Resumen: Actualmente existen varios indicadores de las diferentes dimensiones que se determinan a nivel individual en salud oral desde una perspectiva epidemiológica. Dentro de los que corresponden a la patología Caries se consideran entonces los indicadores CPO, ceo, ICDAS entre otros. El CPO es un índice unidimensional que cuenta el número de dientes cariados C, perdidos P y obturados O y cuando debe ser evaluado en un contexto de regresión, es un caso particular de Modelo de Conteo, donde la variable de respuesta refiere al número de veces que un evento ocurre, siendo el evento de conteo la realización de una variable aleatoria no negativa, pudiéndose trabajar con el marco conceptual de la teoría de los Modelos Lineales Generalizados (MLG). En la revisión de la literatura en varios trabajos publicados en revista especializadas de Biomedicina y Epidemiología bien rankeadas no se le presta mucha atención a éstos aspectos, donde no queda muchas veces claro porqué se opta por alternativas al modelo de Poisson, sino que tampoco se trabaja la capacidad de ajuste (ver capacidad predictiva). Los autores muchas veces solamente se dedican a ver las variables y ajustar modelos, resolviéndose por aquellos donde aparecen variables significativas pero que podrían ser muy pobres prediciendo. Este último aspecto es relevante ya que en base a esos modelos los investiga dores terminan elaborando teoría para explicar patologías en función de variables que no son buenas predictoras. Por estos motivos en este trabajo se presentan alternativas a los modelos de conteo básicos y se pone un especial énfasis en la capacidad predictiva de los mismos.
Palabras clave: CPO, modelos de conteo, modelos hurdle, modelos de Poisson, sobredispersión.
Abstract: Currently, tltere are severa! indicators of tite different dimensions that are determined at tite individual leve!in oral healtlt from an epidemiological perspective. Among tltose tita!correspond to tite Caries patltology, tite DFM, ceo, ICDAS indicators are considered. DFM is a one-dirnensional index tita counts tite number of teetlt decayed D, filled F, missing M and when it should be evaluated in a regression context, is a particular case of a counting model, where tite response variable refers to tite number of times an event occurs; this counting event is tite realization of a non-negative random variable, being able to work with the conceptual framework of the theory of the Generalized Linear Models (GLM). Inthe review of the literature in severa! papers published in well-ranked specialized joumals of Biomedicine and Epidemiology, little attention is paid to these aspects,where it is not often clear why the authors opt for altematives to the Poisson model, and they do not work on the adjustment capacity either. Authors often only look at the variables and adjust models, resolving themselves by those where significant variables appear but which could be very poor predicting. This last aspect is relevant since based on these models the researchers then in the discussion end up elaborating theory to explain pathologies based on variables that are not good predictors. ªÁlvarez-Vaz, R. & Massa, F. (2021). Modelos de conteo alternativos para los componentes del CPO en una encuesta de salud bucal en Montevideo, Uruguay. Rev. Fac. Cienc., 10(2), 105-125. DOI: https://doi.org/10. 15446/rev.fac.cienc.vl0n2.80743 bDr. en Ciencias Médicas. Prof. Agregado, Instituto de Estadística, Facultad de Ciencias Económicas y de Administración, Universidad de la República,Uruguay •Autor para la correspondencia: ramon.alvarez@fcea.edu.uy. 'M. Se. en Ingeniería Matemática. Instituto de Estadística, Facultad de Ciencias Económicas y de Administración, Universidad de la República,Uruguay
Keywords: Count models, DMF, hurdle models, overdispersion, Poisson models.
MODELOS DE CONTEO ALTERNATIVOS PARA LOS COMPONENTES DEL CPO EN UNA ENCUESTA DE SALUD BUCAL EN MONTEVIDEO, URUGUAY
Recepción: 28 Junio 2019
Aprobación: 02 Junio 2021
Los problemas de salud en la mayor parte del mundo han cambiado, siendo las enfermedades no transmisibles (ENT) las de mayor prevalencia, donde este nuevo patrón global está estrechamente relacionado a los estilos de vida de las sociedades modernas, (Breilh, 2010). Este cambio también impactó en la salud bucal, siendo las enfermedades bucodentales unos de principales problemas en la salud pública debido a su alta prevalencia e incidencia en todas regiones del mundo, (Petersen, 2004).
Antes de pasar a presentar las patologías bucales mas importantes y los índices para evaluarlas es necesario consignar previamente que en Odontología existe una forma de referirse a las piezas dentales, para las que existe cierta numeración coherente también con la medición de patologías de la mucosa. Las piezas se suelen también agrupar en sextantes (inferiores y superiores) o cuadrantes (inferiores y superiores y a su vez izquierdos y derechos). En la Figura 1 denominada Odontograrna puede verse la disposición de las piezas en la boca, donde las piezas numeradas del 55 al 75 corresponden a la temporarias.
El concepto actual de Caries dental define a la enfermedad como un proceso dinámico localizado en la superficie dentaria cubierta por biopelícula, caracterizado por desequilibrios en los procesos desmineralización remineralización que ocurren constantemente en la cavidad bucal. A lo largo de un determinado período de tiempo, la predominancia de momentos de pérdida mineral de los tejidos duros del diente (principal mente iones calcio y fosfato) para la biopelícula y saliva resulta en el establecimiento de la lesión de Caries (Holst et al., 2001). Algunos componentes del proceso de Caries actúan en la superficie del diente (saliva, biopelícula, dieta, acceso al flúor), mientras que existen otro conjunto de factores que determinan el comportamiento de la persona (conocimiento, actitud, ingresos, nivel educativo y socioeconómico), (Fejerscov, 2004). El proceso de la enfermedad debe ser sujeto a un control permanente a lo largo de la vida con el fin de evitar consecuencias irreversibles en etapas posteriores (Maltz & Jardim, 2010).
Existen varios indicadores de las diferentes dimensiones que se determinan a nivel individual en salud oral que pueden ser considerados a nivel colectivo desde una perspectiva epidemiológica.

Figura 1:Odontograma, Fuente: Salud dental para todos (https://dtdental.co/que-es-un-odontograma-dentall).
