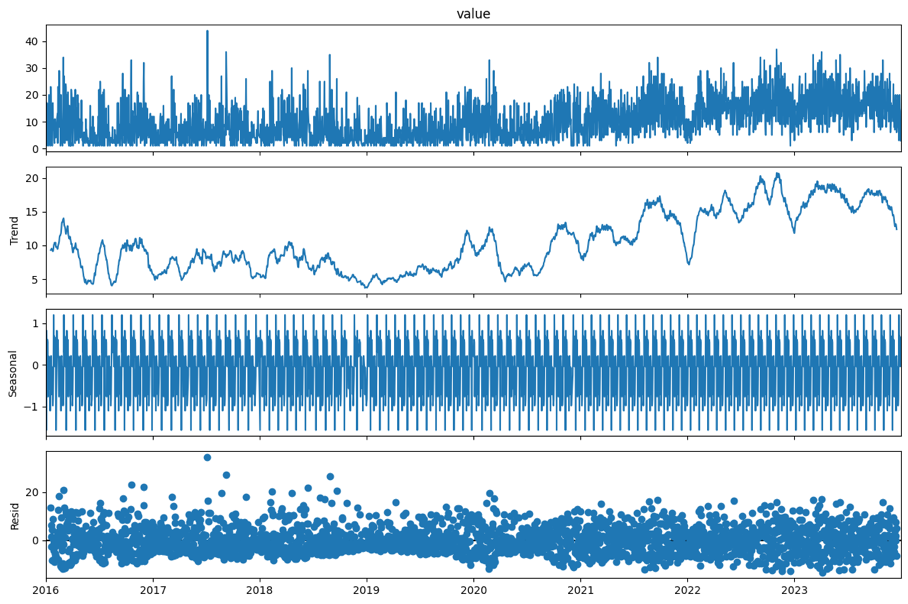 Figura 5
Descomposición estacional de los datos
Figura 5
Descomposición estacional de los datos
Nota. Se empleó un modelo de descomposición aditivo. Periodicidad de la estacionalidad mensual. Se muestra una tendencia ligeramente creciente. Se reflejan patrones recurrentes de variación a lo largo del tiempo. Los residuos están dispersos alrededor de cero, lo que sugiere que el modelo de descomposición captura adecuadamente las principales componentes de la serie.
Se empleó el modelo de suavización exponencial Holt-Winters, una extensión avanzada de la técnica de suavización exponencial que, a diferencia de la suavización exponencial tradicional, proporciona una visión general de las tendencias a largo plazo y permite realizar pronósticos a corto plazo. Además, amplía estas funciones posibilitando la proyección de tendencias futuras tanto a mediano como a largo plazo (Mira-Segura et al., 2018).
El algoritmo de redes neuronales LSTM es un modelo particularmente adecuado para procesar y predecir eventos significativos en series de tiempo con intervalos muy largos, ya que está diseñado para mitigar el problema de la dependencia a largo plazo. En este contexto, la información proporcionada en un momento anterior puede ser crucial para las predicciones o la generación de resultados (Suárez-Castro y Ladino-Vega, 2023). Para abordar este desafío, se incorpora un mecanismo de puertas que regula la transmisión de información entre las neuronas dentro de una red neuronal recurrente. Estas puertas determinan si las transformaciones realizadas y la información generada en cada neurona se integran en los datos que se transfieren a las neuronas subsiguientes en la red (Mosquera-Ruiz, 2023).
Igualmente, se desarrolla la práctica con el algoritmo de XGBoost (Extreme Gradient Boosting), un algoritmo de aprendizaje automático basado en árboles de decisión que utiliza un marco de potenciación de gradientes. Como una implementación avanzada del algoritmo de refuerzo de gradiente, el XGBoost ha demostrado ser altamente eficaz y es ampliamente utilizado en competiciones de aprendizaje automático. Su capacidad predictiva es notablemente superior, siendo casi diez veces más rápido que otras técnicas de gradient boosting. Además, incorpora diversas técnicas de regularización que reducen el sobreajuste y mejoran el rendimiento general gracias a lo cual se le reconoce como una técnica de refuerzo regularizado (Reyes et al., 2022).
Por último, se estructura la aplicación del algoritmo Random Forest, un algoritmo de clasificación ampliamente utilizado por científicos de datos. Este método combina múltiples árboles de decisión; cada árbol se construye a partir de un vector aleatorio que se genera de manera independiente y sigue la misma distribución para cada árbol. Aunque se basa en el concepto de árboles de decisión, mejora la precisión en la clasificación al introducir aleatoriedad en la construcción de cada clasificador individual (Urbina et al., 2019).
