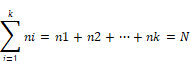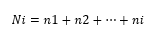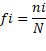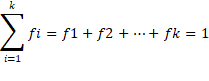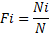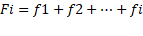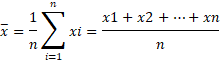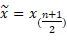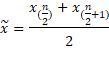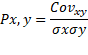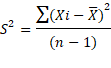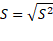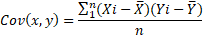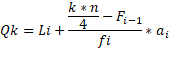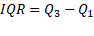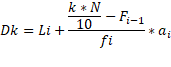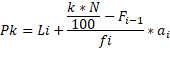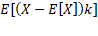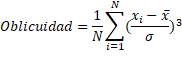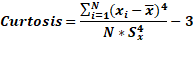INTRODUCCIÓN
El proceso de embarazo en la mujer es quizá una de las etapas más importantes en la vida de estas. Toda mujer que está en camino a ser madre desea que su bebé nazca sin ningún tipo de inconveniente. La importancia de nuestro proyecto radica en la necesidad de conocer cómo influye el lugar de concepción del feto en su índice de mortalidad. Dado que las condiciones físicas del entorno pueden llegar a variar de un lugar a otro, inclusive dentro de una misma ciudad o parroquia, puede que dicho ambiente que rodea al feto sea un factor clave en la correcta gestación de éste dentro de la matriz de la madre.
El problema se hace evidente considerando que, durante los últimos años, las defunciones fetales han sufrido un incremento preocupante, cifras que alarman a la población general de mujeres embarazadas, y cuyas principales fluctuaciones se han visto establecidas principalmente dentro de ciertos cantones y parroquias suburbanas.
Trabajos relacionados
Graciela Castañeda, Horacio Márquez, y Esperanza Rodríguez (Castañeda Casale G., Márquez González H., y Rodríguez Reyes E. R., 2010) evaluaron la mortalidad perinatal en un hospital de segundo nivel de atención donde, desde 2004, se ha presentado una alta tasa de mortalidad durante el manejo de neonatos de alto riesgo. Para ello realizaron un estudio longitudinal retrospectivo considerando las tasas de mortalidad perinatal calculadas desde el 2002, y los expedientes de defunciones de 2004 a 2007. Ingresaron los datos obtenidos en el programa estadístico SPSS y realizaron un análisis de correlación de Pearson. Como resultado observaron que la causa más frecuente de muerte fetal fue la interrupción de la circulación materno-fetal en un 80% de los casos. Sin embargo, este estudio no logró determinar la forma más factible de reducir esta tasa de mortalidad. Nuestro trabajo busca establecer la influencia del lugar de concepción de un feto en su índice de mortalidad, y, además, hallar la solución óptima para aumentar las posibilidades de supervivencia de un feto que pueda verse afectado por dicha zona de concepción.
Linares, y Poulsen (Linares J. y Poulsen R., 2007) elaboraron un estudio de las muertes fetales intrauterinas ocurridas en mujeres embarazadas a partir de las 20 semanas de gestación, cuyos partos fueron atendidos en el Servicio de Ginecología y Obstetricia del Hospital Clínico Regional de Antofagasta, y donde se presentó un elevado índice de muertes fetales. Para dicho estudio, extrajeron las historias clínicas de las pacientes afectadas, las auditorías de muerte fetal tardía, y las autopsias realizadas. Los datos obtenidos los procesaron empleando el Estadístico Excel 4.0 calculando las frecuencias mediante tablas de distribución absoluta y porcentual. Obtuvieron como resultado que la mayoría de las defunciones fetales se dieron en mujeres entre los 15 y 20 años, además los factores asociados más influyentes fueron el consumo de sustancias nocivas, y embarazos no controlados. Con esto determinaron que un diagnóstico previo, y un adecuado tratamiento de control prenatal sería una solución factible. Sin embargo, su trabajo presenta un escaso uso de métodos estadísticos para el análisis de los datos recopilados, pudiendo afectar esto a la fiabilidad de los resultados. Nuestro trabajo, por el contrario, será desarrollado empleando métodos estadísticos más concretos, como histograma de frecuencias, diagrama de barras y coeficiente de correlación, lo cual nos permitirá obtener resultados más confiables que nos permitan a su vez, determinar las soluciones más factibles.
MATERIALES Y MÉTODOS
Para el desarrollo de nuestro proyecto organizaremos la información obtenida. Primero definiremos los conceptos estadísticos que vamos a utilizar para procesar los datos. Luego dejaremos claro las relaciones entre nuestras variables y como presentaremos los resultados, así como los programas que fueron necesarios utilizar. Por último, describiremos los métodos de recolección y análisis de datos, y los casos de estudio necesarios.
Teoría
Tabla de Frecuencias
Según (Gutiérrez Á.
M. A., Babativa L. Y., Lozano I. 2014), la tabla de frecuencias (o distribución
de frecuencias) es una tabla que muestra la distribución de los datos mediante
sus frecuencias. Se utiliza para variables cuantitativas o cualitativas
ordinales. La tabla de frecuencias es una herramienta que permite ordenar los
datos de manera que se presentan numéricamente las características de la
distribución de un conjunto de datos o muestra.
