2021
232
07042021
27052021
 Carlos Ernesto Flores Tapia florestapiacarlos@yahoo.com
Carlos Ernesto Flores Tapia florestapiacarlos@yahoo.com
Pontificia Universidad Católica del Ecuador, Ecuador
Karla Lissette Flores Cevallos karla.floresceva@alum.uca.es
Universidad de Cádiz, Ecuador
Resumen: El objetivo del presente artículo es determinar la normalidad de los datos, utilizando cuatro tipos de pruebas, a saber, Anderson-Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov, aplicadas a los datos muestrales provenientes del registro de producción de la empresa objeto de estudio, ubicada en la ciudad de Ambato, Ecuador. Estas pruebas permiten determinar si la población de la cual se obtuvo la muestra sigue la distribución normal, identificación que resulta clave para la aplicación del procedimiento estadístico adecuado para el análisis de los datos en un determinado estudio y para la correspondiente contrastación de hipótesis cuando se requiere que, previamente se haya comprobado el supuesto de normalidad de los datos. Por otra parte, en esta investigación se demuestra la aplicabilidad y utilidad de estas pruebas a estudios de caso empresariales; las cuales pueden apoyarse en herramientas informáticas especializadas que agilitan los tiempos de procesamiento y ahorran costos significativos a las organizaciones, particularmente en escenarios complejos, como el generado por la actual crisis del COVID-19.
Palabras clave: negocios, investigación de operaciones, estadística, distribución normal, prueba de hipótesis, Minitab, Clasificación JEL: C02, C12, C14, C16, M11, L23.
Abstract: The objective of this article is to determine the normality of the data, using four types of tests, namely Anderson-Darling, Ryan-Joiner, Shapiro-Wilk, and Kolmogórov-Smirnov, applied to the sample data from the production record of the company under study, located in the city of Ambato, Ecuador. These tests allow determining whether the population from which the sample was obtained follows the normal distribution, an identification that is key for the application of the appropriate statistical procedure for the analysis of the data in a given study and for the corresponding hypothesis testing when required that, previously the assumption of normality of the data has been verified. On the other hand, this research demonstrates the applicability and usefulness of these tests to business case studies, which can be supported by specialized IT tools that speed up processing times and save significant costs for organizations, particularly in complex scenarios, such as the one generated by the current COVID-19 crisis.
Keywords: business, operations research, statistics, normal distribution, hypothesis testing, Minitab, JEL classification: C02, C12, C14, C16, M11, L23.
Artículos
PRUEBAS PARA COMPROBAR LA NORMALIDAD DE DATOS EN PROCESOS PRODUCTIVOS: ANDERSON-DARLING, RYAN-JOINER, SHAPIRO-WILK Y KOLMOGÓROV-SMIRNOV
TESTS TO VERIFY THE NORMALITY OF DATA IN PRODUCTION PROCESSES: ANDERSON-DARLING, RYAN-JOINER, SHAPIRO-WILK AND KOLMOGOROV-SMIRNOV
Carlos Ernesto Flores Tapia florestapiacarlos@yahoo.com
Karla Lissette Flores Cevallos karla.floresceva@alum.uca.es
Recepción: 07 Abril 2021
Aprobación: 27 Mayo 2021

La Investigación de Operaciones consiste en un conjunto de técnicas que contribuyen a la solución de problemas de una amplia gama de actividades, mediante la aplicación de diversas técnicas sustentadas en modelos matemáticos y estadísticos. Es el caso, principalmente, de los métodos paramétricos -estadístico Z, t-student, F, entre otros; de los métodos no paramétricos -prueba de signo, pruebas de suma de rangos, Kolmogórov-Smirnov, entre otros- y de las técnicas de análisis multivariante -análisis factorial, análisis de clúster, análisis discriminante, entre otras. A su vez, la utilización de alguno de los estadísticos señalados implica, primero, la comprobación del cumplimiento de supuestos, es el caso de la determinación de la normalidad de los datos (Anderson et al., 2016b; Hillier & Lieberman, 2015; Taha, 2017).