Dentro de los que corresponden a la patología Caries se consideran entonces los indicadores ceo, CPO, ICDAS. De los índices que dan cuenta del estado de las piezas dentales, es necesario hacer definiciones y establecer una nomenclatura de los diferentes unidades de observación que se tomarán de ahora en adelante con la siguiente simbología:
Dentro de los que corresponden a la patología Caries se consideran entonces los indicadores ceo, CPO, ICDAS. De los índices que dan cuenta del estado de las piezas dentales, es necesario hacer definiciones y establecer una nomenclatura de los diferentes unidades de observación que se tomarán de ahora en adelante con la siguiente simbología:
• i individuo que puede estar en 1,...,n, j que toma valores en 1,...,8 para el diente, k de 1,...,4 para el cuadrante, g grupo o subpoblación (se podría tener, por ejemplo subopoblaciones: hombres y mujeres) con valores en 1,...,G;
• Las piezas dentales df ·k;
'1'
• Los cuadrantes t/;,.,k (formados por piezas);
• Las superficies de cada pieza sf,j,l
El CPO es un índice unidimensional que cuenta el número de dientes cariados C, perdidos P y obturados O. Ha sido utilizado durante mucho tiempo como una forma de determinar la historia de salud, medido a través de la Caries de un conjunto de individuos. Los valores bajos de CPO indican un buen 'status' de salud oral, mostrando que las piezas dentales tienen poca hstoria de enfermedad. Generalmente las personas tienen, salvo excepciones, un total de 28 -32 piezas, repartidas en 4 cuadrantes, 2 inferiores y a su vez izquierdos y derechos, con un total de 7 piezas por cuadrante. Cuando las personas tienen incluso los terceros molares (lo que se habitualmente se llaman 'muelas deljuicio') se puede tener hasta 32 piezas, con un total de 8 por cuadrante. De esta manera, para una persona en particular se puede evaluar el estado de las piezas a través
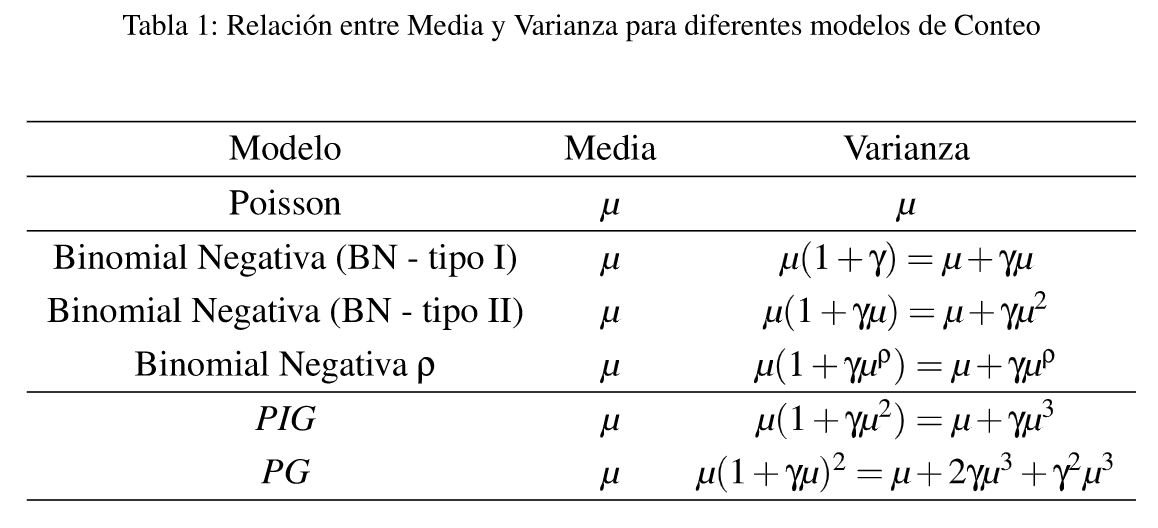
Tabla 1: Relación entre Media y Varianza para diferentes modelos de Conteo
del índice que se detalla en la siguiente ecuación:
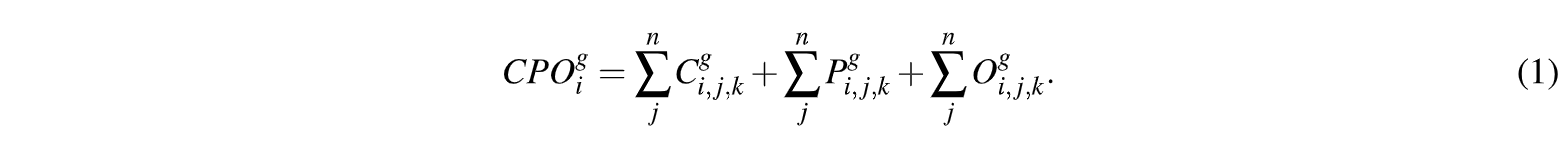
Sin embargo, el primer problema que presenta este indicador es que enmascara toda la variabilidad de las diferentes dimensiones que mide (2 de enfermedad presente (C,P) y 1 de enfermedad pasada pero curada
O. Por ejemplo, un mismo valor de CPO de 12 puede estar indicando situaciones muy diversas, como de una persona con 8 piezas obturadas y 4 con Caries, y de otra con 5 cariadas y 7 perdidas. En ambos casos, los niveles de enfermedad son importantes (tienen 12/28 % de su piezas afectadas, es decir 'no sanas') pero no se sabe si la carga de enfermedad es la misma, ya que las piezas obturadas ponen de manifiesto la enfermedad Caries en el pasado.
Casi tan importante como poder modelar adecuadamente los modelos de conteo es fundamental en primer lugar identificar las posibles distribuciones de probabilidad. Para eso, en la Tabla 1 se presentan diferentes alternativas de modelos de probabilidad, en las que se modula la varianza en función de un factor de inflación y y donde queda por lo tanto determinada una forma de variar la varianza que puede ser lineal como en el caso de la (BN- tipo II) y en forma cuadrática para la (BN-tipo 1).
Para los casos de las PIG y PG las funciones de varianza son polinomios de grado 3 en µ, (Hilbe, 2011). Se puede comenzar por el caso más sencillo, con el Modelo de Poisson (MPoi), que tiene la siguiente función de cuantía, donde y expresa la variable aleatoria de conteo,
Figura 2:Densidad Gamma(«,p) peraparámetroµ en distribución BN,Puente: Elaboración propia.
Cuando existe sobredispersi6n sepuede ttabajarconun modelo (MBN).que es una mela de distribuciones de Poisson. con diferentes µ¡ y el proceso de mezcla está dado por una distribución r para µ, donde
µ ,..., Gamma(a,p), (en realidad es lo que sellamamezcla Poisson-Gamma),es decir:
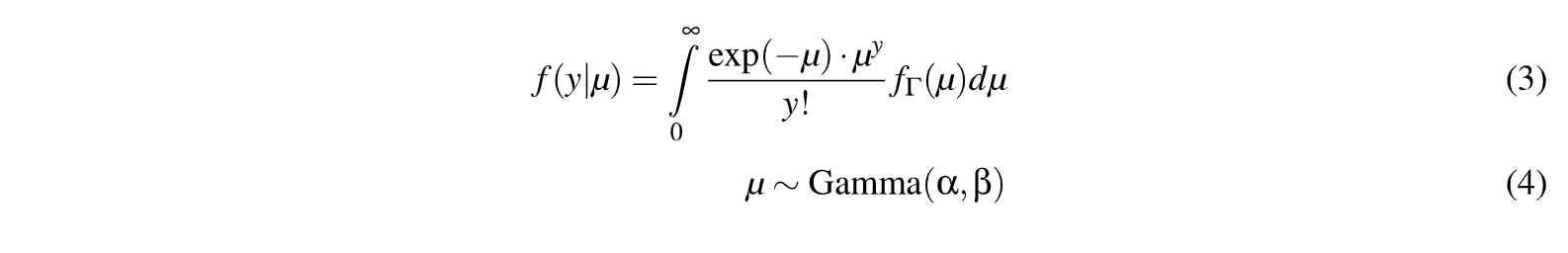
en donde el parámetro acontrola la forma de la distribución y su escala. Además su función de densidad está dada por:
En la Figura 2 puede verse cual una posible forma de variar el parámetro µ, de acuerdo a una distribución
Gamma{a,p).
Manejando la notación de Hilbe (2011), finalmente la Binomial Negativa (BN) de tipo 11se puede expresar
como:
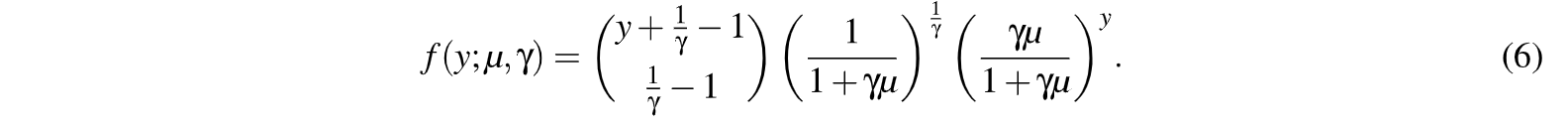
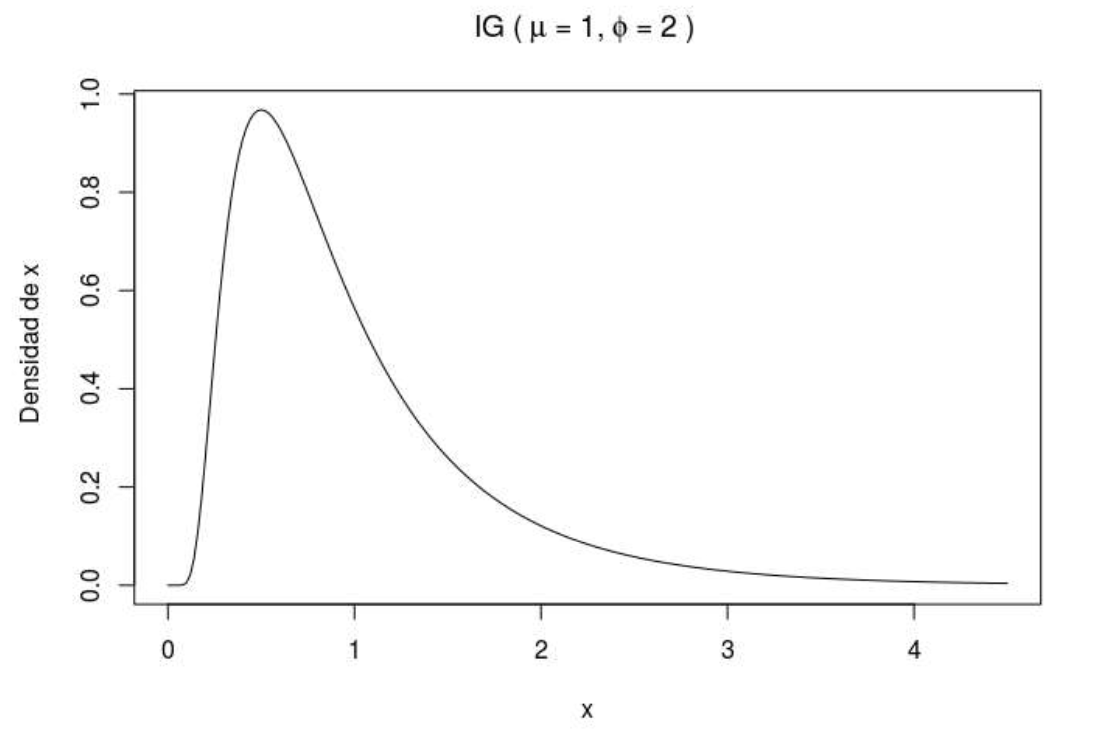
Figura 3:Densidad IG(>t,,),para parámetroµ en distribución PIG, Fuente: Elaboración propia.