El modelo matemático de una tabla de frecuencias es el siguiente:

|
Xi
|
Frecuencia Absoluta
|
Frecuencia Absoluta
Acumulada
|
Frecuencia Relativa
|
Frecuencia Relativa
Acumulada
|
|
1
|
ni
|
Ni
|
fi= ni / N
|
Fi= Ni / N
|
La frecuencia absoluta (ni) de
un valor Xi es el número de veces que el valor está en el conjunto (X1,X2,...,Xn). La suma de las frecuencias absolutas de todos los
elementos diferentes del conjunto debe ser el número total de sujetos N (Gutiérrez Á. M. A., Babativa L. Y., Lozano I. 2014). Si
el conjunto tiene k números (o categorías) diferentes, entonces:
La frecuencia absoluta acumulada (Ni)
de un valor Xi del conjunto (X1,X2,...,Xn ) es la suma de las frecuencias absolutas de los
valores menores o iguales a Xi, es decir [3]:
La frecuencia relativa (fi) es la frecuencia absoluta
dividida por el número total de elementos N:
La suma de las
frecuencias relativas de todos los sujetos da 1. Supongamos que en el conjunto
tenemos k números (o categorías) diferentes, entonces (Gutiérrez Á. M. A.,
Babativa L. Y., Lozano I. 2014):
Frecuencia relativa acumulada (Fi) es la frecuencia
absoluta acumulada dividida por el número total de sujetos N:
La frecuencia
relativa acumulada de cada valor siempre es mayor que la frecuencia relativa.
De hecho, la frecuencia relativa acumulada de un elemento es la suma de las
frecuencias relativas de los elementos menores o iguales a él, es decir
(Gutiérrez Á. M. A., Babativa L. Y., Lozano I. 2014):
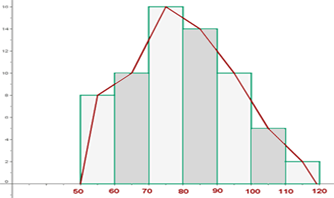
Histograma de Frecuencias
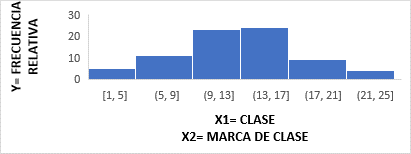
Según (Casanova H., 2017), el histograma es una representación gráfica muy útil para trabajar con distribuciones de frecuencias agrupadas en intervalos. El histograma se levanta construyendo sobre cada intervalo de clase de la variable un rectángulo cuya área sea proporcional a la frecuencia absoluta o relativa correspondiente al intervalo considerado. La suma de las áreas de todos los rectángulos será, por tanto, igual a la frecuencia total N. El modelo matemático de un histograma de frecuencias está basado en una tabla de distribución de frecuencias:
Como se observa en el
gráfico, tomaremos las frecuencias relativas como nuestra variable dependiente
y la clase y marca de clase como nuestra variable dependiente.
Diagrama de barras
Según (Eudave Muñoz, Daniel 2017), se utiliza para resaltar la representación de porcentajes de datos que componen un total. Una gráfica de barras contiene barras verticales que representan valores numéricos, generalmente usando una hoja de cálculo. Son una manera de representar frecuencias las cuales están asociadas con categorías. Una gráfica de barras se presenta de dos maneras: horizontal o vertical. El objetivo es poner una barra de largo igual a la frecuencia.
Su modelo matemático está basado en una tabla de distribución de frecuencias, donde la frecuencia relativa y la frecuencia acumulada tomaran los valores de Y, mientras que la clase tomará los valores de X, como se observa a continuación:
Estimadores de centralización
Según (L. C. Torres, A. G. Rodríguez, J. M. A. Cáceres, G. S. D. Veloz, M. K. B. Rivera, y R. M. A. Flores, 2018), son medidas estadísticas que se usan para describir cómo se puede resumir la localización de los datos. Ubican e identifican el punto alrededor del cual se centran los datos. Las medidas de tendencia central nos indican hacia donde se inclinan o se agrupan más los datos. Las más utilizadas son: la media, la mediana y la moda.
La media, también llamada promedio o simplemente media es el valor característico de una serie de datos cuantitativos, objeto de estudio, se fundamenta en el concepto de la esperanza matemática o valor esperado, se obtiene de la suma de todos sus valores dividida entre el total de datos (L. C. Torres, A. G. Rodríguez, J. M. A. Cáceres, G. S. D. Veloz, M. K. B. Rivera, y R. M. A. Flores, 2018). Su modelo matemático es el siguiente:
La mediana es el valor que divide al conjunto ordenado de datos, en dos subconjuntos con la misma cantidad de elementos. La mitad de los datos son menores que la mediana y la otra mitad son mayores. Su modelo matemático consta de dos situaciones (L. C. Torres, A. G. Rodríguez, J. M. A. Cáceres, G. S. D. Veloz, M. K. B. Rivera, y R. M. A. Flores, 2018).
Para un número impar de elementos n:
Para un número par
de elementos n:
Coeficiente de correlación
Según (Martínez O., R. M., Tuya P., L. C., Martínez O., M., Pérez A., A., Cánovas, A. M., 2014), la correlación, también conocida como coeficiente de correlación lineal (de Pearson), es una medida de regresión que pretende cuantificar el grado de variación conjunta entre dos variables. Por tanto, es una medida estadística que cuantifica la dependencia lineal entre dos variables, es decir, si se representan en un diagrama de dispersión los valores que toman dos variables, el coeficiente de correlación lineal señalará lo bien o lo mal que el conjunto de puntos representados se aproxima a una recta. De una forma menos coloquial, la podemos definir como el número que mide el grado de intensidad y el sentido de la relación entre dos variables.