Ahora bien, muchos procedimientos estadísticos dependen de la normalidad de la población, de modo que recurrir a una prueba de normalidad para determinar si se rechaza este supuesto constituye un paso importante en el análisis. Entre las pruebas para determinar si los datos de su muestra provienen de una población no normal, se destacan Anderson-Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov (Levin et al., 2014;Robbins, 2015).
En este sentido, la aplicación de las pruebas de normalidad de los datos pretende garantizar la robustez de los análisis estadísticos, más aún cuando en las organizaciones se dedica tiempo y recursos para ello, razón por la cual es deseable llegar a conclusiones correctas. En este sentido, resulta clave verificar que, cuando se aplica una determinada herramienta estadística al análisis de variables continuas o cuantitativas, la información obtenida durante el proceso, mantiene o no la distribución normal de los datos; porque, por ejemplo, todos los test paramétricos requieren el cumplimiento de este supuesto y la aplicación de test no paramétricos, a su vez, necesitan que las observaciones no procedan de una distribución normal (Correa et al., 2006; Guisande & Barreiro, 2006; Lind, 2012b).
Dicho lo anterior, el objetivo de esta investigación de caso particular es verificar el supuesto de normalidad en muestras de datos relacionados con procesos industriales de la empresa Servicartón Cía. Ltda., mediante la aplicación de las pruebas de Anderson-Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov, utilizando el software Minitab. Las hipótesis que se contrastan en este estudio, para cada una las pruebas señaladas anteriormente, son:
- H0: Los datos siguen una distribución normal.
- H1: Los datos no siguen una distribución normal.
El no cumplimiento del supuesto de la normalidad de los datos afecta a los test de hipótesis paramétricos y a los modelos de regresión, siendo su principal consecuencia, por un lado, la ineficiencia del estimador mínimo-cuadrático o estimador de la curva de mínima de varianza y, por otro, los intervalos de confianza de los parámetros del modelo y los controles de significancia son solamente aproximados y no exactos. No obstante, en el caso de que en las muestras no se verifique la normalidad de datos, pero se tenga certeza de que las poblaciones de origen si lo hacen, los resultados obtenidos por los contrastes paramétricos pueden ser válidos (Arnau, 1996). Lo señalado implica que la prueba de normalidad de los datos es un supuesto utilizado en algunas pruebas estadísticas que tiene que verificarse previamente para determinar la aplicación o no de determinados estadísticos, tales como t – student, la prueba F, ANOVA, análisis factorial, análisis discriminante y análisis clúster, entre otros. (Eppen et al., 2000;Gujaratí & Porter, 2010).
Ahora bien, la distribución normal es una distribución con forma de campana donde las desviaciones estándar sucesivas con respecto a la media establecen valores de referencia para estimar el porcentaje de observaciones de los datos. Estos valores de referencia son la base de muchas pruebas de hipótesis, como las pruebas Z y t. La distribución de los datos bajo la curva normal tiene, entre sus principales características, las siguientes:
- La curva normal tiene forma de campana y un solo pico en el centro de la distribución, siendo la media aritmética, la mediana y la moda de la distribución iguales; por lo tanto, la mitad del área bajo la curva se encuentra a la derecha de este punto central y la otra mitad está a la izquierda de dicho punto.
- La distribución de probabilidad normal es simétrica alrededor de su media.
- La curva normal desciende suavemente en ambas direcciones a partir del valor central, siendo asintótica; es decir, la curva se acerca cada vez más al eje de las abscisas, pero jamás llega a intersecarlo, extendiéndose las “colas” de la curva indefinidamente en ambas direcciones. Es así que, buena parte de las observaciones de variabilidad de la naturaleza y, por supuesto, en los procesos empresariales siguen la distribución de frecuencia de las curvas normales (Romero, 2016;Triola, 2018).