Otra distribución de probabilidad para la forma de variar µ es del tipo Inversa Gaussiana(IGau). Es una distribución muy usada en Análisis de Sobrevida en el campo Médico y Actuarial, (Whitmore, 1975;Whitmore y Yalovsky, 1978),caracterizada por ser asimétrica con parámetros de media µy precisión e¡.. Esto da origen a la Poisson Inversa Gaussiana (PIG), que se debe interpretar en forma similar al proceso de mezcla
de Poisson-Gamma para la BN, con la diferencia que en este caso es una mezcla de Poisson y de Inversa Gaussiana, con a = i ,(Giner & Smyth, 2016;Wheeler, 2016).
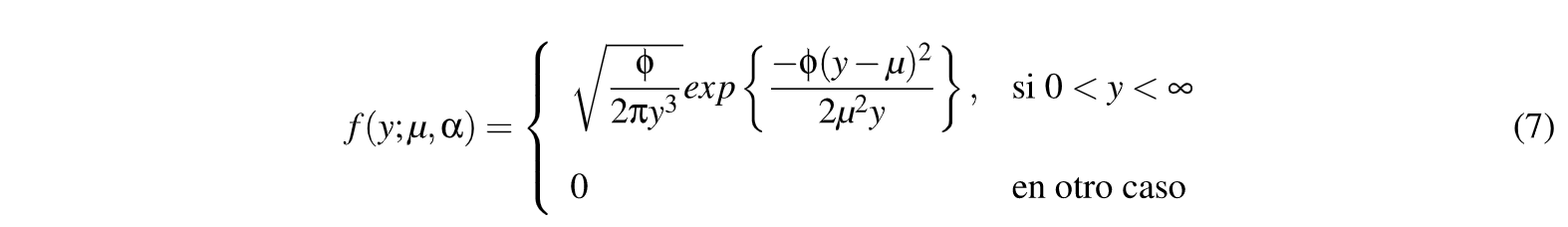
Cuando se presentan datos que muestran que el parámetro de dispersión "( puede no ser fijo a lo largo de todas las observaciones, como es el caso de la BN y la PIG, es necesario incorporar un parámetro extra p que interviene en lo que seconoce como (MBNp).
Si se tiene en cuenta la función de varianza que surge de la Tabla l, para la BN tipo I y la BN tipo Il la diferencia es la siguiente:

es decir, una potencia del término en yµ, donde p debe estimarse junto con el resto de los parámetros (Hilbe, 2011).
Por último, si bien es poco frecuente encontrar datos con subdispersión, existe otra alternativa de distribución de Probabilidad que es la PG, que tiene la siguiente expresión, con 0 > O y llBI < 1:
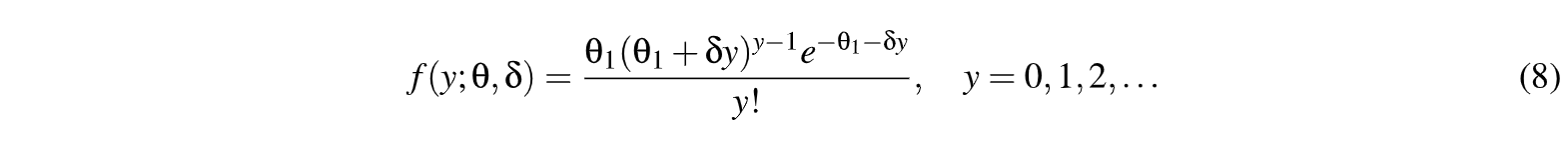
n Hilbe (2011), el autor presenta un estudio sobre tiempo en días de internación (TDI) de pacientes con patología coronaria que reciben 2 tipos de procedimientos quirúgicos, los que muestran tener una media para TDI de 8.8 y un desvío éstandar de 6.9, que muestra una sobre dispersión de 3.2. Sin embargo de los 3589 observaciones originales se intenta modelar el TDI de los que tienen menos de 8 días, siendo 1982 pacientes que verifican esa restricción mostrando una media de TDI de 4.4, con un desvío estándar de 2.30, con una dispersión de 0.79, lo que indica que no es conveniente en el contexto de regresión usar un MPoi o un MBN, con lo cual una alternativa es precisamente usar la distribución PG.
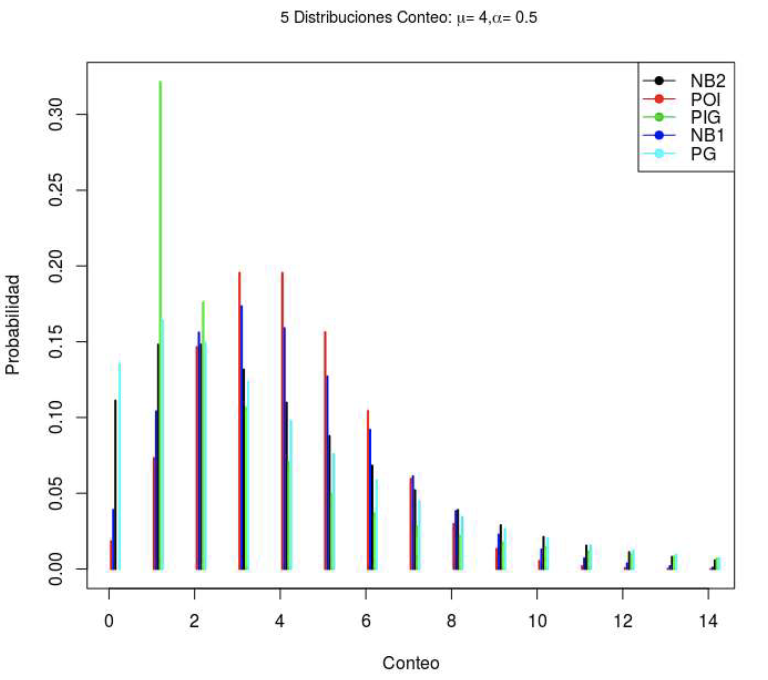
Es importante entonces, más allá de ver concretamente cada modelo antes planteado, compararlos visual mente, por lo cual para un valor dado de µ = 4 y y= 0.5, se presenta como se diferencian entre éstos.
Sin embargo, en la práctica se encuentran datos que presentan otras patologías como son el exceso de ceros o dado el problema, la no presencia de ceros como puede ser por ejemplo: los clásicos estudios de días de internación (donde se puede definir que el núnimo es 1), donde por definición el recorrido está truncado. Para eso se puede recurrir a los modelos que siguen.