Su modelo matemático está dado por:
Donde cada parte
corresponde a:
La varianza nos permite identificar la
diferencia promedio que hay entre cada uno de los valores respecto a su punto
central. Este promedio es calculado, elevando cada una de las diferencias al
cuadrado, y calculando su promedio o media; es decir, sumado todos los
cuadrados de las diferencias de cada valor respecto a la media y dividiendo
este resultado por el número de observaciones que se tengan (Michaux, R. P
2015). Su modelo matemático está dado por:
Donde (S2) representa la varianza, (Xi) representa cada uno de los valores, (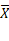 ) representa la media de la muestra y (n) es el número de observaciones ó tamaño de la muestra.
) representa la media de la muestra y (n) es el número de observaciones ó tamaño de la muestra.
La desviación estándar nos permite determinar el promedio aritmético de fluctuación de los datos respecto a su punto central o media. La desviación estándar nos da como resultado un valor numérico que representa el promedio de diferencia que hay entre los datos y la media. Para calcular la desviación estándar basta con hallar la raíz cuadrada de la varianza (Michaux, R. P 2015). Su modelo matemático sería:
La covarianza es el valor que refleja en
qué cuantía dos variables aleatorias varían de forma conjunta respecto a sus
medias. Su modelo matemático obedece a la siguiente ecuación:
Dónde la y con el
acento es la media de la variable Y, y la x con el acento es la media de la
variable X. También “i” es la posición de la observación y “n” el número total
de observaciones [8].
Polígono de frecuencias
Según (Llamosa R., L. E., Gómez E., del C. J., Ramírez B., A. F. 2019), un polígono de frecuencias se forma uniendo los extremos de las barras de un diagrama de barras mediante segmentos. También se puede realizar trazando los puntos que representan las frecuencias y uniéndolos mediante segmentos.
Estimadores de posición
Según (Cevallos Torres L. y Botto Tobar M., 2019.), los cuartiles son los tres valores de la variable que dividen a un conjunto de datos ordenados en cuatro partes iguales. Basándonos en una tabla de frecuencias acumuladas, podemos aplicar el modelo matemático para el cálculo del Cuartil:
El rango intercuartil IQR es una
estimación estadística de la dispersión de una distribución de datos. Consiste
en la diferencia entre el tercer y el primer cuartil. Mediante esta medida se
eliminan los valores extremadamente alejados (Cevallos Torres L. y Botto Tobar M., 2019.). Se puede aplicar el siguiente
modelo matemático para su cálculo:
Los deciles son los nueve valores que
dividen la serie de datos en diez partes iguales. Para el cálculo de éstos
podemos aplicar el siguiente modelo matemático (Cevallos Torres L. y Botto Tobar M., 2019.):
Los percentiles son los 99 valores que
dividen la serie de datos en 100 partes iguales. Se los puede calcular mediante
el modelo matemático (Cevallos Torres L. y Botto
Tobar M., 2019.):
Diagrama de caja y bigote
Según (Escalante C. y Arango G., 2004), los diagramas de Caja-Bigotes son una presentación visual que describe varias características importantes, al mismo tiempo, tales como la dispersión y simetría. Para su realización se representan los tres cuartiles y los valores mínimo y máximo de los datos, sobre un rectángulo, alineado horizontal o verticalmente. Para construir un diagrama de caja y bigote se debe seguir le siguiente modelo matemático:
Donde:
El bigote de la izquierda representa al colectivo de edades (L1, Q1). La primera parte de la caja a (Q1, Q2), la segunda parte de la caja a (Q2, Q3). El bigote de la derecha viene dado por (Q3, L2).
Momento central
Según (Ferrando J. P. y Anguiano Carrasco C., 2010), en estadística el momento central o centrado de orden k de una variable aleatoria X es la esperanza matemática E [(X − E[X]) k] donde E es el operador de la esperanza. Si una variable aleatoria no tiene media el momento central es indefinido. Su modelo matemático en base a lo mencionado es:
Normalmente la letra
griega para el momento central es μ. El primer momento central es cero y el
segundo se llama varianza (σ²) donde σ es la desviación estándar. El tercer y
cuarto momentos centrales sirven para definir los momentos estándar denominados
de asimetría y de curtosis.
Oblicuidad
Según (Ferrando J. P. y Anguiano Carrasco C., 2010), en probabilidad, la oblicuidad es una medida de que tan asimétrica es una distribución alrededor de su media. Debido a la tercera potencia involucrada en su cálculo, también se le llama tercer momento de la distribución. Para el cálculo de la Oblicuidad se emplea el siguiente modelo matemático:
Donde N es el número
total de elementos de la distribución, Xi es el elemento i, 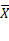 es la media y es la desviación estándar.
es la media y es la desviación estándar.
Curtosis
Según (S. Ramos M. Á., 2005), la curtosis (o apuntamiento) es una medida de forma que mide cuán escarpada o achatada está una curva o distribución. Este coeficiente indica la cantidad de datos que hay cercanos a la media, de manera que, a mayor grado de curtosis, más escarpada (o apuntada) será la forma de la curva. Su modelo matemático está dado por:
Donde ni es la frecuencia absoluta de xi o de cada intervalo i.
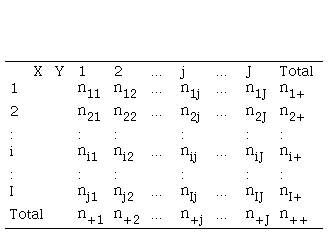
Tabla de contingencia
Según (Sánchez R., M. Á., 2015), una tabla de contingencia es una tabla que cuenta las observaciones por múltiples variables categóricas. Las filas y columnas de las tablas corresponden a estas variables categóricas.