El contraste de la hipótesis de normalidad de los datos puede efectuarse utilizando dos tipos de pruebas, a saber, representaciones gráficas y test de hipótesis, tales como Anderson-Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov, siendo de gran utilidad realizar una prueba de normalidad y producir una gráfica de probabilidad normal en el mismo análisis, por cuanto la prueba de normalidad y la gráfica de probabilidad suelen ser las mejores herramientas para evaluar la normalidad (Anderson et al., 2016a). A continuación, se procede con la explicación de cada una de estas técnicas estadísticas.
Se puede evaluar la normalidad de una población mediante una gráfica de probabilidad normal, la cual genera de manera gráfica valores de datos ordenados comparados con los valores que se espera sean cercanos a los primeros, si efectivamente la población de la muestra está normalmente distribuida. Lo que significa que, si la población es normal, los puntos de la gráfica conformarán una línea aproximadamente derecha. Por lo tanto, una gráfica de probabilidad crea una función de distribución acumulada, estimada a partir de la muestra, al graficar el valor de cada una de las observaciones en función de la probabilidad acumulada estimada de la observación. Esta técnica gráfica facilita la identificación visual del ajuste o no de los datos a la distribución normal (Minitab, 2020).
El estadístico de bondad de ajuste de Anderson-Darling -AD- mide el área entre la línea ajustada -basada en la distribución normal- y la función de distribución empírica -que se basa en los puntos de los datos-. El estadístico de Anderson-Darling es una distancia elevada al cuadrado que tiene mayor ponderación en las colas de la distribución (Jensen & Alexander, 2016).
Según Guisande & Barreiro (2006), el estadístico Anderson Darling puede ser utilizado para comprobar si los datos satisfacen el supuesto de normalidad para una prueba t. También se lo puede definir como aquel estadístico no paramétrico que es utilizado para probar si un conjunto de datos muéstrales provienen de una población con una distribución de probabilidad continua específica, por lo general, de una distribución normal. Esta prueba se basa en la comparación de la función de la distribución acumulada empírica de los resultados de la muestra con la distribución esperada si los datos fueran normales. Al momento de obtener los resultados, si la diferencia observada es suficientemente grande, la hipótesis nula de normalidad de la población es rechazada.
El estadístico A2 mide el área entre la línea ajustada basada en la distribución elegida y la función de paso no paramétrica, basado en los puntos de la gráfica. El estadístico es una distancia elevada al cuadrado que tiene mayor ponderación en las colas de la distribución, por lo tanto, un valor pequeño de Anderson-Darling indica que la distribución se ajusta mejor a los datos (Minitab, 2020). El estadístico de Anderson-Darling -A2- está dado por la ecuación 1.
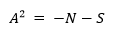
Donde:
N: número de casos.
S: desviación estándar.
Expresado también según la ecuación 2, así:
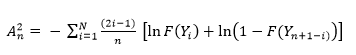
Donde:
n es el número de datos.
observaciones ordenadas.
F(Yi) es la función de la distribución empírica.
Y también se puede expresar tal como se muestra en la ecuación 3, así:
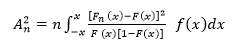
La prueba de Anderson-Darling se realiza en dos pasos: primero, se crean dos distribuciones acumulativas, la primera es una distribución acumulativa de los datos crudos y la segunda, es una distribución acumulativa normal y, segundo, se comparan las dos distribuciones acumulativas para determinar la mayor diferencia numérica absoluta entre ambas. De tal manera que, si la diferencia es amplia, se rechaza la hipótesis nula, esto es, que los datos siguen una distribución normal (Flores-Tapia & Flores-Cevallos, 2018).
