INTRODUCCIÓN
La rama de la Inteligencia Artificial denominada Machine Learning proporciona algoritmos que posibilitan el aprendizaje automático por parte de las computadoras (Porcelli, 2020). Entre estos algoritmos, la técnica de Deep Learning ha tenido una atención especial debido a su utilidad en aplicaciones del mundo real, como detección y localización de objetos, segmentación, entre otras. Con base en el funcionamiento del cerebro humano, un sistema de Red Neuronal se compone por múltiples capas que realizan abstracciones de las características de los objetos de interés, útiles en nuevas situaciones (Silva, 2020).
Específicamente, la segmentación de imágenes es un problema que puede ser tratado adecuadamente mediante Deep Learning, de forma supervisada o no supervisada, y cumple con dividir la imagen en segmentos mediante la discriminación y clasificación de píxeles, designándole a cada uno de ellos una categoría, basándose en parámetros previamente asignados (Reyes Ortiz et al., 2019).
El propósito del presente trabajo es diseñar e implementar una solución basada en Deep Learning que permita segmentar emisiones de ceniza en imágenes satelitales, mediante Redes Neuronales Convolucionales, además de elaborar un extenso y confiable dataset de imágenes, que sirva de entrenamiento para la predicción de la delimitación del esparcimiento de ceniza volcánica de nuevas imágenes satelitales. La relevancia del tema es debido al poder abrasivo que tiene el material volcánico, pudiendo ser perjudicial para los seres humanos, tanto para la ganadería, la agricultura, la salud y el transporte terrestre, marino y aéreo (OPS, 2021).
Se ha considerado como caso de estudio para la predicción, el actualmente activo Volcán Sangay, ubicado en el corredor Subandino del Ecuador (Fig. 1) con coordenadas límites Noroeste (786003E, 9784619S); Sureste (805184E, 9769198S) proyectadas en UTM, WGS84 17S. La emisión paulatina de ceniza desde el 2019 ha afectado a zonas cercanas al sur y oeste de la zona, e incluso llegando a Guayaquil (IG-EPN, 2021). El Grupo de Investigación sobre la Ceniza Volcánica en Ecuador (GICVE) desde el 2017 monitorea la dispersión de este material que resulta peligroso para los seres vivos, pero no han presentado aún su modelo automático (GICVE, 2020).
No existen estudios previos desarrollados con redes neuronales convolucionales aplicados a la segmentación de ceniza volcánica, siendo éste nuestro aporte en el campo geológico; sin embargo, se tienen estudios para detectar ceniza, como el proyecto de la Universidad San Francisco en el GICVE y la determinación de dirección, altura y velocidad de nubes de ceniza implementada por el IG-EPN. El algoritmo presentado se orienta en modelos de segmentación en redes neuronales utilizados en el campo de la medicina (Caldas, 2017).
Nuestras contribuciones principales son:
1) la implementación de un modelo basado en Deep Learning para la segmentación de ceniza en imágenes satelitales, cuyo código se encuentra disponible públicamente en: https://colab.research.google.com/drive/1dqCUrcR6jh51zMiolZkPE4EZfATnQ7Dm?usp=sharing y
2) la elaboración de un repositorio de imágenes satelitales de varios volcanes activos del mundo, que se encuentra disponible en: https://drive.google.com/drive/folders/1jFAg5MiF9zZK1ESlhGP7usHTs4zeprGU?usp=sharing
Para tal fin hemos recolectado imágenes proporcionadas por los satélites GOES 16 y 17, Meteosat-8, Meteosat-11 y Himawari-8. Estas imágenes aplican un filtro Ash, en donde la ceniza tiene una coloración rosada rojiza y se encuentran publicadas en páginas web del Instituto Cooperativo de Estudios de Satélites Meteorológicos (CIMSS, 2021) perteneciente al Centro de Ingeniería y Ciencias Espaciales (SEEC); del Instituto Cooperativo de Investigación en la Atmósfera (CIRA, 2021) y de la Administración Nacional Oceánica y Atmosférica (NOOA, 2021).