Tabla 2
Resultados de evaluación de los algoritmos
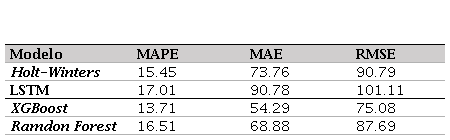 Nota. Evaluación del comportamiento de cada modelo en razón de los datos.
Nota. Evaluación del comportamiento de cada modelo en razón de los datos.
| Modelo | MAPE | MAE | RMSE |
| Holt-Winters | 15.45 | 73.76 | 90.79 |
| LSTM | 17.01 | 90.78 | 101.11 |
| XGBoost | 13.71 | 54.29 | 75.08 |
| Ramdon Forest | 16.51 | 68.88 | 87.69 |
La configuración de los modelos de predicción se realizó considerando tanto las características de la serie temporal como las capacidades particulares de cada algoritmo. En el caso del modelo Holt-Winters, se optó por una descomposición aditiva con estacionalidad mensual, ya que los datos mostraron una tendencia creciente y patrones estacionales regulares. Este modelo no requiere una gran cantidad de parámetros, pero sí la especificación clara del tipo de estacionalidad y el número de períodos. Para el modelo LSTM, se utilizó una arquitectura estándar con capas recurrentes capaces de capturar dependencias a largo plazo. Se emplearon configuraciones comunes con dos capas, funciones de activación tipo relu, tasa de aprendizaje de 0.001, optimizador Adam, y tamaño de batch de 32, ajustados según el comportamiento de la curva de pérdida en el entrenamiento.
En cuanto a los modelos basados en árboles, Random Forest se aplicó con una configuración por defecto ajustada al conjunto de datos, considerando alrededor de 100 estimadores (n_estimators), profundidad máxima de 10 (max_depth), y selección aleatoria de subconjuntos de características en cada división (max_features='sqrt'), lo que permite mitigar el sobreajuste y mejorar la robustez del modelo. Finalmente, se implementó el algoritmo XGBoost por su reconocido rendimiento en tareas de predicción con series temporales y conjuntos de datos complejos. Este modelo, basado en el método de potenciación de gradientes, permite un alto nivel de precisión al optimizar iterativamente la reducción del error en cada árbol. Además, incorpora mecanismos de regularización que lo hacen ideal frente al sobreajuste y eficiente en contextos con alta dimensionalidad.
En la evaluación del desempeño de los modelos empleados para proyectar el comportamiento de los intentos de suicidio a través de series de tiempo, se observó que el modelo XGBoost presentó los mejores resultados, destacándose con el menor error absoluto medio (MAE), error cuadrático medio (RMSE) y porcentaje de error medio absoluto (MAPE), lo que lo posiciona como un modelo preciso y confiable para esta tarea.
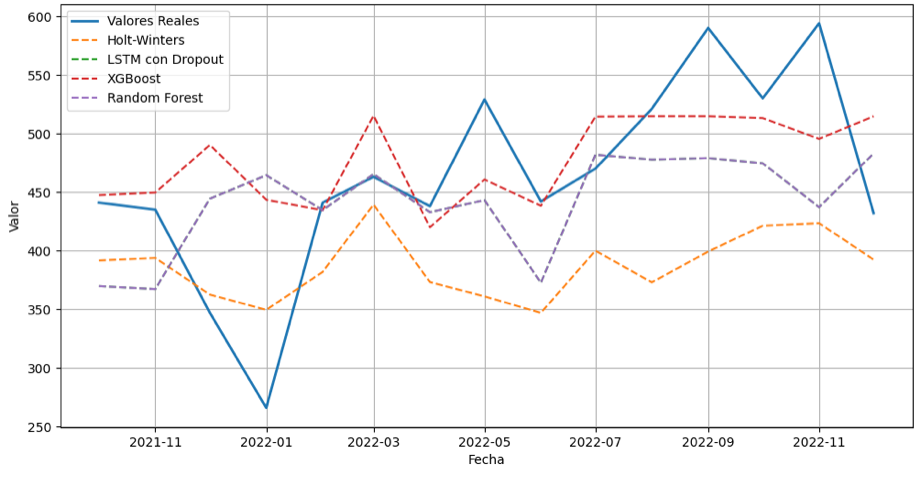 Figura 6
Comparación de predicciones de los modelos
Nota. La línea azul representa los datos reales, mientras que las líneas punteadas muestran el comportamiento de las predicciones de cada modelo.
Figura 6
Comparación de predicciones de los modelos
Nota. La línea azul representa los datos reales, mientras que las líneas punteadas muestran el comportamiento de las predicciones de cada modelo.