Su modelo matemático es creado a partir de dos dimensiones, constituida de I filas, indexadas por i, con i =1 hasta I, y de J columnas, indexadas por j, con j =1 hasta J, que cruza dos variables cualitativas Y ,y X:
Sintaxis de tabla de
contingencia N (I, J)
|
|
X
Y
|
1
|
2
|
…
|
j
|
…
|
J
|
Total
|
|
1
| n11 | n12 |
…
| n1j |
…
| n1J | n1+ |
|
2
| n21 | n22 |
…
| n2j |
…
| n2J | n2+ |
|
:
|
:
|
:
| |
:
| |
:
|
:
|
|
i
| ni1 | ni2 |
…
| nij |
…
| niJ | ni+ |
|
:
|
:
|
:
| |
:
| |
:
|
:
|
|
I
| nj1 | nj2 |
…
| nIj |
…
| nIJ | nI+ |
|
Total
| n+1 | n+2 |
…
| n+j |
…
| n+J | n++ |
Otra forma de expresar el modelo matemático para una tabla de
contingencia es el siguiente, donde los valores a, b, c y d, son las
frecuencias absolutas (Sánchez R., M. Á., 2015).
Esquema de una tabla de
contingencia 2x2

|
Esquema de una tabla de
contingencia 2x2
|
| | |
Total
|
|
A
|
b
|
a + b
|
|
C
|
d
|
c + d
|
|
Total
|
a + c
|
b + d
|
a +b +c +d
|
| | | |
Antecedentes
Uno de los principales trabajos previos corresponde a los Dres. Eduardo A. Valenti y Carla Otero, quienes lo realizaron bajo el título “Mortalidad Fetal 2006 en la Maternidad Sardá”. La investigación fue elaborada tomando una muestra de 7220 nacimientos de los cuales 62 resultaron ser muertes fetales. En este caso, se pudo establecer las causas de muerte fetal más frecuentes, y el porcentaje de fetos muertos que fueron afectados por causas específicas.
Este proyecto guarda una estrecha relación con el nuestro ya que aplicó conceptos estadísticos, tales como frecuencia y porcentaje, en el desarrollo y presentación de la información. Se espera que éste trabajo sirva como fundamento para sentar las bases de la presente investigación en curso.
Parte estadística
En nuestro trabajo fue necesario recopilar 6 variables, 3 cualitativas y 3 cuantitativas, estas variables se organizaron en tablas de frecuencia, se calcularon los intervalos de frecuencia necesarios y se diseñaron histogramas de frecuencia, además del cálculo de la media y la varianza para las variables cuantitativas, mientras que para aquellas variables cualitativas se confeccionó diagramas de barra. Dado la relación establecida entre estas 6 variables, también se realizó tabla de contingencia, coeficiente de correlación para comparar y analizar ambos valores.
Programas
Según (Pérez G., L. O 2016), durante el desarrollo de nuestro proyecto utilizamos softwares informáticos que nos ayuden a manipular información extensa. Para la recopilación de la información se empleó Microsoft Excel que es un programa informático desarrollado y distribuido por Microsoft Corp. Éste es un software que permite realizar tareas contables y financieras gracias a sus funciones, desarrolladas específicamente para ayudar a crear y trabajar con hojas de cálculo.
Y según (Ruiz R., A. M., Puga, J. L 2016), para la recopilación y análisis de la información, se empleó R.Studio, que es uno de los entornos más populares para crear aplicaciones en el lenguaje de programación R. Este entorno de desarrollo tiene una versión gratuita, open source y multiplataforma de escritorio para disponer de un entorno integrado de desarrollo, y que facilita tanto la tarea de uso interactivo de R como la programación de scripts en R. para el respectivo análisis y presentación de la información recopilada previamente.
Recolección de datos
Los datos fueron obtenidos de una base de datos del INEC (Instituto Nacional de Estadística y Censo), en dicha base de datos se encuentran registradas las defunciones fetales ocurridas por provincia, cantón y parroquia, además también se registran estas defunciones por año de ocurrencia, y nos permite revisar el período de gestación de cada feto antes de su muerte.
Análisis de datos
Nuestro proyecto fue desarrollado aplicando métodos estadísticos, principalmente se empleó tablas de frecuencia y tabla de contingencia para organizar y analizar los datos. Estos datos fueron pasados a través de un diagrama de barras (en los casos donde intervenían variables cualitativas), y también a través de histograma de frecuencias, (en los casos donde solo intervenían variables cuantitativas). Además, las variables cuantitativas fueron analizadas por coeficiente de correlación.
Mediante la utilización de estos métodos estadísticos nos fue posible, así mismo, presentar las relaciones que existen entre la edad de la madre y el periodo de gestación del feto antes de su defunción. Se consideró la relación entre las diferentes provincias, cantones y parroquias y las fechas en las cuales ocurrieron las defunciones. De esta forma se obtuvo las fluctuaciones que se han presentado a lo largo de las parroquias ubicadas en zonas suburbanas, y la relación que éstas tienen con el tiempo de vida que llega a tener un feto antes de morir.
CASOS DE ESTUDIO
Para el programa se empleó una computadora de escritorio marca Xtratech. Toda información relevante de nuestro trabajo fue recopilado y analizado mediante esta máquina. Para el proceso final de presentación, se volvió necesaria la inclusión de una nueva máquina que agilizara los procesos de análisis de la información, en este caso, una HP Pavilion notebook.