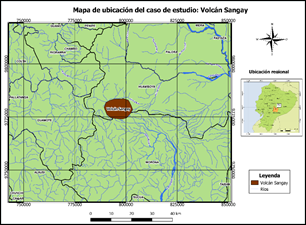 Figura 1
Mapa de Ubicación del Caso de
Estudio
Figura 1
Mapa de Ubicación del Caso de
Estudio
METODOLOGÍA
En
la figura 2 se muestra un flujograma de la metodología realizada en este trabajo para
la delimitación de ceniza volcánica mediante Deep Learning. Seguidamente, cada una
de las etapas son descritas de manera detallada.
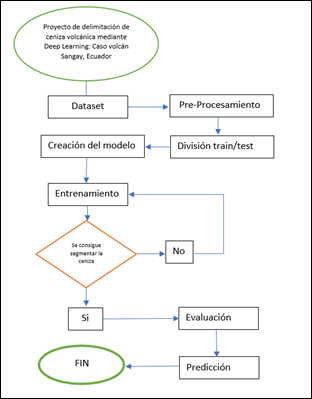 Figura 2
Metodología de trabajo
Figura 2
Metodología de trabajo
Dataset
Las imágenes fueron obtenidas de forma gratuita de la página web CIMSS (Space Science and Engineering Center of University of Wisconsin-Madison) Satellite Blog, descargando archivos GIF de emisiones de ceniza de volcanes activos que tengan el filtro Ash proporcionados por el satélite GOES (Fig. 3); los cuales tienen como propiedades un ancho de 100 píxeles, alto de 821 píxeles y profundidad de 8 bits.
Los archivos GIF se cargaron al programa en línea Online-convert, para posteriormente elegir la opción convertir GIF a JPG; en la que se puede subir el archivo, mantener su calidad o modificarla; además de proporcionar opciones de coloración, monocromático, negativo, recortar píxeles, umbral de color, etc. Para este caso se utilizó la opción dada por defecto, usando calidad alta de 300x200 píxeles y ajustes de calidad bastante buena, obteniendo un total de 606 imágenes.
Para la denominación de las imágenes, se mantuvo el nombre por defecto de la descarga desde las páginas web del Instituto Cooperativo de Estudios de Satélites Meteorológicos (CIMSS), del Instituto Cooperativo de Investigación en la Atmósfera (CIRA) y de la Administración Nacional Oceánica y Atmosférica (NOOA), estandarizándolas según el volcán, satélite y numeración, por ejemplo (Novarupta_Goes17_091).
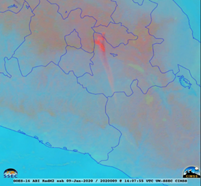 Figura 3
Imagen satelital GOES-16 aplicado el filtro Ash
del volcán Popocatépetl.
Figura 3
Imagen satelital GOES-16 aplicado el filtro Ash
del volcán Popocatépetl.
Pre-Procesamiento
No es suficiente con la adquisición del dataset, sino que también es necesario procesarlo; se deben tener dos grupos de imágenes, el primer grupo correspondiente a las imágenes satelitales adquiridas y el segundo con las imágenes segmentadas, mostrando de color negro la zona o el área de la imagen satelital donde se evidencia ceniza, y en color blanco el resto de área de la imagen donde no exista ceniza, como se muestra en la figura 4.
 Figura 4
Figura 4
La imagen de la izquierda corresponde al dataset original, en donde
la ceniza se encuentra de color rojo y rosado. La imagen de la derecha corresponde
a la imagen segmentada, en donde únicamente se marca la ceniza con tonalidad negra.
Al ser un caso de estudio de segmentación supervisada, las imágenes del dataset, deben ser preprocesadas para poder ser utilizadas en el modelo de red neuronal, ya sea en el mismo entorno de programación con librerías de Python o mediante un programa externo. Para el tratamiento de las imágenes hemos elegido la segunda opción con el software Photoshop CS6 pues cuenta con herramientas para trabajar en lotes de imágenes modificando parámetros como la saturación, tono, brillo, intensidad, contraste, etc. Mediante la especificación del valor de un umbral, el área de las imágenes donde existe ceniza toma el color negro y el resto de la imagen se torna blanca; además, se modificó el tamaño de las imágenes a 300 por 200 píxeles.