El estadístico Anderson-Darling mide qué tan bien siguen los datos una distribución específica, siendo que, para un conjunto de datos y distribución en particular, mientras mejor se ajuste la distribución a los datos, menor será este estadístico. También puede utilizar el estadístico de Anderson-Darling para comparar el ajuste de varias distribuciones con el fin de determinar cuál es la mejor. Sin embargo, para concluir que una distribución es la mejor, el estadístico de Anderson-Darling debe ser sustancialmente menor que los demás. Cuando los estadísticos están cercanos entre sí, se deben usar criterios adicionales, como las gráficas de probabilidad, para elegir entre ellos.
El estadístico de Ryan-Joiner mide qué tan bien se ajustan los datos a una distribución normal, calculando la correlación entre los datos y las puntuaciones normales de los datos. Según Hanke & Wichern (2014) la prueba de Ryan Joiner proporciona un coeficiente que indica exactamente la correlación entre los datos y las puntuaciones normales de los datos. Una vez que el coeficiente de correlación se acerca a 1, los datos se encuentran dentro de la gráfica de probabilidad normal; caso contrario, esto es, cuando el valor critico adecuado es menor, se rechaza la hipótesis nula de normalidad. Cabe recalcar que para rechazar la hipótesis nula de normalidad se calcula, primero, la medida de la correlación entre los residuos y sus respectivas puntuaciones normales y, luego, se utiliza dicha correlación como estadística de prueba. La prueba de Ryan-Joiner -similar a la prueba de Shapiro-Wilk- se basa en la regresión y correlación. Esta prueba resulta mucha más adecuada para muestras superiores a 30 observaciones. El coeficiente de correlación se calcula de acuerdo con la ecuación 4.
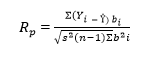
Donde:
observaciones ordenadas
puntuaciones normales de los datos ordenados
varianza de la muestra
Para definir la regla de rechazo de esta prueba es necesario, también obtener el estadístico ajustado para luego compararlo con los valores críticos con la tabla Anderson-Darling. Por otra parte, cabe destacar que la prueba de Ryan-Joiner es una modificación de la prueba de Kolmogórov-Smirnov, otorgándose mayor relevancia a las colas de la distribución que en la prueba de Kolmogórov-Smirnov (Levin et al., 2014; Minitab, 2020).
Según Novales (2010), este test se emplea para contrastar normalidad cuando el tamaño de la muestra es menor a 50 observaciones y en muestras grandes es equivalente al test de Kolmogórov-Smirnov. El método consiste en comenzar ordenando la muestra de menor a mayor valor, obteniendo el nuevo vector muestral. Cuando la muestra es como máximo de tamaño 50, se puede contrastar la normalidad con la prueba de Shapiro-Wilk, procediéndose a calcular la media y la varianza muestral. Se rechaza la hipótesis nula de normalidad si el estadístico Shapiro-Wilk -W- es menor que el valor crítico proporcionado por la tabla elaborada por los autores para el tamaño de la muestra y el nivel de significancia dado.
Shapiro-Wilk, como prueba de normalidad, fue introducido considerando que el gráfico de probabilidad normal que examina el ajuste de un conjunto de datos de muestra para la distribución normal es semejante a la de regresión lineal - la línea diagonal del gráfico es la recta de ajuste perfecto-, con la diferencia de que esta línea es similar a los residuos de la regresión. Mediante el análisis de la magnitud de esta variación -análisis de varianza-, la calidad del ajuste puede ser examinado. La prueba puede aplicarse a muestras grandes, como fue sugerido por Royston, que también produjo algoritmos para implementar su extensión y que se implementa en algunos softwares especializados estadísticos (Carmona & Carrión, 2015). El estadístico de prueba se muestra en la ecuación 5.