2.1. Modelos Hurdle (MH)
Los MH o Hurdle Models, que podrían considerarse como modelos con obstáculos, son aquellos que com binan dos procesos de conteo, uno para los ceros , con f=(y;z,y) (censurado por la derecha en y = 1) y otro para conteos positivos (> O). foon 1(y;x, p) (truncado por la izquierda en y = 1), que puede ser de tipo Poisson, o Binomial Negativo, (Mullahy, 1986; Cameron, 1998).
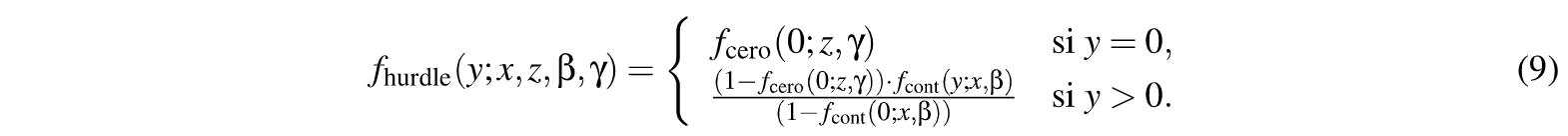
Los parámetros del modelo p, y, y potenciales parámetros de dispersión 9 (si /cont o /rero o ambos con densidad negativa binomial) se estiman por Máxima Verosimilitud, donde la especificación de la verosimi litud tiene la ventaja de que los componentes del conteo y de hurdle pueden maximizarse en forma separada.
La regresión sobre la media es:

2.2. Modelos con Exceso de Ceros (MEC)
Los MEC (de tipo Poisson (PEC), Binomial Negativa (BNEC)) son modelos de mezcla, que combinan un componente de conteo y una masa de probabilidad en cero, con el restante modelo para los conteos > O (Cameron, 1998; Hilbe, 2011).
En este caso, hay dos fuentes de cero para el modelo, provenientes de la masa puntual en cero /{o} (y) y del modelo de conteo con distribución fcont(y;x, p). La probabilidad de observar un conteo de cero se incrementa con probabilidad 7t = frero(O; z,y)
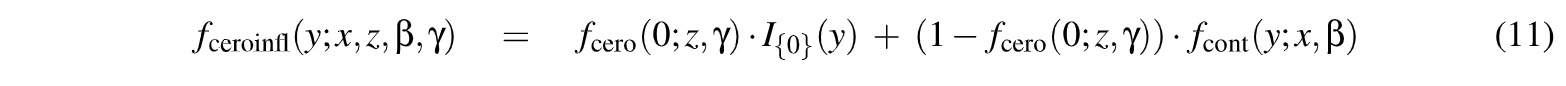
donde I(·) es la función indicadora y la probabilidad no observada 7t de pertenecer al componente de masa puntual se modela con un MLG de tipo binomial 7t = g- 1(zTy).
La ecuación de regresión para la media es
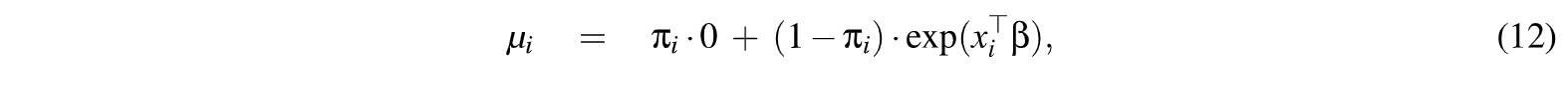
usando la función de enlace canónico.
A partir de los diferentes alternativas de modelos planteados hasta aquí se busca el objetivo de identificar los modelos de probabilidad que mejor ajustan al componente C del CPO, de los planteados en la Tabla 1, para luego en contextos de modelos de regresión ver cual es la mejor alternativa, que puede ser un modelo sencillo al trabajar con una sola distribución de probabilidad o modelos más complejos, necesarios para el caso de que exista sobredispersión y exceso de ceros.
Tabla 2: Conjunto de variables regresoras usadas para los modelos de conteo en RPAF02015
Para evaluar cómo funcionan las distribuciones y los modelos antes presentados, se trabaja con los dalos provenientes del 'Relevarnienlo en población que se asiste Facultad de Odontología 2015 (RPAF02015)' estudio sobre personas que demandan atención en la Facultad de Odontología de la Universidad de la Re pública, Uruguay d, donde se analiza el componente C, tratando de identificar su distribución, para luego estimar modelos de regresión usando las siguientes variables explicativas. Este estudio se aplicó a una muestra de 602 personas que consultan en el período que corresponde a mayo 2015-junio 2016, que se seleccionan mediante muestreo sistemático, se les aplica un cuestionario sociodemográfico y un examen completo de la boca, en donde se evalúa el estado de las piezas dentales y de la mucosa, además de medidas antropo métricas, de Presión Arterial (PA) y de glicemia (Gli). El tamaño muestral se determinó para poder medir prevalencias de hasta 25 % con un margen de error ¡¡= 0.05 y un nivel de confianza 1-a = 0.95 y cubrir hasta una tasa de no respuesta del 90 %. Finalmente, de los 640 originalmente calculados, se obtuvieron 602, que representa una fracción de muestreo de alrededor del 1O % del total de personas que consultan anualmente.
Se detallan las variables explicativas que se usarán para modelar los diferentes componentes del CPO en la Tabla 2.
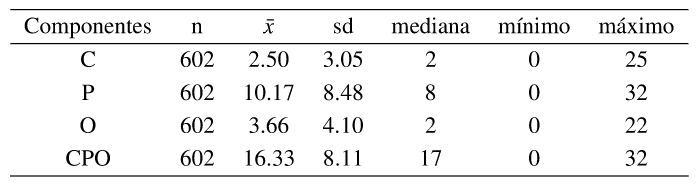
Tabla 3:Medidas deresumende los compo de CPO
Figura 5:Distribución parael CPO y sus 3 componentes, Fuente: Elaboración propia.
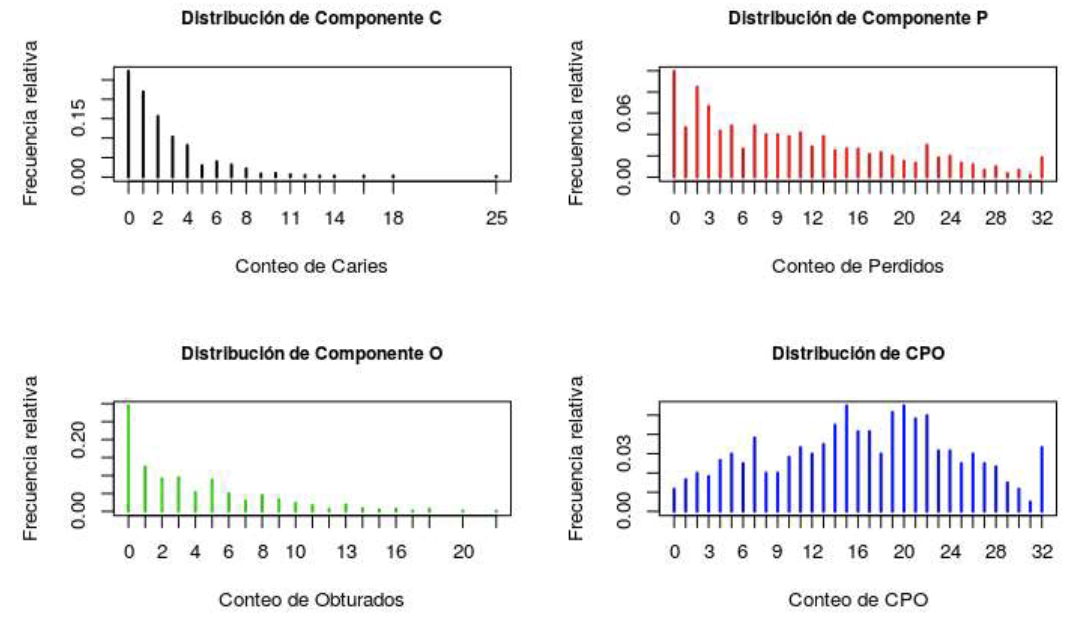
Figura 5:Distribución parael CPO y sus 3 componentes, Fuenk::Elaboración propia.