Para este análisis, se seleccionó el modelo XGBoost (Extreme Gradient Boosting) debido a su superior rendimiento en relación con los datos estudiados. El algoritmo, según Espinosa-Zúñiga (2020), sigue la siguiente estructura:
Generación del árbol inicial. Se construye un árbol inicial f0 para predecir la variable objetivo y, cuyo resultado se relaciona con un residuo (y - F0)
Ajuste del error. Se genera un nuevo árbol h1 que se ajusta al error cometido en el paso anterior.
Combinación de resultados. Los resultados de F0 y h1 se combinan para formar el árbol F1, en el cual el error cuadrático medio es menor que el de F0:
F1 (x) - F0(x) + h1 (x)
Iteración continua. Este proceso se repite iterativamente hasta que el error es minimizado al máximo posible, siguiendo la relación:
Fm(x) - Fm-1 (x) + hm (x)
Es importante aclarar que Fm(x) representa la predicción del modelo después de m iteraciones, mientras que hm(x) es el nuevo árbol que se ajusta a los residuos obtenidos en la iteración m.
Fase seis: interpretación y evaluación del modelo
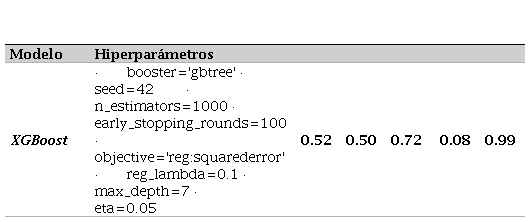
Al realizar el análisis mediante el modelo XGBoost y realizar el ajuste de hiperparámetros para llegar a los resultados óptimos, se encuentra una mejoría en las métricas de evaluación, tal como se observa en la tabla 3:
Tabla 3
Ajuste de los hiperparámetros del modelo XGBoost
 Nota. Evaluación del modelo al realizar los ajustes pertinentes.
Nota. Evaluación del modelo al realizar los ajustes pertinentes.
| Modelo | Hiperparámetros | | | | | |
| XGBoost | · booster='gbtree' · seed=42 · n_estimators=1000 · early_stopping_rounds=100 · objective='reg:squarederror' · reg_lambda=0.1 · max_depth=7 · eta=0.05 | 0.52 | 0.50 | 0.72 | 0.08 | 0.99 |
Después del reentrenamiento con 29.191 registros, el modelo muestra un ajuste robusto a las variaciones en los datos, lo que permite prever los intentos de suicidio que podrían ocurrir en los próximos dos años (2024 y 2025). Según las predicciones, se anticipa un aumento en los casos para el 2024, con un incremento del 1.31% respecto de los registros de 2023 (6.046 casos). Para el 2025, se proyecta un incremento adicional del 0.96% en comparación con los datos históricos. En la figura 7 se presentan las estimaciones:
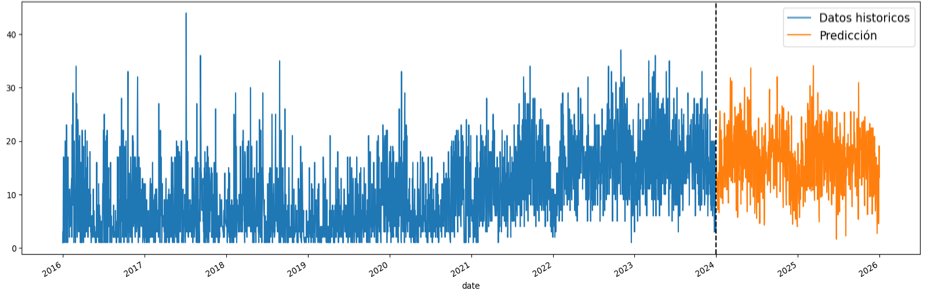 Figura 7
Estimaciones de intentos de suicidio según el modelo entrenado.
Nota. Gráfica estructurada según el código de Lee (10 de abril de 2023). En esta se presenta las proyecciones generadas por el modelo entrenado para los años 2025-2026.
Figura 7
Estimaciones de intentos de suicidio según el modelo entrenado.
Nota. Gráfica estructurada según el código de Lee (10 de abril de 2023). En esta se presenta las proyecciones generadas por el modelo entrenado para los años 2025-2026.
Discusiones
Los resultados del análisis de los casos de intento de suicidio muestran una tendencia creciente, especialmente en los últimos cuatro años, con un aumento notable en la etapa de desarrollo juvenil. Esta tendencia es respaldada por el estudio de Restrepo-Tobón et al. (2023), quienes identifican que el rango de edad más afectado por este fenómeno es el de los 17 a los 26 años. Además, el estudio destaca que los problemas afectivos y socioeconómicos son factores asociados significativos.