Una vez modificadas las imágenes, se crearon dos carpetas, la primera llamada Ceniza_images que contiene las imágenes redimensionadas en formato JPG con sistema de color RGB y la segunda carpeta nombrada Ceniza_masks, que contiene las imágenes, con el mismo nombre, en formato JPG de la carpeta Ceniza_images, pero con sistema de color B&N.
La importación de las librerías NumPy y cv2 de Python permite convertir las imágenes en arrays de datos numéricos que son normalizados en un rango definido (SciPy, 2021), y posteriormente, redimensionar las imágenes a 32 píxeles x 32 píxeles, brindando mayor facilidad y rapidez durante el proceso del entrenamiento.
Al tratarse de un aprendizaje supervisado, se debe alimentar y entrenar la red definiendo entradas (Ceniza_images) y sus respectivas salidas (Ceniza_masks) conocidas. A través de la función np.empty, se crea y devuelve una referencia a un array vacío (Sánchez, 2020) con las dimensiones (32, 32, 3), incluyendo además el argumento dtype='float32', el cual indica un bitsize de 32. Para comprobar el manejo adecuado de las imágenes, a través de la librería matplotlib se pueden visualizar las imágenes normalizadas y redimensionadas.
División del
Dataset
Para
la división del dataset se utilizó el comando: train_split(), de
la librería sklearn.model_selection especificando dos subconjuntos;
el primero de entrenamiento (train) que contiene el 80% de los datos y el segundo
de prueba (test) con el 20% de los datos restantes; la distribución de los datos
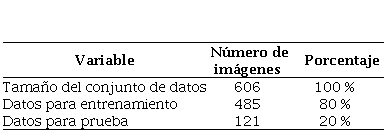
se puede ver en la Tabla 1. El dataset completo tiene un formato de (606, 32, 32,
3), mientras que el conjunto de entrenamiento tiene un formato de (485, 32, 32,
3). El 80% del dataset equivale al conjunto de entrenamiento, con el cual se ajusta
los parámetros del modelo y el 20% es el conjunto de test, con los que se evalúa
el rendimiento del modelo entrenado (Aguilar, et al., 2019).
Tabla 1
Número de imágenes y división del
Dataset
|
Variable
|
Número
deimágenes
| Porcentaje
|
|
Tamaño
del conjunto de datos
|
606
|
100
%
|
|
Datos
para entrenamiento
|
485
|
80
%
|
|
Datos
para prueba
|
121
|
20
%
|
Creación del
Modelo
El modelo es una adaptación del presentado por Ronneberger et al. (2015), el cual se diseñó para tareas de segmentación con fines biomédicos. Esta arquitectura se basa en una típica red neuronal convolucional (CNN) compuesta por un codificador (encoder) y un decodificador (decoder) (Livne et al., 2019), configurando un patrón de contracción (encoder) para reducir la resolución de la imagen y un patrón expansivo simétrico (decoder) para el aumento de su resolución (Li et al., 2019).
La imagen de entrada (input) tiene una dimensión de 32x32x3. El encoder (parte izquierda de la Fig. 5) está establecido de acuerdo con el número de filtros (8, 16, 32 y 64) aplicados por capa; así el encoder se compone por 5 capas convolucionales, con filtros de 3x3 que crean mapas de características que capturan patrones en la imagen, en la que el volumen de salida está determinado según el número de filtros. A cada capa le sigue una unidad lineal rectificada (ReLU) que anula los valores negativos y deja pasar a los positivos a la siguiente capa tal como entran (Yasrab, 2018). La operación de MaxPooling de 2x2 realiza un muestreo descendente (downsampling), en donde, en cada contracción las dimensiones son reducidas a la mitad.
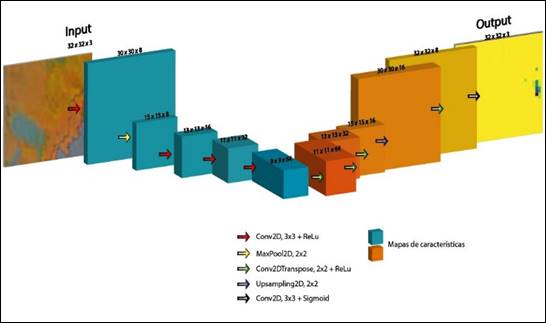 Figura 5
Ilustración
de la arquitectura del modelo. A la izquierda el Encoder y a la derecha el
Decoder. Cada caja corresponde a un mapa de características multicanal.