La inclusión de
otras herramientas tipo software en el trabajo también fue necesaria ya que,
estos programas ayudaron a obtener resultados más rápidos. Estas herramientas
se encargaron de estudiar y calcular la información ya recopilada desde el
INEC, y arrojar el resultado más práctico. (Cevallos Torres L.
y Botto Tobar M. , 2019; Valencia Nunez
E. R., Melendez Tamano C.
F., Valle Alvarez A. T. , Paredes Salinas J. G., P.
Salinas C. F., y Cevallos-Torres L. J., 2017).
Algoritmos utilizados
Para el desarrollo
de los métodos estadísticos en nuestro trabajo, fue necesario emplear los
siguientes algoritmos en el lenguaje de programación R.
Algoritmo 1. Coeficiente de Correlación:
edad de madre y periodo de gestación
Algoritmo
2. Tabla
de Frecuencia de Edad de la Madre
Algoritmo
3. Histograma
de Frecuencias para Edad de la madre
Algoritmo
4. Polígono
de Frecuencias para Edad de la madre
Algoritmo
5. Cálculo
de métodos estadísticos (media, mediana, distancia, diferencia, desviación
estándar, momento central)
Algoritmo
6. Diagrama
de cajas y bigote
Algoritmo
7. Cálculo
de Oblicuidad y Curtosis
RESULTADOS Y DISCUSIÓN
Primero se buscó establecer las relaciones entre las defunciones fetales tomando como base el lugar donde fueron registrados. Para eso creamos 3 diagramas de barra, relacionando los datos por provincia, cantón y parroquia respectivamente. Los resultados obtenidos fueron los siguientes:
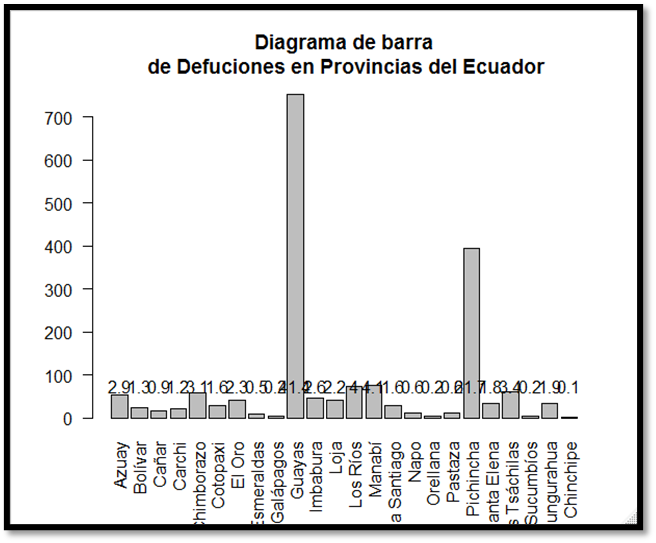 Figura 1.
Concentración de
defunciones.
Figura 1.
Concentración de
defunciones.
Para la figura 1, se observó que la mayor concentración de defunciones
fueron registrada en las provincias de Guayas y Pichincha. Podemos destacar que
Guayaquil (el cual es un cantón del Guayas) es uno de los cantones con mayor
zona suburbana del país.
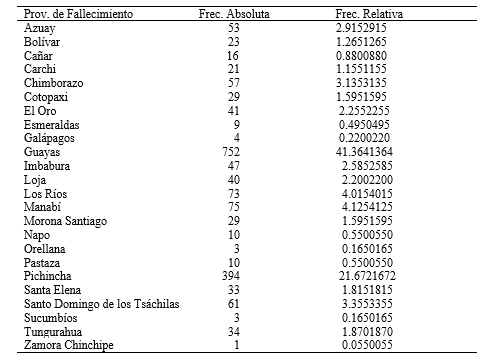 Tabla 1.
Frecuencia de las defunciones fetales por provincia.
Tabla 1.
Frecuencia de las defunciones fetales por provincia.
En la tabla 1, se presentan la frecuencia de las defunciones fetales por
provincia, donde podemos observar que sólo dos frecuencias alcanzan las 3
cifras, siendo éstas Guayas y Pichincha. Cabe recalcar que estas provincias son
las que contienen el mayor número de habitantes del país.
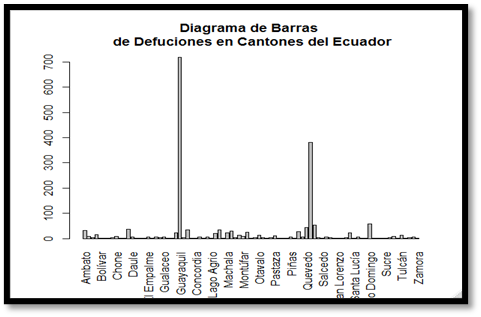 Figura 2.
Figura 2.
Defunciones por
cantones.
Corroborando los resultados obtenidos de la figura 2, Guayaquil
efectivamente registra la mayor cantidad de defunciones. Para comprobar que la
mayoría de éstas se dan el sur de la urbe porteña, es necesario analizar
gráficamente las parroquias que la conforman.
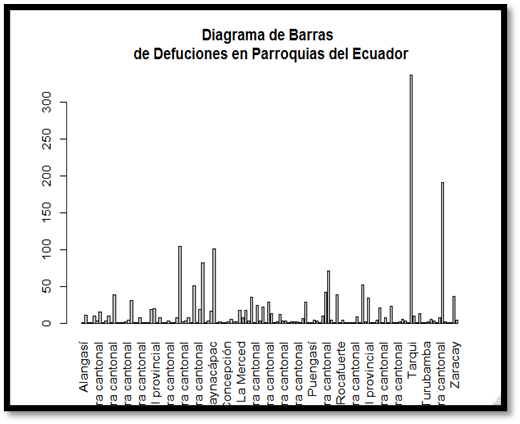 Figura 3.