En cuanto a la ocupación, se observa que las personas dedicadas a actividades domésticas representan el mayor número de casos de intento de suicidio, seguidas por trabajadores de servicios de protección, estudiantes y jubilados, entre otros. Sin embargo, Vigoya-Rubiano et al. (2019) indican que la categoría de agricultor es la más frecuente en los registros, seguida por la de trabajador forestal, ambas predominantemente ocupadas por hombres. En contraste, las ocupaciones asociadas tradicionalmente a las mujeres, como auxiliar de enfermería, enfermera y vendedora, han mostrado un mayor número de intentos de suicidio.
En términos de género, los resultados muestran que las mujeres constituyen el 64.9% de los intentos de suicidio, frente al 35.1% de los hombres. Este patrón ha sido documentado por Salcedo et al. (2019) y Quemba et al. (2022), quienes, en sus estudios sobre intentos de suicidio en jóvenes, identifican factores asociados, como el ser mujer y residir en la cabecera municipal. Además, los estudios revelan una tendencia creciente en el número de casos a lo largo de los años, indicando un aumento en la incidencia de intentos de suicidio en esta población.
El análisis de la ideación suicida muestra una tendencia al alza, culminando en el 2023 con un 23.2% de los casos reportados. Las tasas de incidencia en los años anteriores reflejan un aumento progresivo: 20.3% en el 2022, 12.6% en el 2021, y 8.4% en el 2020. Estos datos indican un crecimiento sostenido en la prevalencia de ideación suicida durante el periodo analizado, lo que sugiere la necesidad de una mayor atención y de más recursos para abordar esta problemática emergente.
Por otro lado, Zamora (2023) indica que la ideación suicida continúa siendo un fenómeno complejo influenciado por múltiples factores, y que las tasas de suicidio están en ascenso a nivel global, especialmente entre los jóvenes. En particular, los datos revelan que, entre los pacientes hospitalizados con ideación suicida, el 13.4% tenía un plan suicida concreto, y el 10.6% había realizado intentos previos. Además, se observó que las mujeres tenían una mayor probabilidad de hospitalización en comparación con los hombres, lo que resalta la necesidad de considerar las diferencias de género en la prevención y el tratamiento de este grave problema de salud mental (Malleza et al., 2024).
En cuanto a las etapas del desarrollo afectadas por la ideación suicida, la adolescencia muestra la mayor incidencia, seguida por la juventud y la adultez. Estos hallazgos concuerdan con el estudio de Benavides-Mora et al. (2019), que reporta variaciones significativas en la prevalencia del riesgo suicida según el grupo poblacional. En adolescentes, la prevalencia es del 16.5%, mientras que en estudiantes universitarios es del 13.5%. En pacientes de consulta externa, la tasa se eleva al 39%, y entre mujeres privadas de libertad, se sitúa en un 14.4%. Estos datos subrayan la importancia de enfoques específicos para cada grupo demográfico en la prevención del suicidio.
Durante el período analizado, la tasa promedio de suicidios fue de 5.0 por cada 100.000 habitantes. Los datos indican que los hombres presentan una mayor letalidad en comparación con las mujeres, una tendencia corroborada por el estudio de Castro-Moreno et al. (2023). Este estudio identifica el ser varón, adulto y padecer una enfermedad crónica o un trastorno depresivo como factores de riesgo significativos para el suicidio. Estos hallazgos subrayan la necesidad de intervenciones específicas dirigidas a estos grupos de alto riesgo para mitigar la incidencia de suicidios.
En la evaluación del desempeño de los modelos utilizados para predecir los intentos de suicidio mediante series temporales, el modelo XGBoost destacó por obtener los mejores resultados. De acuerdo con Xu et al. (2024), este método de aprendizaje automático es especialmente confiable para el análisis de datos multimodales y la predicción de la autolesión en adultos jóvenes. La eficacia del XGBoost se ve significativamente mejorada al incorporar factores sociodemográficos, características de personalidad y variables genéticas en el análisis, lo que lo convierte en una importante herramienta para la prevención y el manejo del riesgo suicida (Park y Lee, 2022).
Los resultados del estudio pueden ser utilizados para desarrollar sistemas de monitoreo que permitan anticipar incrementos en los intentos de suicidio facilitando intervenciones preventivas en momentos y zonas de mayor riesgo. Los modelos predictivos aplicados, especialmente el XGBoost, pueden integrarse a programas de salud pública como herramientas de alerta temprana, apoyando la planificación y distribución de recursos. Además, estos hallazgos pueden servir como base para investigaciones futuras orientadas a incorporar nuevas variables, como factores psicológicos, sociales o ambientales, y explorar el uso de datos no estructurados, como los provenientes de redes sociales. También se plantea la posibilidad de adaptar estos modelos a otras regiones o poblaciones con características distintas, ampliando su aplicabilidad en contextos diversos.