Figura 5
Ilustración
de la arquitectura del modelo. A la izquierda el Encoder y a la derecha el
Decoder. Cada caja corresponde a un mapa de características multicanal.
El decodificador tiene como objetivo recuperar las dimensiones originales de las imágenes de entrada mediante un muestreo ascendente (upsampling) del mapa de características (Livne, et al., 2019). Así en el decoder (parte derecha de la Fig. 5) se incluyen 5 capas convolucionales transpuestas de 3x3, que reducen a la mitad el número de canales de características, continuando con la función de activación ReLU. La capa final es una convolución de 3x3, con una activación de tipo sigmoide usada para mapear cada vector de características (Ronneberger, et al., 2015). El resultado (output) es una imagen segmentada de dimensiones de 32x32x3.
Se debe considerar que la implementación de las capas del modelo fue importada mediante la instrucción from tensorflow.keras.models import Model, en donde cada capa fue añadida con el comando model.add.
RESULTADOS
Entrenamiento
del Modelo
El entrenamiento se realiza en Google Colaboratory, una plataforma on-line de hardware y software para aprendizaje automático de acceso gratuito que brinda 12 GB de RAM y 50 GB de almacenamiento en disco. Los códigos y comandos que se ejecuten mediante los notebooks de Colab usan GPU y TPU (graphics processing unit y tensor processing unit, respectivamente), que es un circuito integrado de aplicación específica y acelerador de Inteligencia Artificial, que no afecta el rendimiento de la computadora (De la Fuente, 2019).
Para realizar el entrenamiento se utiliza el comando model.fit, estableciendo las iteraciones del conjunto de datos o épocas que se realizan para tener una mejor precisión del modelo, en este caso se establecieron 100 épocas, teniendo un tiempo de ejecución de 15 minutos aproximadamente.
Se estableció un verbose de 1, lo que nos permite observar una barra de proceso animada y ayuda a detectar el sobreajuste que ocurre si la precisión de entrenamiento ('acc') sigue mejorando mientras la precisión de validación ('val_acc') empeora.
Evaluación
del Modelo
La mejor precisión del entrenamiento se obtuvo en la época 10 con un valor de 0.99 y un valor de pérdida de 0.16. Luego se produce un descenso del rendimiento, por lo que no había necesidad de efectuar más épocas.
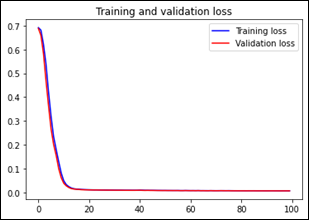 Figura 6
Gráfica de la pérdida del entrenamiento y validación del modelo
Figura 6
Gráfica de la pérdida del entrenamiento y validación del modelo
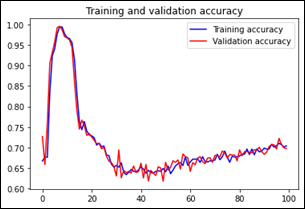 Figura 7
Gráfica de la precisión del entrenamiento
y validación del modelo
Figura 7
Gráfica de la precisión del entrenamiento
y validación del modelo
Para visualizar el comportamiento del entrenamiento y validación del modelo se realizó el ploteo de los valores de pérdida y precisión del entrenamiento y de la validación (Fig. 6 y 7) a través del historial que se va almacenando durante el proceso y las instrucciones de plt.figure() y plt.show().
Estas gráficas ayudan a entender el rendimiento del modelo, en el caso de la pérdida se observa que tiende a cero, mientras en la precisión se observa una fluctuación entre 0.7 y 1.0. Además, las gráficas demuestran que no existe overfitting en el entrenamiento y validación del modelo.
Para un mejor detalle de los resultados, se implementa la matriz de confusión, que es una tabla resumida utilizada para poder evaluar el rendimiento del modelo de clasificación. El número de predicciones correctas e incorrectas se resumen en la tabla con un conteo y se muestra gráficamente para cada clase (Shin , 2020).