En principio, en la Tabla 3, se tiene la distribución para los tres componentes y el CPO. Si bien se estiman modelos para los tres component.es y el CPO, se muestra con particular detalle lo referente al componente C,dada la forma que presenta en este caso para los datos de la RPAF02015 y la importancia que desde el punto de vista epidemiológico tiene.
Usando las librerías COUNT, (Hilbe, 2016) y gamlss (Rigby & Stasinopoulos, 2005) del software R Core Team (2016), se puede estimar la mejor distribución paramétrica para ajustar la variable C. Si bien en los resultados aparecen modelos que consideran infiación de O. solamente se presentan los cinco modelos pará metricos vistos en la sección 2.
En la Figura 6 se presentan los ajustes hechos para el component.e C, considerando que el parámetro µ estimado por la media muestra! x = 2.5, lo que llevaa tener que evaluar una mejor alternativa, siendo que el PG es el mejor, tal come se ve en la Tabla 4, donde aparece el criterio de ajuste por el estadístico AJC y la
Figura 7, que muestra que es la mejor alternativa.
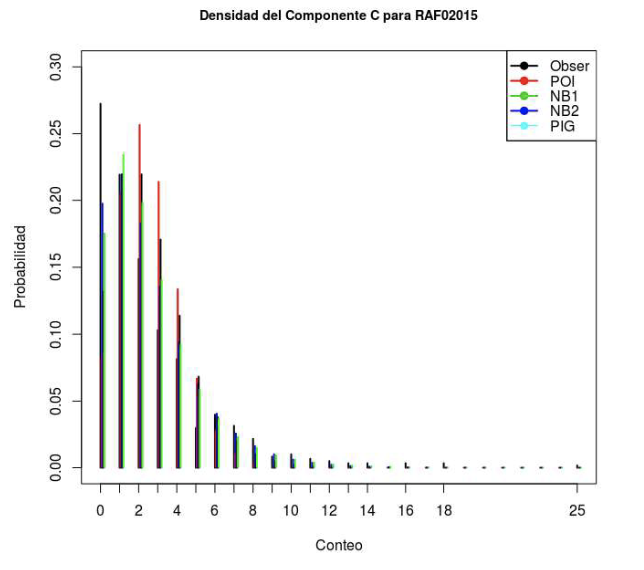
Figura 6: Distribución de diferentes MCont para C, dado el valor deµ= 2.5, Fuente: Elaboración propia.
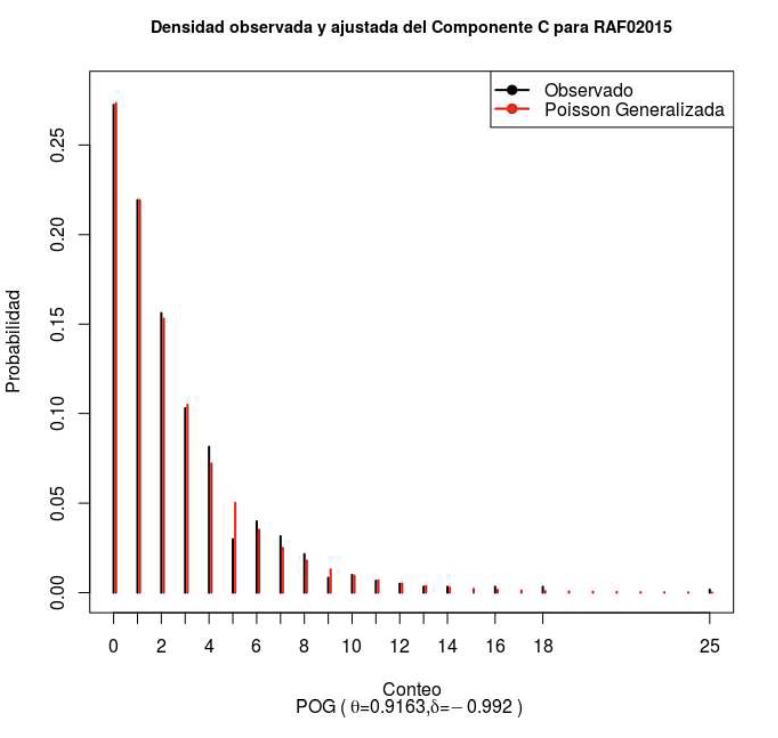
Figura 7: Ajuste del C,dado el valor deµ = 2.5 para un modelo PG, Fuente: Elaboración propia.
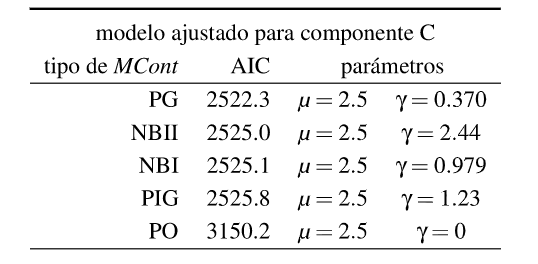
Tabla 4: Ajuste de la distribución del componente C
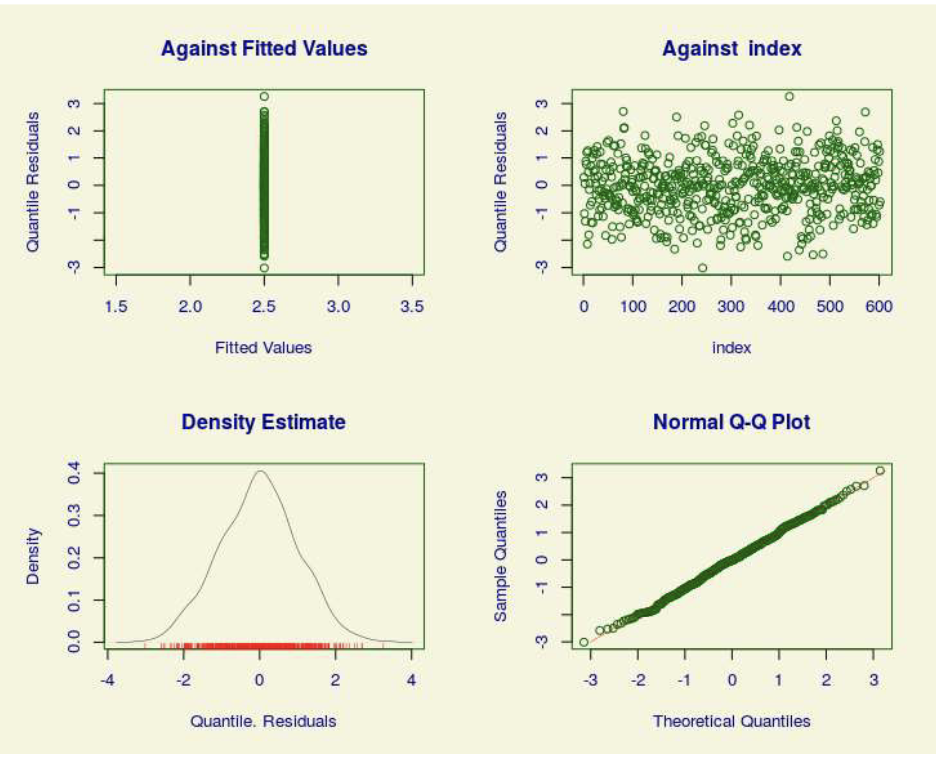
Figura 8:Gráficos de Bondad de ajuste para el modelo de conteo PG para C, Fuente: Elaboración propia.
En la Figura 8 puede verse que se cumplen las características para que el ajuste sea adecuado, tal como residuos con media O, distribución aparentemente gaussiana, a partir de la densidad y cuantiles empíricos que coinciden con los teóricos, donde no aparece un patrón o sesgo en las observaciones. En la Tabla 4 se muestra un resumen de los mejores modelos MCont ajustados para el CPO y sus tres componentes. En cada modelo ajustado se realiza el mismo proceso iterativo para encontrar el modelo con mejores indicadores de bondad como el AJC, el SBC y la devianza global y a su vez se realiza el diagnóstico de ajuste a través de los residuos.