Defunciones por
parroquias.
Figura 3.
Defunciones por
parroquias.
En la figura 3, los resultados presentados en función de las parroquias
terminan negando rotundamente lo establecido en nuestros objetivos. Se puede
observar que la parroquia Tarqui, la cual abarca gran parte del norte de la
ciudad de Guayaquil, es la que registra la mayoría de las defunciones fetales
ocurridas. Esto indica que la zona sur (mencionada como zona suburbana en
nuestro trabajo), no presenta un índice de defunción tan alto, aún siendo esta
la zona donde se registra mayor cantidad de embarazos.
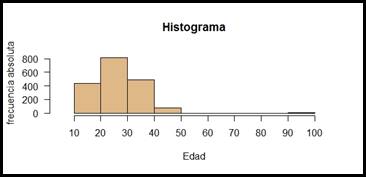 Figura 4.
Frecuencia de
edades.
Figura 4.
Frecuencia de
edades.
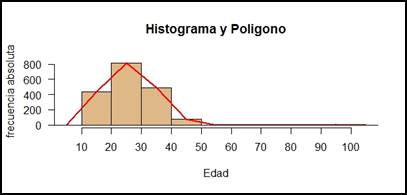 Figura 5.
Distribución de
edades.
Figura 5.
Distribución de
edades.
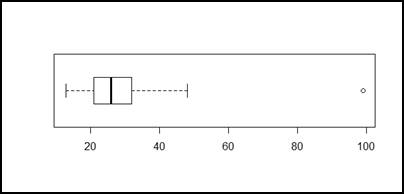 Figura 6.
Frecuencia de
edades.
Figura 6.
Frecuencia de
edades.
De las figuras 4, 5 y 6 obtenemos las
representaciones generales de defunción por edad, los resultados siguen
indicando a mujeres jóvenes, y por ende en óptimo estado para un posterior
embarazo, como las principales víctimas de defunción fetal.
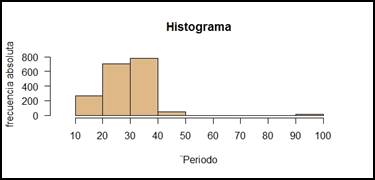 Figura 7.
Periodo de
supervivencia.
Figura 7.
Periodo de
supervivencia.
 Figura 8.
Distribución de
periodo de supervivencia.
Figura 8.
Distribución de
periodo de supervivencia.
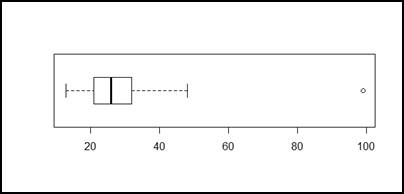 Figura 9.
Periodo de
supervivencia.
Figura 9.
Periodo de
supervivencia.
De la figura 7, nuestros resultados arrojan un máximo de 40 días de supervivencia del feto, existe una minoría de casos donde éste ha sobrevivido hasta 50 días.
De las figuras 8 y 9 igualmente observamos un valor pico de 35 días, luego de esta etapa la gran mayoría de fetos mueren. Considerando estos resultados podemos determinar un alto riesgo de aborto antes de los 35 días de gestación.
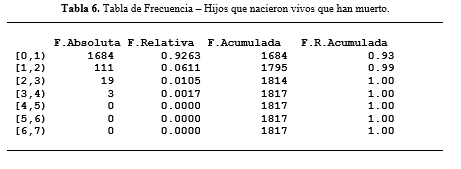
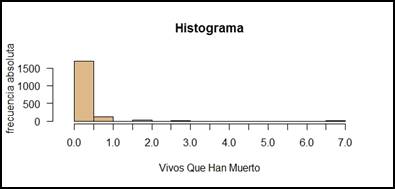 Figura 10.
Vivos que han
muerto.
Figura 10.
Vivos que han
muerto.
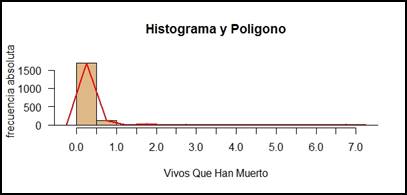 Figura 11.
Frecuencia de
vivos que han muerto.
Figura 11.
Frecuencia de
vivos que han muerto.
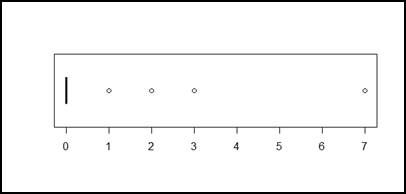 Figura 12.
Vivos
que han muerto.
Figura 12.
Vivos
que han muerto.
Para los resultados obtenidos de la figura 10, y 11 notamos un alarmante índice de bebés que fallecieron tiempo después de su nacimiento, su valor pico está dado por neonatos mayoritariamente de menos de 6 meses de edad.
De la figura 12, podemos determinar que han fallecido también bebés entre 1, 2, y 3 años, aunque estos son relativamente una minoría.
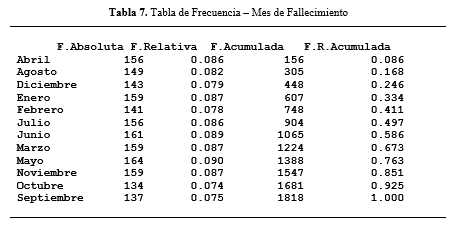
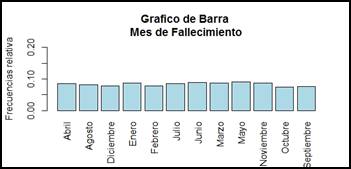 Figura 13.