Conclusiones
El análisis de los datos sobre conducta suicida en Bogotá, Colombia, desde el 2016 hasta el 2023, revela una tendencia creciente en la incidencia de intentos de suicidio. Durante este período, los casos han aumentado de manera significativa, lo que destaca la necesidad urgente de intervenciones de salud pública efectivas. La mayor parte de los intentos de suicidio se registran en áreas urbanas, con una prevalencia notable entre mujeres, especialmente en jóvenes y adultos. Estos hallazgos apuntan a la importancia de enfoques específicos en la prevención del suicidio, enfocados en los grupos más vulnerables y en el contexto urbano.
En términos de salud y ocupación, la mayoría de los casos de conducta suicida en Bogotá están asociados al régimen contributivo de salud y se concentran en personas dedicadas a actividades domésticas, trabajadores de servicios de protección y estudiantes. La hospitalización es frecuente, con un número significativo de pacientes que requieren atención médica. Los datos revelan una concentración de casos en ciertos centros clínicos, lo que sugiere que los esfuerzos preventivos futuros podrían beneficiarse de un enfoque más dirigido hacia estas áreas clave y grupos ocupacionales.
Entre el 2012 y el 2023, se registraron un total de 120.822 casos de ideación suicida en Bogotá, lo cual muestra una tendencia ascendente a lo largo de los años. En el 2023 se reportó el mayor número de casos, lo que refleja un incremento progresivo desde el 2012 y señala una preocupante proliferación de la ideación suicida en la ciudad. El análisis por etapas de desarrollo revela que la adolescencia es el grupo más afectado, seguido por la juventud y la adultez. Además, se observa una concentración significativa de casos en localidades específicas como Kennedy, Bosa, Suba, Ciudad Bolívar y Engativá, lo que sugiere la necesidad de enfoques preventivos focalizados en estas áreas.
Entre el 2012 y el 2023, se reportó un total de 4.126 casos de suicidio consumado en Bogotá. Durante este período, se observó un incremento significativo en el 2022 y en el 2023, así como en el 2019, en el 2018 y en el 2021. La tasa promedio de suicidios consumados fue de 5.0 por cada 100.000 habitantes, lo que permite advertir que existe un desafío persistente en la salud pública de la ciudad. Las localidades más afectadas fueron Kennedy, Suba, Ciudad Bolívar, Engativá y Usaquén; esto sugiere la necesidad de intervenciones focalizadas en estas áreas para abordar el problema de manera efectiva.
El análisis de los datos de suicidio consumado entre el 2016 y el 2019 revela que los hombres presentan una mayor tasa de letalidad en comparación con las mujeres. Además, se identificó una mayor incidencia de suicidios los días sábado, miércoles y domingo, con el mes de marzo registrando el mayor número de casos. Estos patrones temporales y de género deben ser considerados al diseñar e implementar estrategias de intervención y prevención en salud mental.
Para el análisis predictivo de los intentos de suicidio en Bogotá, se emplearon cuatro algoritmos de machine learning: Holt-Winters, redes neuronales LSTM, XGBoost y Random Forest. La evaluación de estos modelos reveló que XGBoost ofreció el mejor desempeño. Tras el ajuste de hiperparámetros, este modelo mostró mejoras notables en las métricas de evaluación. Las proyecciones para los años 2024 y 2025 indican un aumento en los intentos de suicidio, con incrementos estimados del 1.31% y del 0.96%, respectivamente. Esto sugiere que XGBoost es una herramienta confiable para pronosticar la tendencia de futuros casos y, por lo tanto, que facilita la toma de decisiones informadas y estratégicas en el ámbito de la salud pública.
Los resultados obtenidos destacan la habilidad de los modelos de machine learning para captar las complejidades de los datos sobre conductas suicidas, superando en muchos casos los métodos tradicionales de análisis. La precisión en la predicción de eventos futuros permite anticipar cambios en la incidencia de intentos suicidas, lo que es esencial para la asignación eficiente de recursos y el diseño de estrategias de intervención efectivas. En este contexto, la aplicación de técnicas avanzadas de análisis de datos valida la eficacia de la metodología utilizada y también abre nuevas oportunidades para la investigación futura. Integrar variables socioeconómicas y psicológicas podría enriquecer la capacidad predictiva y profundizar la comprensión de la dinámica suicida en entornos urbanos.