Para entender mejor los resultados encontrados se presenta en la Tabla 5 para cada componente del CPO cual es la bondad de ajuste y la jerarquía que queda para los diferentes MCont presentados en sección 2 y donde finalmente, en la Tabla 6, se consigna solamente los MCont presentados en detalle previamente.Un aspecto a tener en cuenta es que los coeficientes que se presentan en la Tabla 5 están expresados a través de la función de enlace que es de tipo logarítmico y se usa la base de logaritmos naturales.
Finalmente, antes de pasar a la etapa de elaboración de modelos de pronóstico con las variables regresaras presentadas en la Tabla 2, en la Figura 9 se presentan los mejores modelos ajustados para el CPO y sus 3 componentes.

Tabla 5: Ranking de ajuste de los MCont para CPO y sus 3 componentes
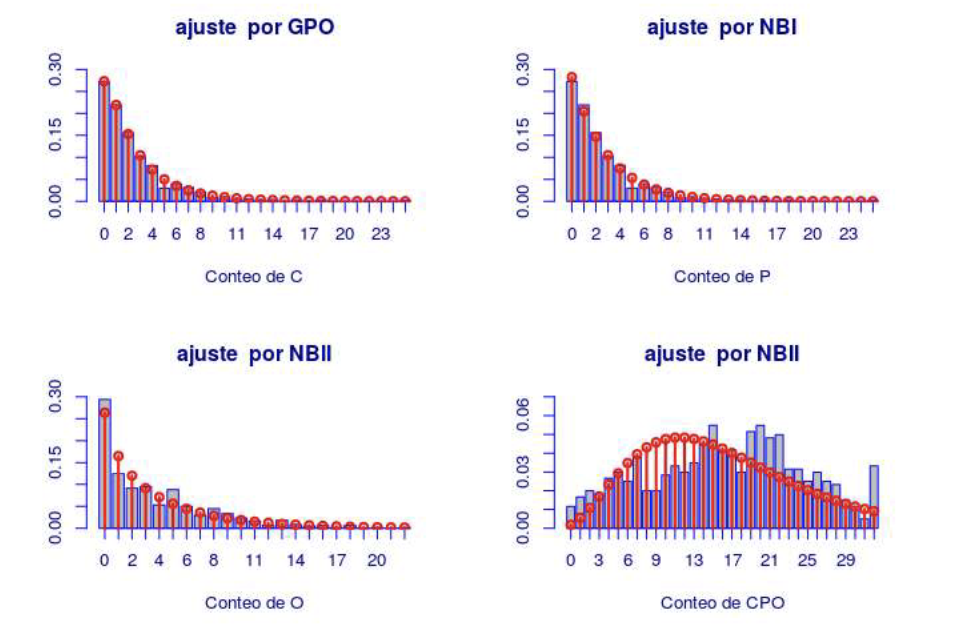
Figura 9: Representación gráfica de los modelos de probablidad ajustados para CPO y sus 3 componentes, Fuente: Elaboración propia.
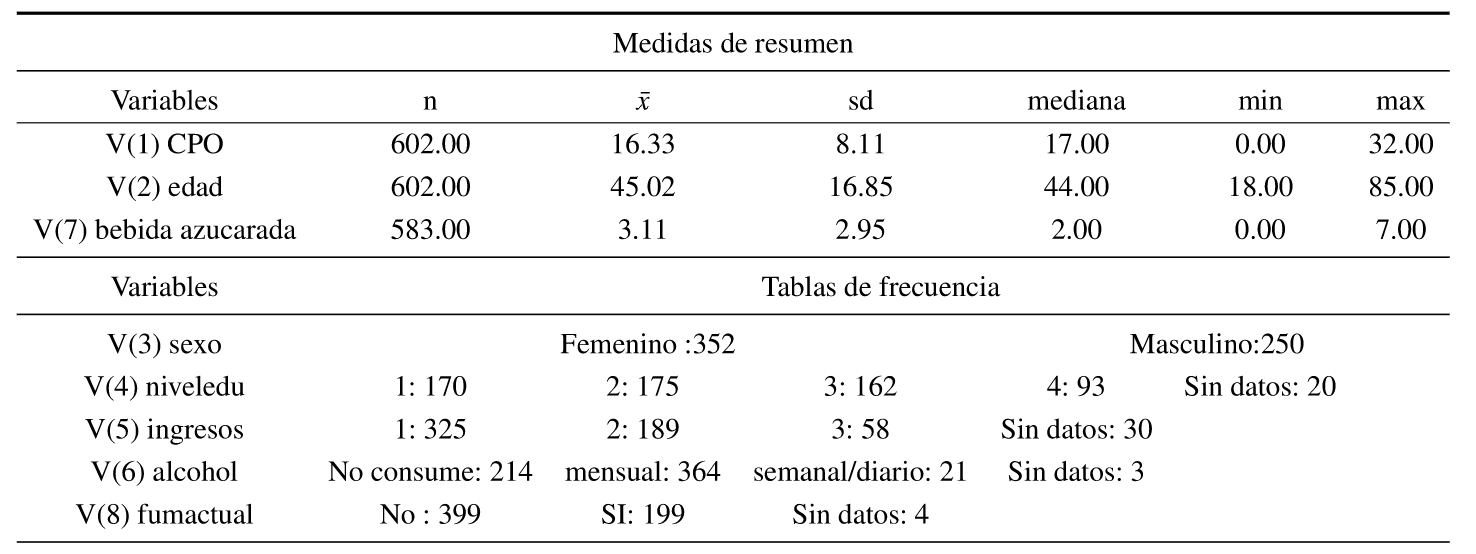
Tabla 7:Medidas de resumen de las variables regresoras paracomponente C
En la Tabla 7 se presentan las medidas de resumen para las variables regresoras del componente C, ya que solamente por ser de los tres el más relevante desde el punto de vista epidemiológico y el más frecuente mente estudiado, será el único analizado mediante modelos de regresión en este trabajo.
El modelo estimado presentado en la Tabla 8 toma en cuenta la sobredispersión que existe para el con teo de Caries, que este caso es de casi 2.5. Observando el modelo se podría pensar que existe una relación entre el número de Cy el sexo, la edad, la ingesta de bebidas azucaradas y las personas que tienen un mayor ingreso.