Mes de
fallecimiento.
Figura 13.
Mes de
fallecimiento.
Ya para finalizar, debido a que no se pudo determinar que las fluctuaciones se vean afectadas por el lugar de concepción, ni por la edad de la madre. De los resultados obtenidos del gráfico 13, podemos observar que existe una media similar entre los doce meses del año y las defunciones fetales ocurridas durante los mismos. Así, la época del año no es un factor relevante en la defunción fetal.
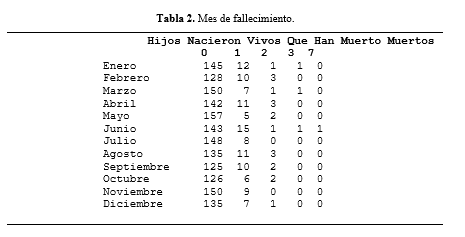
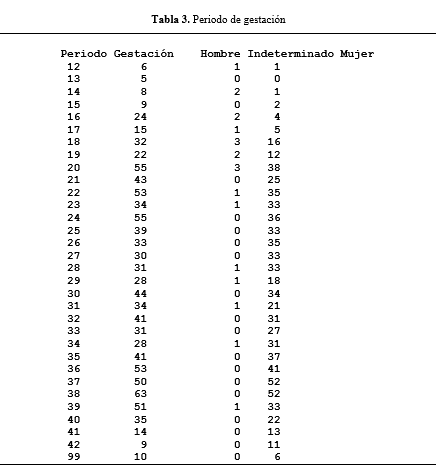
Debido a que no fue posible confirmar que exista alguna influencia del lugar de concepción en la defunción fetal. Se procedió a realizar una tabla de contingencia tomando como variables el mes de fallecimiento y los hijos que nacieron vivos y han muerto, con esto se busca hallar alguna relación posible entre la época del año y la supervivencia de un neonato. Tal como se observa en las tablas 2 y 3.
De las tablas de contingencia previas, se obtuvo el sguiente diagrama de
dispersión, donde podemos observar que r se acerca al valor de 0, lo que
significa que no hay una relación lineal entre ambas variables. Dando por
finalizado nuestro intento de establecer una influencia entre algún factor
externo con la defunción fetal ocurrida. Tal como observamos en la figura 14.
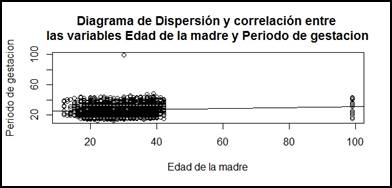 Figura 14.
Dispersión de
muertes.
Figura 14.
Dispersión de
muertes.
De esta figura (14), los resultados arrojados fueron que el coeficiente de correlación es de 0,072. Por lo que demostramos lo mencionado anteriormente. La varianza entre ambas variables es de 5.3, y se puede observar que no hay correlación entre la edad y el periodo de gestación.
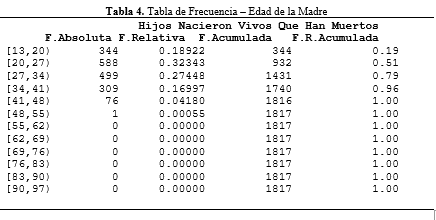
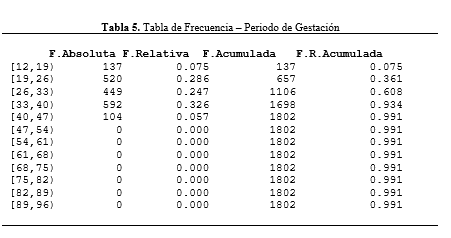
Por último, queremos presentar tablas de frecuencia donde se pueda observar de forma organizada los datos usados en los gráficos previos.
CONCLUSIONES
Una vez obtenidos los resultados se puede concluir que, la mayor cantidad de defunciones fetales ocurren en lugares con alta cantidad de habitantes, tales como las provincias de Guayas y Pichincha. Debido a que Guayaquil es la ciudad más habitada del país, también es la que presenta la mayor cantidad de defunciones fetales. Sin embargo, la mayoría de éstas se registraron en la parroquia Tarqui, al norte de la ciudad, lo que indica que las zonas suburbanas (particularmente el ambiente que existe en ellas), no influye en el desarrollo del feto. Tampoco influye el mes en el cual se concibe al feto, ni siquiera la edad de la madre, puesto que el rango de defunciones fetales por edad indica que éstas ocurren mayoritariamente durante el período normal en el cual toda mujer puede quedar encinta (entre los 20 y 30 años).
Considerando todo esto, podemos decir finalmente que una defunción fetal puede ocurrir en cualquier momento de forma inesperada, no existe ningún factor geográfico relevante que pueda influir de manera negativa en el desarrollo de un feto. En pocas palabras, aquella provincia, cantón, parroquia, o país, donde hay más población de mujeres, será aquel donde se registren a su vez mayor cantidad de defunciones fetales.
REFERENCIAS BIBLIOGRÁFICAS
G. Castañeda-Casale, H. Márquez-González, y E. R. Rodr\’\iguez-Reyes, «Mortalidad perinatal en un hospital de segundo nivel de atención», Rev. Med. Inst. Mex. Seguro Soc., vol. 48, n.o 3, pp. 237-242, 2010.
J. Linares y R. Poulsen, «Muerte fetal in útero: Etiología y factores asociados en un hospital regional de Antofagasta, Chile», CIMEL Cienc. e Investig. Médica Estud. Latinoam., vol. 12, n.o 1, pp. 7-10, 2007.