Este estudio presenta varias limitaciones que deben ser consideradas al interpretar los resultados. En primer lugar, se utilizaron únicamente datos secundarios de fuentes oficiales, lo que restringe el análisis a las variables disponibles y puede excluir factores relevantes no registrados, como antecedentes clínicos o condiciones psicosociales individuales. Además, aunque se aplicaron modelos de predicción con enfoque temporal, no se evaluó la influencia causal de las variables, por lo que los resultados se limitan a la identificación de patrones y tendencias. Algunos modelos, como el LSTM y el Random Forest, se implementaron con configuraciones estándar, sin una búsqueda exhaustiva de hiperparámetros, lo que podría afectar la comparación de su desempeño frente al modelo XGBoost. Finalmente, la generalización de los resultados está limitada al contexto de la ciudad de Bogotá, por lo que se recomienda precaución al extrapolar los hallazgos a otras regiones o poblaciones.
Referencias
Benavides-Mora, V., Villota-Melo, N. y Villalobos-Galvis, F. (2019). Conducta suicida en Colombia: Una revisión sistemática. Revista de Psicopatología y Psicología Clínica, 24(3). https://doi.org/10.5944/rppc.24251
Blanco, C. (2020). El suicidio en España: Respuesta institucional y social. Revista de Ciencias Sociales, 33(46), 79-106. http://www.scielo.edu.uy/pdf/rcs/v33n46/1688-4981-rcs-33-46-79.pdf
Calvache-Fernandez, L., Álvarez-Vallejo, V. y Triviño-Arbelaez, J. (2018). Proceso KDD como apoyo a las estrategias del proyecto SARA (Sistema de Acompañamiento para el Rendimiento Académico). Revista Educación en Ingeniería, 13(26). https://educacioneningenieria.org/index.php/edi/article/view/916
Castillo-Zúñiga, I., Lunas-Rojas, F. y López-Veyna, J. (2022). Detección de rasgos en estudiantes con tendencia suicida en Internet aplicando Minería Web. Revista Científica de Educomunicación, 71(3), 105-117. https://doi.org/10.3916/C71-2022-08
Castro-Moreno, L., Fuertes-Valencia, L., Pacheco-García, O. y Muñoz-Lozada, C. (2023). Factores de riesgo relacionados con intento de suicidio como predictores de suicidio, Colombia 2016-2017✩. Revista Colombiana de Psiquiatría, 52(3), 176-184. https://doi.org/10.1016/j.rcp.2021.03.002
Cifuentes, A., Gómez, T., y Jiménez, M. (2024). Analítica predictiva como apoyo en la salud pública: Modelos de pronóstico en salud mental con series de tiempo. Revista EIA, 21(42), 1–22. https://doi.org/10.24050/reia.v21i42.1763
Decreto 1743 de 2016 [Ministerio de Agricultura y Desarrollo Rural]. Por el cual se reglamenta el artículo 160 de la ley 1753 de 2015 y se adiciona el título 3 a la parte 2 del libro 2 del Decreto 1170 de 2015 Único del Sector Administrativo de Información Estadística. 1 de noviembre de 2016. https://www.funcionpublica.gov.co/eva/gestornormativo/norma.php?i=77734
Ehtemam, H., Sadeghi, S., Sanaei, A., Ghaemi, M. M., Hajesmaeel-Gohari, S., Rahimisadegh, R., Bahaadinbeigy, K., Ghasemian, F. y Shirvani, H. (2024). Role of machine learning algorithms in suicide risk prediction: A systematic review-meta analysis of clinical studies. BMC Medical Informatics and Decision Making, 24(1). https://doi.org/10.1186/s12911-024-02524-0
Espinosa-Zúñiga, J. J. (2020). Aplicación de algoritmos Random Forest y XGBoost en una base de solicitudes de tarjetas de crédito. Ingeniería, investigación y tecnología, 21(3), 1-20. https://doi.org/10.22201/fi.25940732e.2020.21.3.022
García-González, J., Sánchez-Sánchez, P., Orozco, M. y Obredor, S. (2019). Extracción de Conocimiento para la Predicción y Análisis de los Resultados de la Prueba de Calidad de la Educación Superior en Colombia. Formación universitaria, 12(4), 55-62. https://doi.org/10.4067/S0718-50062019000400055
González, L. (2023). La Ideación suicida en adolescentes: Estado de la cuestión. Revista CoPaLa. Construyendo Paz Latinoamericana, 8(17), 114. https://www.redalyc.org/journal/6681/668173277015/html/
Guzmán, V. (2021). El método cualitativo y su aporte a la investigación en las ciencias sociales. Gestionar: revista de empresa y gobierno, 1(4). https://dialnet.unirioja.es/servlet/articulo?codigo=8630390
Guzmán, V. y Gélvez, L. (2024). La ética y la responsabilidad en la implementación de la Inteligencia Artificial: Revisión sistemática. Revista Ingeniería, Matemáticas y Ciencias de la Información, 11(22), Article 22. https://doi.org/10.21017/rimci.1081
IBM. (17 de enero de 2024). ¿Qué es la fiabilidad de los datos? | IBM. https://www.ibm.com/es-es/topics/data-reliability
Imani, M., Beikmohammadi, A. y Arabnia, H. R. (2025). Comprehensive Analysis of Random Forest and XGBoost Performance with SMOTE, ADASYN, and GNUS Under Varying Imbalance Levels. Technologies, 13(3). https://doi.org/10.3390/technologies13030088
Joyanes, L. (2019). Inteligencia de negocios y analítica de datos: Una visión global de Business Intelligence & Analytics. Alfaomega Grupo Editor.