El verdadero positivo (cuadro amarillo) y el verdadero negativo (cuadro verde) son los resultados donde el modelo predice correctamente si existe ceniza o no existe ceniza en la imagen, mientras el falso positivo y falso negativo (cuadros morados) son los resultados donde el modelo predice incorrectamente, obteniendo ceniza donde no existe o al revés, ésto se le conoce como error tipo 1 y 2. En el caso de nuestro modelo, se obtiene los mayores valores en el cuadro amarillo y cuadro verde y los menores valores en los cuadros morados, lo que indica que el modelo predice correctamente la ceniza volcánica en las imágenes satelitales.
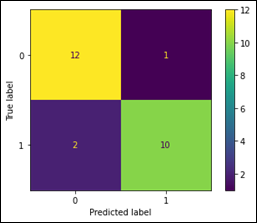 Figura 8
Matriz de confusión del modelo
Figura 8
Matriz de confusión del modelo
En
la figura 8 se observa la matriz de confusión, la cual indica una precisión de 88%,
que se obtiene de la suma del valor del cuadro amarillo (verdadero positivo) y el
valor del cuadro verde (verdadero negativo) dividido para la suma de los valores
de todos los cuadros. La fracción de verdaderos positivos (sensibilidad) del modelo,
obtenido mediante el verdadero positivo (cuadro amarillo) y falso negativo (cuadro
morado), es del 85.7%, siendo capaz de detectar correctamente la ceniza.
Segmentación de Imágenes de Validación
Para
la validación del modelo se realizó con el 20% de la base de datos, que corresponde
a 121 imágenes cargadas en el inputs_test.
En la figura 9, en la imagen
de la derecha, se observa la imagen predicha para ceniza y concuerda con la zona
establecida de ceniza en el output. Esto tiene relación con la pérdida de validación
(val_loss)
que tiene un valor de 0.16 y con el valor de precisión de validación (val_acc)
de 0.98, lo que indica un comportamiento adecuado del modelo.
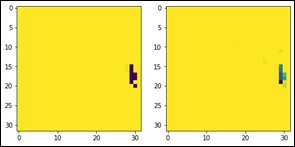 Figura 9
Figura 9
Izquierda: imagen segmentada del output. Derecha: imagen de validación segmentada.
Los píxeles de color morado y verde indican la existencia de ceniza, los píxeles
en amarillo no presentan ceniza
DISCUSIÓN
Las gráficas de precisión y pérdida (Fig. 6 y 7) evidencian que se alcanzó la mejor precisión en la época 10 con un valor de 0.99 y con una pérdida de 0.16. Por su parte, la matriz de confusión (Fig. 8) indica que la precisión del modelo es del 88% y su sensibilidad 85.7%, mostrando que los resultados son los esperados y el modelo tiene un buen entrenamiento y validación.
Por ende, se estima que el modelo tendrá un buen reconocimiento en una nueva imagen ya que el aprendizaje fue óptimo con respecto al dataset inicial y tampoco tendrá un desajuste debido a que se ha trabajado con una extensa base de imágenes, la cual se puede aumentar para seguir mejorando la precisión final, pero teniendo en cuenta las especificaciones que se pide para las imágenes satelitales. El modelo realizado puede ser implementado para la segmentación de ceniza volcánica ya que se considera como un modelo válido que aún se puede mejorar.
Predicción
Para
la predicción del modelo mediante el comando model.predict(), se
utilizaron imágenes satelitales con filtro Ash del Volcán Sangay, obtenidas del
satélite GOES-16, estas imágenes no han sido utilizadas en el entrenamiento o en
la validación. En la figura 10 se observa la imagen de entrada y la imagen segmentada,
la cual muestra similitud en la segmentación de ceniza que se encuentra en la parte
superior central de la imagen. Sin embargo, la delimitación no es exacta, ya que
no se segmenta todo el contorno de ceniza, pero es considerada aceptable debido
a su precisión.