A. M. Gutiérrez Á.; Y. L. Babativa; I. Lozano (2014). Universidad del Rosario Bogotá, Colombia. Presentación de datos. Revista Ciencias de la Salud, vol. 2, núm. 1, pp. 65-73.
H. Casanova, «Graficación Estadística y Visualización de Datos.», Ingeniería, vol. 21, n.o 3, pp. 54-75, 2017.
Eudave Muñoz, Daniel (2017). Grupo Santillana México Distrito Federal, México. El aprendizaje de la estadística en estudiantes universitarios de profesiones no matemáticas Educación Matemática, vol. 19, núm. 2, pp. 41-66.
L. C. Torres, A. G. Rodríiguez, J. M. A. Cáceres, G. S. D. Veloz, M. K. B. Rivera, y R. M. A. Flores, «Análisis estadístico de correlación entre las dosis de eritropoyetina y el nivel de hemoglobina en pacientes con insuficiencia renal crónica», Rev. la Fac. Ciencias Médicas la Univ. Guayaquil, vol. 19, n.o 1, 2018.
Martínez O., R. M.; Tuya P., L. C.; Martínez O., M.; Pérez A., A.; Cánovas, A. M (2014). El Coeficiente de correlación de los rangos de Spearman Caracterización. Universidad de Ciencias Médicas de La Habana Ciudad de La Habana, Cuba. Revista Habanera de Ciencias Médicas, vol. 8, núm. 2.
Michaux, R. P (2015). Conceptos Estadísticos básicos: Una aproximación teórico-práctica (parte II). Sociedad Argentina de Radiología Buenos Aires, Argentina. Revista Argentina de Radiología, vol. 69, núm. 1, pp. 57-63.
Llamosa R., L. E.; Gómez E.., J. del C..; Ramírez B., A. F (2019). Metodología para la estimación de la incertidumbre en mediciones directas. Universidad Tecnológica de Pereira Pereira, Colombia. Scientic Et Technica, vol. XV, núm. 41, pp. 384-389.
L. Cevallos-Torres y M. Botto-Tobar, «Case study: Probabilistic estimates in the application of inventory models for perishable products in SMEs», en Problem-Based Learning: A Didactic Strategy in the Teaching of System Simulation, Springer, 2019, pp. 123-132.
C. Escalante y G. Arango, «Aspectos básicos del modelo de riesgo colectivo», Matemáticas Enseñanza Univ., vol. 12, n.o 2, pp. 3-15, 2004.
P. J. Ferrando y C. Anguiano-Carrasco, «El análisis factorial como técnica de investigación en psicología», Papeles del psicólogo, vol. 31, n.o 1, pp. 18-33, 2010.
M. N. Rodríguez y M. A. Ruiz, «Atenuación de la asimetría y de la curtosis de las puntuaciones observadas mediante transformaciones de variables: Incidencia sobre la estructura factorial», Psicológica Rev. Metodol. y Psicol. Exp., vol. 29, n.o 2, pp. 205-227, 2008.
M. Á. S. Ramos, «Uso metodológico de las tablas de contingencia en la ciencia política», Espac. públicos, vol. 8, n.o 16, pp. 60-84, 2005.
Sánchez R., M. Á (2015). Universidad Autónoma del Estado de México Toluca, México. Uso metodológico de las tablas de contingencia en la ciencia política Espacios Públicos, vol. 8, núm. 16, pp. 60-84.
Pérez G., L. O (2016). Universidad de Ciencias Médicas de Cienfuegos Cienfuegos, Cuba. Microsoft Excel: una herramienta para la investigación. MediSur, vol. 4, núm. 3, pp. 68-71.
Ruiz R., A. M.; Puga, J. L (2016). Consejo General de Colegios Oficiales de Psicólogos Madrid, España. R como entorno para el análisis estadístico en evaluación psicológica Papeles del Psicólogo, vol. 37, núm. 1, pp. 74-79.
Cevallos-Torres, Lorenzo & Botto-Tobar, Miguel (2019).Case Study: Logistical Behavior in the Use of Urban Transport Using the Monte Carlo Simulation Method. 97-110.
Cevallos-Torres, Lorenzo & Botto-Tobar, Miguel (2019).Case Study: Project-Based Learning to Evaluate Probability Distributions in Medical Area. 111-112.
Cevallos-Torres, Lorenzo & Botto-Tobar, Miguel (2019).Case Study: Probabilistic Estimates in the Application of Inventory Models for Perishable Products in SMEs. 123-132.
Cevallos-Torres, Lorenzo. Rodriguez, Guijarro-Rodríguez, Alfonso. Alarcón-Cáceres, José. Delgado-Veloz, Geomayra. Barrera-Rivera, Mirella. & Alvarado-Flores, Ronald. (2016). Análisis estadístico de correlación entre las dosis de eritropoyetina y el nivel de hemoglobina en pacientes con insuficiencia renal crónica. 19(1), 1-7.
Valencia-Nunez, Edinson. Meléndez-Tamano, Carlos. Valle-Alvarez, Alexandra. Paredes-Salinas, Juan. Perez-Salinas, Cristian & Cevallos-Torres, Lorenzo. (2018). Virtual classrooms and their use, measured with a statistical technique: The case of the Technical University of Ambato — Ecuador.
Notas
[1] Consultor independiente.
E-mail: cristopher.barrenot@gmail.com
[2] Investigador Asociado. E-mail: moises.gutierrezp@gmail.com