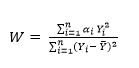
Donde Yi son los datos de la muestra, ordenados por tamaño -ordenado-. Ahora bien, si los datos de la muestra son en realidad una muestra aleatoria de una distribución normal con media desconocida μ y varianza σ2, entonces se debe facilitar la representación de los datos mediante la ecuación lineal simple 6, así:
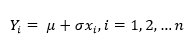
Donde la es un conjunto ordenado de azar N (0,1) variables. El ajuste de mínimos cuadrados de los pares (x, y) proporciona los medios para determinar el desconocido coeficientes . El vector de estos coeficientes se obtiene de la expresión matriz expresada en la ecuación 7.
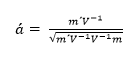
Donde V es la matriz de varianza-covarianza de los elementos del vector x, y el vector m es el valor esperado de los elementos de x, es decir, los valores medios de las estadísticas de orden para la distribución normal. El estadístico W es invariante escala y el origen y tiene un valor máximo de 1 y un mínimo de /n-1. Por lo tanto, el valor mínimo es aproximadamente el cuadrado del menor coeficiente para n> 10. Así también, la distribución de W para generar n no es conocido y debe ser obtenido por simulación y/o tabulación de los resultados o utilizando la aproximación -como es el caso con el enfoque de Royston-. De tal manera que el estadístico W es más bien como un coeficiente de correlación al cuadrado -o coeficiente de determinación- y, en tal sentido, un valor alto indica una mayor correspondencia a la normal. No obstante, este resultado no es concluyente, por cuanto los valores altos a menudo se encuentran con muestras pequeñas de datos que no son normales, siendo particularmente sensible a la distribución de asimetría y con cola larga (Allaire et al., 2019).
Prueba Kolmogórov-Smirnov
La prueba de Kolmogórov-Smirnov es una prueba de bondad de ajuste ampliamente utilizada para probar la normalidad de los datos muestrales, siendo particularmente útil en procesos físicos no lineales e interactivos, por cuanto éstos conducen, generalmente, a distribuciones no gaussianas y, por lo tanto, el mecanismo generador de los procesos puede entenderse mejor al examinar la distribución de las variables seleccionadas. Además, para implementar pruebas de normalidad algunas pruebas estadísticas requieren o son óptimos bajo el supuesto de normalidad y, por lo tanto, constituye un prerrequisito determinar si este supuesto se cumple (Steinskog et al., 2007).
La prueba Kolmogórov-Smirnov se aplica para contrastar la hipótesis de normalidad de la población, la ecuación 8 la representa y se muestra a continuación.

Para dos colas el estadístico viene dado por las ecuaciones 9 y 10, así:
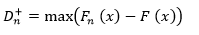
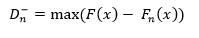
Donde F(x) es la distribución presentada como hipótesis.
Siendo la función de distribución muestral y la función teórica o correspondiente a la población normal especificada en la hipótesis nula.
La distribución del estadístico de Kolmogórov-Smirnov es independiente de la distribución poblacional especificada en la hipótesis nula y los valores críticos de este estadístico están tabulados. Si la distribución postulada es la normal y se estiman sus parámetros, los valores críticos se obtienen aplicando la corrección de significación propuesta por Lilliefors. Las tablas estándar utilizadas para la prueba de Kolmogórov-Smirnov son válidas cuando se prueba si un conjunto de observaciones proviene de una distribución continua completamente especificada, mientras que, si uno o más parámetros deben estimarse a partir de la muestra, las tablas ya no son válidas (Romero, 2016).
Por otra parte, esta prueba compara la función de distribución acumulada empírica de los datos de la muestra con la distribución esperada si los datos fueran normales. Si esta diferencia observada es suficientemente grande, la prueba rechaza la hipótesis nula de normalidad de la población. Si el valor p de esta prueba es menor que el nivel de significancia -α- elegido, usted puede rechazar la hipótesis nula y concluir que se trata de una población no normal (Minitab, 2020).