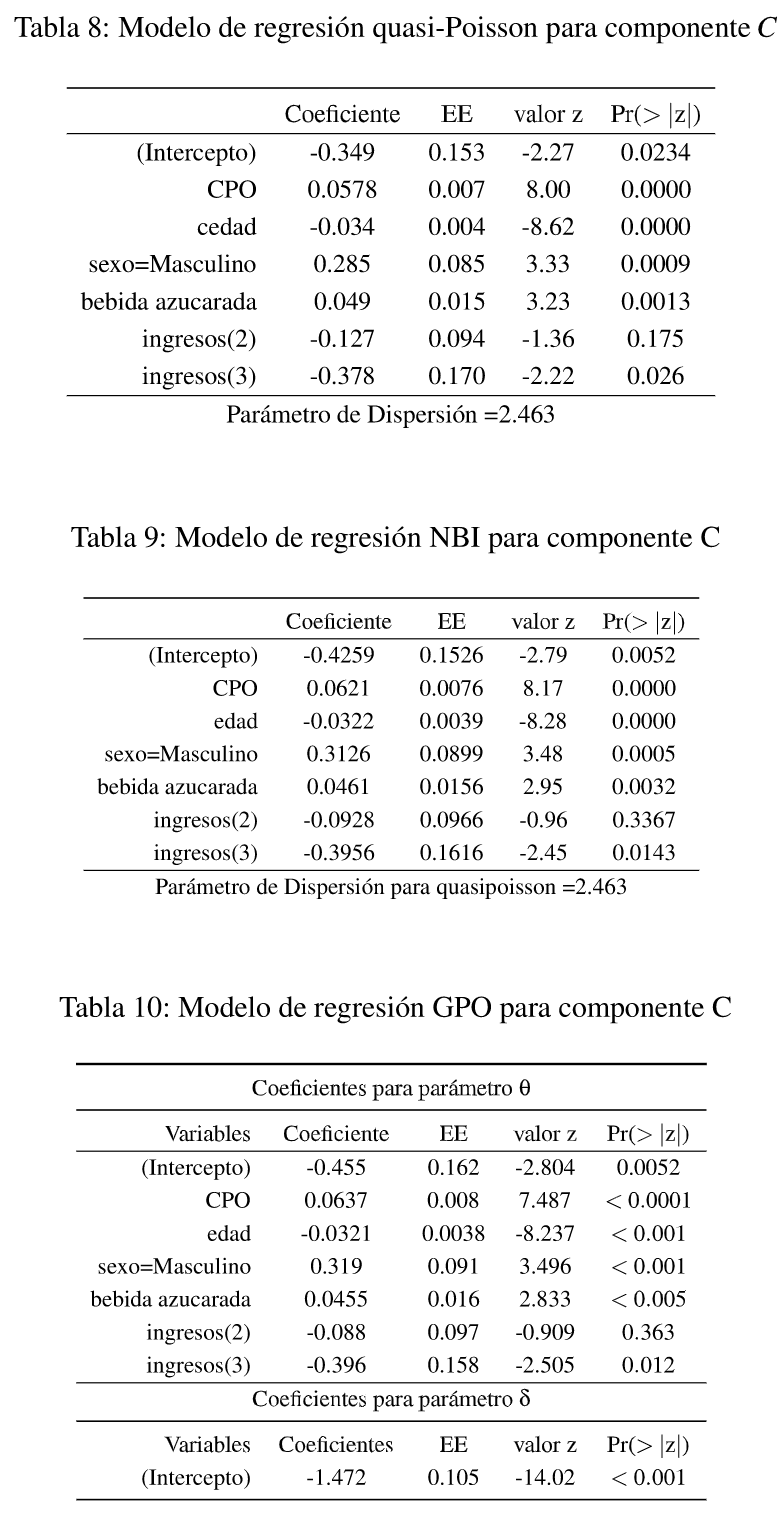
Trabajando con un modelo de probabilidad de Tipo NBII en función de los valores consignados en la columna Coeficiente, Error Estándar (EE), (que ya se vio que ajusta mejor a los datos) como aparecen en la Tabla 5, los resultados aparecen en la Tabla 9.
Si en lugar de estimar un modelo MH con distribución Poisson para el componente truncado se usa la distribución BN, donde aparece el parámetro de dispersión, los resultados cambian tal como se muestra en la Tabla 12 y donde ambos se pueden comparar para observar la mejoría en usar el modelo más complejo a través del test de Wald, que muestra que los cambios al usar el modelo con BN para el componente truncado no son relevantes.
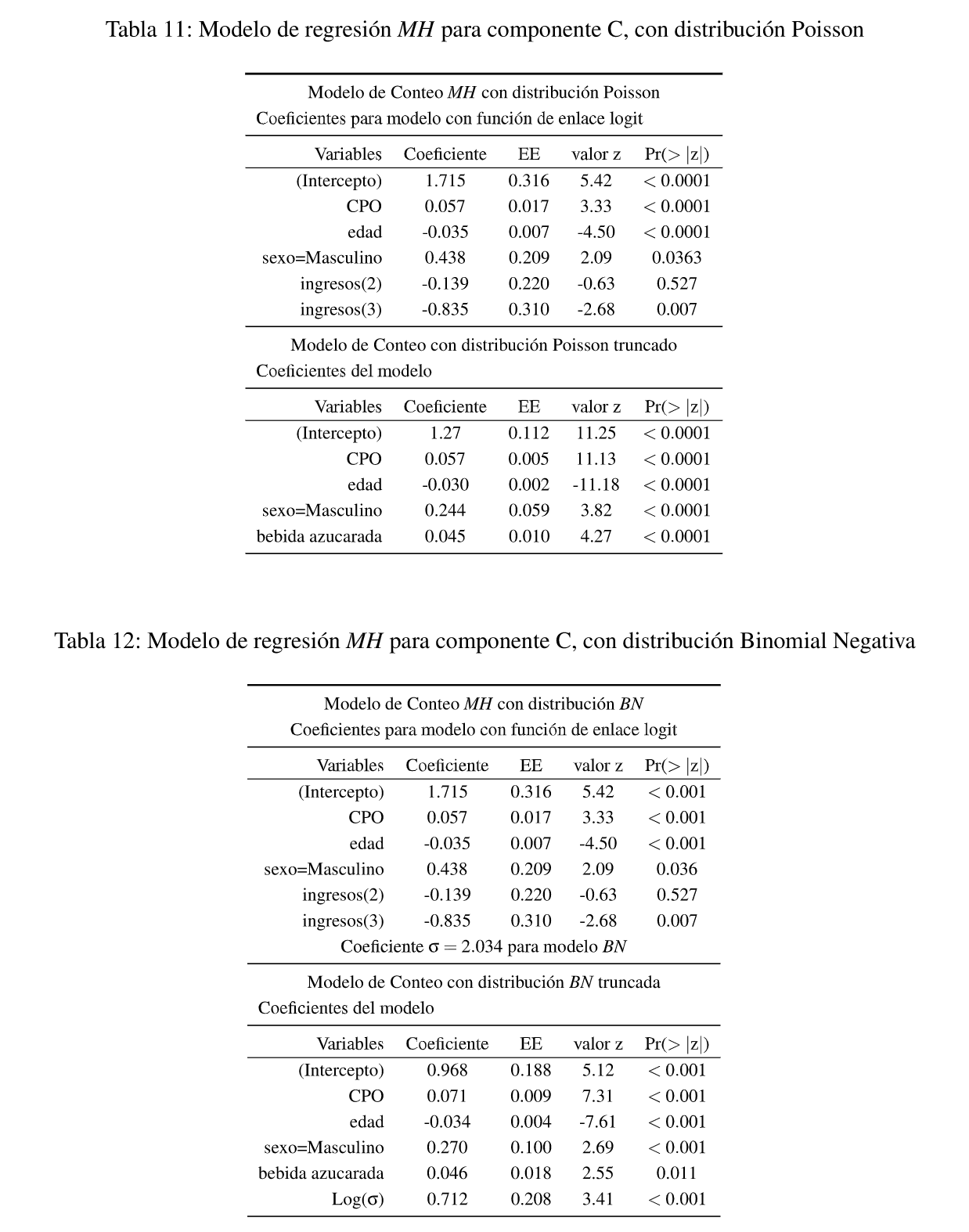
Finalmente en la Tabla 13 puede verse un resumen con la performance de los diferentes modelos, donde se presentan además indicadores de ajuste, donde la mejor opción es el modelo con obstáculos y distribución de conteo truncado de tipo BN, aunque igual subestima la cantidad de personas sanas de Caries, lo que estaría marcando que el modelo hallado parece adecuarse a una población más enferma, por lo que se plantea la necesidad de seguir indagando para identificar un mejor modelo.
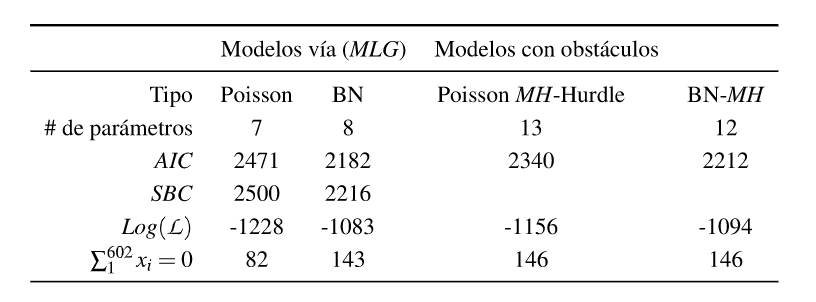
Tabla 13: Performance de los diferentes modelos de regresión para componente C, usando modelos paramétricos (MLG) y modelos con obstáculos
Luego de presentados los diferentes modelos de probabilidad en la sección 2, puede verse la forma de la distribución de los 4 componentes del estudio RPAF02015, donde en primer lugar en esta sección se discute sobre modelado del componente C dada la importancia de éste desde el punto de vista epidemiológico y de la Salud Pública, para luego presentar el comportamiento observado para los restantes componentes del CPO.