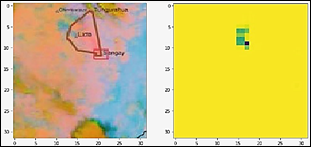 Figura 10
Figura 10
Imagen izquierda es una imagen satelital del Volcán Sangay obtenida del satélite
GOES-16 el 9 de marzo de 2021 (IG-EPN, 2021), para la predicción
del modelo. Imagen derecha es una imagen segmentada que delimita el contorno de
la ceniza del Volcán Sangay.
De esta manera la segmentación de ceniza en imágenes satelitales podría convertirse en un modelo inicial para la caracterización de su dispersión, y con ello llegar a la interpretación de la posible interacción medio ambiente-ser vivo. Con lo que el modelo proporcionaría un soporte técnico para la toma de decisiones que brindarían medidas ante un potencial riesgo volcánico.
Se debe tener en cuenta que, al tratarse de un modelo inicial válido, para una mayor confiabilidad, la elaboración de un modelo necesitaría considerar factores como dirección y velocidad del viento, condiciones climáticas, entre otras; sin embargo, con lo obtenido en este estudio se podrían llegar a estimaciones de superficie de la ceniza esparcida, dirección preferencial de dispersión, velocidad de dispersión y localización de posibles áreas afectadas.
CONCLUSIONES
Hemos implementado un modelo para la segmentación de ceniza de imágenes satelitales, aplicando Deep Learning, a través la plataforma Google Colaboratory en lenguaje Python; obteniendo así, para el caso de estudio, la predicción de la segmentación de ceniza en imágenes satelitales de emanaciones del Volcán Sangay.
La elaboración del dataset, con el cual se entrenó al modelo, tiene un total de 606 imágenes en formato JPG. El dataset obtenido de las páginas web del Instituto Cooperativo de Estudios de Satélites Meteorológicos (CIMSS) perteneciente al Centro de Ingeniería y Ciencias Espaciales (SEEC), del Instituto Cooperativo de Investigación en la Atmósfera (CIRA) y de la Administración Nacional Oceánica y Atmosférica (NOOA), resulta una base de información confiable y extensa.
El modelo diseñado e implementado fue basado en una red neuronal convolucional típica, compuesta por capas convolucionales que configuran un codificador y un decodificador; de esta manera se produjo un rendimiento aceptable para la predicción en la delimitación de ceniza volcánica en imágenes satelitales, teniendo que el valor de pérdida es igual a 0.01, el valor de precisión más alto que se obtuvo es de 0.99 y la matriz de confusión muestra una evaluación positiva.
Con el modelo se pudo realizar la segmentación de ceniza proveniente del Volcán Sangay en imágenes satelitales con filtro Ash, como se muestra en los resultados, en donde se segmenta la ceniza del volcán, capturada en una imagen satelital del GOES-16 obtenida el 9 de marzo del 2021.
RECOMENDACIONES
Realizar un pre-procesamiento adecuado y riguroso para obtener imágenes que puedan ser procesadas con el modelo, utilizando programas de edición, en donde sea posible manipular la saturación, tono, brillo, intensidad, contraste y umbral de las éstas.
El presente modelo está entrenado con imágenes satelitales con el filtro Ash, por lo que, para futuras predicciones, se deberán considerar imágenes con un filtro o tipo de variación contrastante para obtener un resultado óptimo.
Se debe tener un conocimiento básico de programación para manipular el código, sugiriendo continuar con el tratamiento de imágenes relacionadas a ciencias geológicas o ramas afines, para permitir una mayor facilidad en su análisis.
Referencias
Aguilar, R., Torres, J., & Martín, C., 2019.
Aprendizaje Automático en la Identificación de Sistemas. Un Caso de
Estudio en la Predicción de la Generación Eléctrica de un Parque Eólico.
Revista Iberoamericana de Automática e Informática industrial, 16(1), 114-127. https://doi.org/10.4995/riai.2018.9421
Caldas, S., 2017. Exploración de machine learning como técnica de segmentación pulmonar en presencia de opacidades de gran tamaño. Proyecto de Grado. Bogotá: Universidad de los Andes.
CIMSS, 2021.