Kumar, V., Sznajder, K. K. y Kumara, S. (2022). Machine learning based suicide prediction and development of suicide vulnerability index for US counties. NPJ Mental Health Research, 1(3). https://doi.org/10.1038/s44184-022-00002-x
Lee, I. (10 de abril de 2023). Series de Tiempo: Forecasting con XGBoost. Medium. https://ivan-lee.medium.com/series-de-tiempo-con-xgboost-f732f1da3056
Malleza, S., Remezovski, L. A., Bertolani, F. C. y Matusevich, D. (2024). Análisis multidimensional de factores clínicos, demográficos y culturales en la ideación y conducta suicida en una sala de internación psiquiátrica. Revista del Hospital Italiano de Buenos Aires, 2(2), 1-20. https://doi.org/10.51987/revhospitalbaires.v44i2.290
Mira-Segura, L., Trejo-Martínez, A. y López-Cruz, D. (2018). Aplicación de la técnica Holt-Winters para prónosticos de inventarios. Revista de Divugación Cientifica y Tecnologica de la Universidad Autonoma de Nuevo Leon, 90(34), 1-20. https://doi.org/10.29105/cienciauanl21.90-2
Mojica, C., Hoyos, L., Vanegas, H., Muñoz, L. y Fernández-Ávila, D. (2023). Intento de suicidio pediátrico e ingreso a Unidad de Cuidado Intensivos, antes y después de la pandemia, en un hospital universitario en Boyacá, Colombia. Pediatría, 56(2). https://ouci.dntb.gov.ua/en/works/40ZQBAp9/
Mosquera-Ruiz, A. (2023). Experimentos con redes neuronales recurrentes LSTM para la predicción del nivel de glucosa de pacientes con diabetes. Revista Ontare, 11(1), 1-25. https://doi.org/10.21158/23823399.v11.n1.2023.3688
Moutier, C. (2023). Conducta suicida-Trastornos de la salud mental. Manual MSD versión para público general. https://www.msdmanuals.com/es-co/hogar/trastornos-de-la-salud-mental/conducta-suicida-y-autolesiva/conducta-suicida
Organización Mundial de la Salud. (2021). Suicidio. https://www.who.int/es/news-room/fact-sheets/detail/suicide
Orozco, W., Villao, A., Iguasnia, J. y Villarroel, M. (2021). Aplicación de técnicas de minería de datos para predecir el desempeño académico de los estudiantes de la escuela ‘Lic. Angélica Villón L.’. Revista Científica y Tecnológica UPSE, 8(2). https://doi.org/10.26423/rctu.v8i2.637
Park, H. y Lee, K. (2022). Using Boosted Machine Learning to Predict Suicidal Ideation by Socioeconomic Status among Adolescents. Journal of Personalized Medicine, 12(9), 1357. https://doi.org/10.3390/jpm12091357
Pastor, N., González, J. y Alarcón-Vásquez, Y. (2023). Reflexión sobre el impacto de la conducta suicida en el funcionamiento de las familias. Tejidos Sociales, 5(1). https://revistas.unisimon.edu.co/index.php/tejsociales/article/view/6304
Quemba, M., Herrera, J., Mendoza, A. y Mendoza, B. (2022). Comportamiento epidemiológico del intento de suicidio en niños y adolescentes, Colombia 2016-2020. Pediatría, 55(1). https://www.researchgate.net/publication/370885442_Comportamiento_epidemiologico_del_intento_de_suicidio_en_ninos_y_adolescentes_Colombia_2016-2020
Quinde-Rosales, V., Silvera-Tumbaco, C. y Vaca-Pinela, G. (2019). Análisis de cointegración entre el gasto en ciencia y tecnología y el producto interno bruto: Caso Ecuador. Revista Universidad y Sociedad, 11(2), 31-36. http://scielo.sld.cu/scielo.php?script=sci_abstract&pid=S2218-36202019000200031&lng=es&nrm=iso&tlng=es
Ramos-Serrano, C. (2021). Aprende mineria de datos con modelos y algoritmos: Aprende de minería de datos aplicado al análisis predictivo. Editorial Independiente.