Cabe señalar que las pruebas de Anderson-Darling y Kolmogórov-Smirnov se basan en la función de distribución empírica, entre tanto, la prueba de Ryan-Joiner -similar a la prueba de Shapiro-Wilk- se basa en regresión y correlación. Las tres pruebas tienden a ser adecuadas para identificar una distribución no normal cuando la distribución es asimétrica y las tres pruebas distinguen menos la distribución normal cuando la distribución subyacente es una distribución t y la no normalidad se debe a la curtosis. Por lo general, entre las pruebas que se basan en la función de distribución empírica, la prueba de Anderson-Darling tiende a ser más efectiva para detectar desviaciones en las colas de la distribución. Generalmente, si la desviación de la normalidad en las colas es el problema principal, se recomienda el uso de la prueba de Anderson-Darling como primera opción. Es decir, las pruebas de Anderson-Darling y Ryan-Joiner tienen una potencia similar para detectar la ausencia de normalidad, mientras la prueba de Kolmogórov-Smirnov tiene una potencia menor para obtener explicaciones con respecto a la normalidad de los datos (Levin et al., 2014).
Por otra parte, siendo la prueba de representaciones gráficas y las pruebas Anderson Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov las técnicas más utilizadas para determinar el supuesto de normalidad, se cuenta con herramientas de software para ayudar a los analistas en la implementación de modelos computarizados, tales como el software Minitab, SPSS, R, Excel, Stata y Gretel, principalmente (Gujarati & Porter, 2009; IBM, 2020; Microsoft, 2020; Taha, 2017).
Ahora bien, entre los estudios relacionados con la aplicación de técnicas estadísticas y de Investigación de Operaciones que requieren previamente para su aplicación la verificación del supuesto de normalidad, se destaca Porras (2016), quien utiliza la distribución normal multivariada, tomando en consideración ciertos criterios para determinar cuál es la prueba más adecuada -Mardia, Henze-Zinkler, Shapiro-Wilk Generalizada y Royston-, bajo ciertas condiciones como el tamaño de muestra, número de variables, variabilidad conjunta, en la simulación de Monte Carlo; concluyendo que no existen diferencias significativas en la potencia de las pruebas consideradas en la investigación.
Así también, Acevedo et al. (2019), presentan un modelo econométrico de correlación bajo el Método de Coeficiente de Hurst y la prueba de Normalidad Jarque-Bera, para explicar que uno de los factores relevantes en los ingresos de la balanza de pagos de la nación es el precio del petróleo WTI y su variación en el tiempo, unido a la fluctuación de la TRM; variables que a su vez afectan otros índices como Inflación, tasas de interés, crecimiento económico, devaluación, entre otros, generando expectativa por el futuro del gasto y las inversiones públicas.
Otro autor, Torres (2019), presenta una aplicación de las cartas de control para medias y rangos y un análisis de capacidad del proceso para evaluar el comportamiento del peso en la elaboración de sobres de azúcar personalizados bajo el supuesto de normalidad, realizándose inicialmente las estadísticas básicas y prueba de normalidad y, posteriormente, calculándose las cartas de control y los índices de capacidad del proceso. Identifica, en la investigación, el impacto de las herramientas digitales en el aprendizaje en el aula y el cambio en la metodología empleada, mediante el estadístico t-student y la prueba Levele para probar también, previamente, la igualdad de varianzas entre las variables estudiadas.