Cooperative Institute for Meteorological Satellite Studies. https://cimss.ssec.wisc.edu/
CIRA, 2021. Cooperative
Institute for Research in the Atmosphere . https://www.cira.colostate.edu/
De la Fuente, O., 2019. Google Colab: Python y Machine Learning en la nube. Available at: https://www.adictosaltrabajo.com/2019/06/04/google-colab-python-y-machine-learning-en-la-nube/ [Último acceso: 15 Marzo 2021].
GICVE, 2020. Ceniza Volcánica en Ecuador. Available at: https://www.usfq.edu.ec/es/investigacion/grupo-de-investigacion-sobre-la-ceniza-volcanica-en-el-ecuador-gicve
IG-EPN, 2021. IGAl Instante Informativo VOLCÁN SANGAY Nº 2021-034. Quito: Escuela Politécnica Nacional.
IG-EPN, 2021. Sangay. Available at: https://www.igepn.edu.ec/sangay. [Último acceso: 20 Marzo 2021].
Li, S., Yang, C., Sun, H. & Zhang, H., 2019. Seismic fault detection using an encoder–decoder convolutional neural network with a small training set. Journal of Geophysics and Engineering, 16(1), pp. 175–189. https://doi.org/10.1093/jge/gxy015
Livne, M., Rieger, J., Aydin, O.U., Taha, A.A., Akay, E.M., Kossen, T., Sobesky, J., Kelleher, J.D., Hildebrand, K., Frey, D. and Madai, V.I., 2019. A U-Net Deep Learning Framework for High Performance Vessel Segmentation in Patients With Cerebrovascular Disease. Frontiers in Neuroscience. 13:97. https://doi.org/10.3389/fnins.2019.00097
NOOA, 2021. National Oceanic and Atmospheric
Administration. https://www.noaa.gov/
OPS, 2021. Los impactos a la salud asociados con las cenizas de los volcanes. Available at: https://www.paho.org/hq/index.php?option=com_content&view=article&id=8194:2013-los-impactos-salud-asociados-cenizas-volcanes&Itemid=39797
Porcelli, A.M., 2020. Artificial Intelligence and Robotics: Its social, ethical and legal dilemmas. Derecho global. Estudios sobre derecho y justicia, 6(16), 49-105. https://doi.org/10.32870/dgedj.v6i16.286
Reyes Ortiz, O. J., Mejía, M., & Useche Castelblanco, J. S., 2019.
Técnicas de inteligencia artificial utilizadas en el procesamiento de
imágenes y su aplicación en el análisis de pavimentos. Revista EIA, 16(31), 189–207. https://doi.org/10.24050/reia.v16i31.1215
Ronneberger, O., Fischer, P. & Brox, T., 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. Springer International Publishing Switzerland, pp. 234-241. https://doi.org/10.1007/978-3-319-24574-4_28
Sánchez, A., 2020. Aprende con Alf. Available at: https://aprendeconalf.es/docencia/python/manual/numpy/ [Último acceso: 22 Marzo 2021].
SciPy, 2021. Numpy. Available at: https://numpy.org/doc/stable/user/index.html [Último acceso: 22 Marzo 2021].
Shin , T., 2020. Comprensión de la Matriz de Confusión y Cómo Implementarla en Python. https://towardsdatascience.com/understanding-the-confusion-matrix-and-how-to-implement-it-in-python-319202e0fe4d [Último acceso: 21 Marzo 2021].
Silva, A., 2020. Estudio comparativo de modelos de clasificación automática de señales de tráfico. Universidad Pública de Navarra-España., pp. 7-14.
Yasrab, R., 2018. ECRU: An Encoder-Decoder Based Convolution Neural Network (CNN) for Road-Scene Understanding. Journal of Imaging, 4(10), 116; https://doi.org/10.3390/jimaging4100116
Información adicional
Cómo citar: Aldás-Núñez, R. J., Tuz-Chamorro, K. V., Vega-Ocaña, J. A., Velasco-Haro,
M. S. & Mejía-Escobar, C.I. (2022). Delimitación
automática de ceniza volcánica en imágenes satelitales mediante Deep Learning.
FIGEMPA: Investigación y Desarrollo, 13(1), 48–58. https://doi.org/10.29166/revfig.v13i1.3121