Rangel-Villafaña, J. y Jurado-Cárdenas, S. (2022). Definición de suicidio y de los pensamientos y conductas relacionadas con el mismo: Una revisión. Psicología y Salud, 32(1), Article 1. https://psicologiaysalud.uv.mx/index.php/psicysalud/article/view/2709
Restrepo-Tobón, M., Mejía-Zapata, S. y García-Peña, J. (2023). El intento suicida en relación con la edad y otras variables psicosociales: Un análisis de contexto. Revista Virtual Universidad Católica del Norte, 69. https://doi.org/10.35575/rvucn.n69a9
Reyes, G., Coral, X. y Marchinares, A. (2022). Aplicación de machine learning para campañas de marketing en la banca comercial. Interfases, 20(16). https://doi.org/10.26439/interfases2022.n016.5953
Reyes-Ruiz, L., De la Hoz Granadillo, E. J. y Carmona Alvarado, F. A. (2019). Método para identificar y pronosticar riesgo suicida en perfiles de adolescentes mediante técnicas de análisis de conglomerado y red neuronal artificial. Revista AVFT-Archivos Venezolanos de Farmacología y Terapéutica, 1(2), 1-6. https://bonga.unisimon.edu.co/handle/20.500.12442/4271
Rodríguez, C. A. M., Pinzón, M. A. R., Quintero, L. M. P. y Vergel, L. M. A. (2024). Aplicación de machine learning y metodología CRISP-DM para la clasificación precisa de severidad en casos de dengue. Revista Colombiana de Tecnologías de Avanzada (RCTA), 1(43). https://doi.org/10.24054/rcta.v1i43.2822
Rodríguez, F. B., Figueroa, C. L., Yucumá, D., Salgado-Cendales, A., Gallego, J. P. A., Barrios, J. G. R., Cabrales, L. G., Moná, S. B., Rincón, C. J. y Restrepo, C. G. (2023). Salud mental en la población bogotana: Análisis de la Encuesta Nacional de Salud Mental. Revista de Salud Pública, 25(3). https://doi.org/10.15446/rsap.v25n3.93116
Rodríguez-Esparza, L., Barraza-Barraza, D., Salazar-Ibarra, J. y Vargas-Pasaye, R. (2021). Metodología de Análisis de Emociones para Identificar Riesgo de Cometer Suicidio Generado por el COVID-19. Revista Lasallista de Investigación, 18(2), 105-124. https://dialnet.unirioja.es/servlet/articulo?codigo=8843575
Salcedo, F., Alvis, N., Jerez, M., Paz, J. y Carrasquilla, M. (2019). Determinantes sociales del intento de suicidio en jóvenes colombianos. Panorama Económico, 27(3). https://doi.org/10.32997/2463-0470-vol.27-num.3-2019-2588
Sánchez, A., Vidal-Silva, C., Mancilla, G., Tupac-Yupanqui, M. y Rubio, J. (2023). Sustainable e-Learning by Data Mining-Successful Results in a Chilean University. Revista Sustainability, 15(2), 1-20. https://doi.org/10.3390/su15020895
Suárez-Castro, R. y Ladino-Vega, I. (2023). Redes neuronales aplicadas al control estadístico de procesos con cartas de control EWMA. Tecnura, 27(75), 72-88. https://doi.org/10.14483/22487638.18623
Torres, A. (2021). Análisis de opinión sobre tuits del COVID-19 generados por usuarios ecuatorianos. Revista del Centro de Estudio y Desarrollo de la Amazonia, 11(1), 70-77. https://dialnet.unirioja.es/servlet/articulo?codigo=9355032
Urbina, S., Zayas, H. y López, O. (2019). Algoritmo Random Forest para la detección de fallos en redes de computadoras. Serie Científica de la Universidad de las Ciencias Informáticas, 12(8). https://publicaciones.uci.cu/index.php/serie/article/view/445
Vigoya-Rubiano, A. R., Osorio-Barajas, Y. S. y Salamanca-Camargo, Y. (2019). Caracterización del intento de suicidio en una ciudad colombiana (2012 – 2017). Revista Duazary, 16(1), 53-66.
Xu, X.-M., Liu, Y. S., Hong, S., Liu, C., Cao, J., Chen, X.-R., Lv, Z., Cao, B., Wang, H.-G., Wang, W., Ai, M. y Kuang, L. (2024). The prediction of self-harm behaviors in young adults with multi-modal data: An XGBoost approach. Journal of Affective Disorders Reports, 16(10), 100723. https://doi.org/10.1016/j.jadr.2024.100723
Zamora, A. (2023). Una visión general sobre la investigación en Colombia de la ideación suicida y la conducta suicida. Fundación Universitaria Católica Lumen Gentium, 2(2), 1-24.