Puede verse por lo tanto que si se trabaja solamente con la distribución de C con independencia del res to de las variables (es decir la distribución incondicional o en un contexto sin variables regresoras), puede decirse que el mejor MCont es el que corresponde a la BN-Jl, como se ve gráficamente en la Figura 6, pero sin perder de vista que para los 5 modelos paramétricos presentados en 2, el ajuste es pobre.
Por tales motivos tal como se adelantó en la sección 3, la mejor alternativa es la PG, tal como se presenta en la Tabla 6, donde de un total de 29 distribuciones de conteo que se pueden estimar a través de la librería gamlss, (Rigby & Stasinopoulos, 2005), la PG está en el primer lugar. Entre todas esas distribuciones de conteo están las básicas presentadas en la sección 2, que corresponden a las ecuaciones 2.1 y 2.2, y varias variantes de las mismas que dada su complejidad matemática se dejan de lado. En la Figura 9, se presenta la calidad del ajuste que muestra que los residuos tienen media O, distribución aparentemente gaussiana, a partir de la densidad y cuantiles empúicos que coinciden con los teóricos, donde no aparece un patrón o sesgo en las observaciones.
Si ahora se considera el resto de los componentes del CPO, el ajuste de éstos a través de MCont básicos es insuficiente, salvo para el componente P. Para el caso de O, con un ajuste por una BN-Jl los datos, muestran un exceso de O y una diferencia importante. Para terminar esta parte del análisis el CPO es la variable de conteo que dado su comportamiento de no monotonía y ser multimodal, parece difícil de responder a un modelo con distribución conocido, sino que parece adecuado considerar a un proceso de mezcla.
En cambio en un contexto de regresión en las Tablas 9 y 1O se presentan los resultados de ajustar por un MPoi y un BN, dada la sobredispersión que existe y donde de las 8 variables regresoras previamente consideradas en la Tabla 3, solamente resultan significativas el CPO, la edad, el sexo, la cantidad de días en la semana donde se ingiere bebidas azucaradas y el ingresos de los individuos participantes del estudio. Para ambos modelos, donde los coeficientes muestran valores similares, se consideran las variables que son significativas y la asociación con el logaritmo del número medio de caries muestra resultados esperables. La cantidad de Caries se asocia con un mayor nivel de CPO, con un aumento promedio de una Caries por cada punto extra en el CPO, con un decremento de casi una Caries por cada año por encima de la media, lo que podría explicarse porque al aumentar la edad las personas tiene menos piezas presentes; a su vez el consu mo diario de bebidas azucaradas tiene un aumento promedio de una caries por cada día en que la persona consume bebidas. Un aspecto importante para ambos modelos es la importancia del coeficiente asociado a sexo masculino, donde el número medio de Caries es de casi 1.36 con respecto a las mujeres. Finalmente los ingresos muestra una asociación negativa donde las personas que están en el último tramo de ingresos tienen una reducción en el número de Caries importante con respecto a los del primer tramo, que es la referencia.
Todos estos resultados son muy similares para ambas versiones de los modelos y podrían resultar en la elaboración de teoría epidemiológica que para el investigador en Biomedicina no advertido podría llevarlo a cometer errores, si no se toma en cuenta un aspecto que en general no se considera y es la capacidad predictiva del modelo estimado.
Para este caso donde el conteo muestra comportamiento patológico al tener sobredispersión y exceso im portante de O, es fundamental verificar el grado de ajuste y no alcanza por lo tanto que las variables sean significativas, ya que no tomar en cuenta este aspecto puede llevar al investigador en Biomedicina que tra baje con modelos similares a cometer errores muy importantes pautando asociaciones entre variables que en la práctica no se dan.
En particular interesa ver que sucede con el conteo de O. El componente C muestra que hay 164 perso nas sanas de Caries, es decir con un conteo=O, mientras que los 2 modelos básicos estimados para el caso de Poisson pronostican 82 personas sin Caries y el modelo de la BN el conteo es de 143. Por eso motivo los modelos con obstáculos o MH con distribución de conteo truncada que se presentan en las Tablas 11 y 12, muestran una mejor capacidad de detectar personas con C=O y a su vez las variables regresoras de cada parte del modelo pautan un aspecto muy importante que se detalla a continuación.
La parte del modelo MH que se modela mediante un logit y es el que permite saltar el obstáculo, es el muestra que perfil tiene la persona para tener o no Caries, que en el caso del MH Poisson son el CPO, la edad, el sexo, el nivel de ingesta de bebidas azucaradas y el ingreso, mientras que para la parte del modelo truncado la ingesta no se debe tener en cuenta y el ingreso pasa a tener un efecto contrario al cambiar de signo.
De los resultados encontrados resulta fundamental recordar los siguientes pasos que debería seguir el investigador biomédico al trabajar con este tipo de datos que presentan varias patologías desde el punto de vista estadístico, por lo cual no se pueden usar los modelos básicos de conteo.
• Previamente examinar cuáles pueden ser las distribuciones que reproducen los conteos (en este caso C,P,O) independientemente de los modelos que se deseen elaborar para encontrar asociaciones;
• No alcanza con encontrar variables significativas con las cuales desarrollar teoría epidemiológica que tenga sentido para el investigador, ya que estaría basada en modelos que no son comparables con los datos bajo estudio; en el caso presentado las asociaciones son válidas para poblaciones menos enfermas (hay menos gente con Caries);
• Es necesario usar modelos combinados más complejos como los que se componen de 2 submodelos
• Uno que trabaja con personas que no tienen Caries, aspecto que se modela con el componente 1 del modelo (MH);
• Cuando tienen Caries, la cantidad de éstas se modelan con el componente 2 del modelo (MH).
Podría suceder que las variables regresaras que se usan para salir del obstáculo no necesariamente sean las mismas que las que contribuyen a modelar el conteo truncado (> O) e incluso siendo las mismas pueden cambiar el sentido de la asociación o la intensidad de las mismas con coeficientes con distintos valores.
Si bien no se trabajó con el resto de los componentes del CPO o el CPO mismo en un contexto de regresión ya se vió que las distribuciones no son identificables fácilmente a través de un modelo explícito de los presentados, sino que hay que pensar en identificar mezclas de distribuciones.
Como último comentario siempre es deseable manejar modelos parsimoniosos pero es deber del investigador conocer las limitaciones de los mismos y lograr un equilibrio entre modelo sencillo pero adecuado.
Figura 1:Odontograma, Fuente: Salud dental para todos (https://dtdental.co/que-es-un-odontograma-dentall).
Tabla 1: Relación entre Media y Varianza para diferentes modelos de Conteo
Figura 2:Densidad Gamma(«,p) peraparámetroµ en distribución BN,Puente: Elaboración propia.
Figura 3:Densidad IG(>t,,),para parámetroµ en distribución PIG, Fuente: Elaboración propia.
Tabla 2: Conjunto de variables regresoras usadas para los modelos de conteo en RPAF02015
Tabla 3:Medidas deresumende los compo de CPO
Figura 5:Distribución parael CPO y sus 3 componentes, Fuente: Elaboración propia.
Figura 5:Distribución parael CPO y sus 3 componentes, Fuenk::Elaboración propia.
Figura 6: Distribución de diferentes MCont para C, dado el valor deµ= 2.5, Fuente: Elaboración propia.
Figura 7: Ajuste del C,dado el valor deµ = 2.5 para un modelo PG, Fuente: Elaboración propia.
Tabla 4: Ajuste de la distribución del componente C
Figura 8:Gráficos de Bondad de ajuste para el modelo de conteo PG para C, Fuente: Elaboración propia.
Tabla 5: Ranking de ajuste de los MCont para CPO y sus 3 componentes
Figura 9: Representación gráfica de los modelos de probablidad ajustados para CPO y sus 3 componentes, Fuente: Elaboración propia.
Tabla 7:Medidas de resumen de las variables regresoras paracomponente C
Tabla 13: Performance de los diferentes modelos de regresión para componente C, usando modelos paramétricos (MLG) y modelos con obstáculos