Por su parte, Flores Tapia et al. (2017) investigan el efecto que tiene el tamaño del tallo, las variedades de rosas más importantes cultivables y el estado del botón sobre el volumen total de ventas en la empresa florícola del cantón Latacunga “High Connection Flowers”; utilizan herramientas de los métodos cuantitativos para la toma de decisiones. Esto es, el diseño de experimentos mediante modelos factoriales completos, necesitándose para su aplicación, primero, la contrastación de la hipótesis de igualdad de varianzas y la prueba de normalidad de Anderson-Darling. Mientras, Gonzáles and Leal (2016), demuestran la dependencia emocional como un factor de riesgo para ser víctima de violencia de pareja en mujeres que acuden al Centro de Apoyo a la Mujer Maltratada y mujeres que viven en el Sector Paraíso - Panamá, además confirman que existe diferencia en el nivel de dependencia emocional según el grado de estudios, pero no para el caso de la variable estado civil; aplican un tipo de investigación ex post facto retrospectivo de dos grupos, donde analizan la relación entre las variables de estudio, probando primero la normalidad de los datos y luego la igualdad de varianzas mediante la prueba de Levene, previo a la aplicación de la t-student. Finalmente, se destaca el trabajo de Benvenu et al. (2017), quienes, utilizando enfoques basados en Taguchi y análisis de los métodos de varianza -ANOVA- estudian la lixiviación de los relaves de flotación de cobre y cobalto, determinando las condiciones óptimas de lixiviación, así como los parámetros de funcionamiento más influyentes. En este diseño factorial, previamente, contrastan las hipótesis de normalidad de datos y de igualdad de varianzas antes de proceder con la prueba ANOVA para determinar la relación entre las condiciones experimentales y los niveles de rendimiento, así como para definir la importancia de los parámetros en los rendimientos de lixiviación.
No obstante, en los estudios antes referidos no se aplica un procedimiento metodológico de tres pruebas de normalidad de datos en un mismo estudio de caso, como se realiza en la presente investigación.
El estudio contempla técnicas cuantitativas que se ajustan a la metodología de Investigación de Operaciones (Flores Tapia et al., 2017; Hillier & Lieberman, 2015;Taha, 2017), previéndose seis etapas o fases a seguirse:
- Definición del problema de interés y recolección de datos relevantes.
- Formulación de un modelo matemático que represente el problema.
- Desarrollo de un procedimiento basado en computadora para derivar una solución para el problema a partir del modelo.
- Prueba del modelo y mejoramiento de acuerdo con las necesidades.
- Preparación para la aplicación del modelo prescrito por la administración.
- Implementación.
Cabe señalar que la metodología cuantitativa es aquella en la que se recogen y analizan datos cuantitativos sobre variables y estudia las propiedades y fenómenos cuantitativos. Entre las técnicas de análisis se destacan el análisis descriptivo, análisis exploratorio, inferencial univariable, inferencial multivariado, modelización y contrastación, entre otros. El alcance del estudio contempla la aplicación de tres pruebas que permiten probar la normalidad de datos como son el test de Anderson Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov, siguiendo tres fases, a saber: definición del problema y recolección de datos, desarrollo del procedimiento basado en computadora e interpretación de resultados (Flores-Tapia & Flores-Cevallos, 2017; Lind, 2012b).
A continuación, siguiendo la metodología antes indicada, se muestran los resultados de la aplicación de las pruebas de Anderson Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov consideradas para los casos de estudio, objeto de esta investigación.
Antes de proceder con la aplicación de la prueba Anderson-Darling, se establece el enunciado del estudio de caso y las condiciones de este, en los siguientes términos:
La empresa Servicartón Cía. Ltda. (2020), ubicada en la ciudad de Ambato, Ecuador, tiene problemas en cuanto el proceso productivo por cuanto una máquina laminadora está presentando problemas en la estandarización de la densidad del cartón. Se toman 8 modelos de cartón corrugado. La gerencia desea saber si la variabilidad de las medidas de densidad de las observaciones realizadas se ajusta a la política establecida; no obstante, previamente necesita que se garantice que los datos siguen la curva normal para aplicar un estadístico paramétrico. Se decide trabajar con un nivel de significancia de 0,01. Las medidas de densidad de la muestra seleccionada se muestran en la Tabla 1.
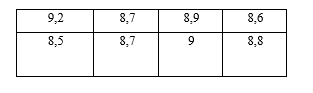
Utilizando el software Minitab se ingresan los datos en la hoja de trabajo y se corre la prueba de normalidad de Anderson Darling, obteniéndose los siguientes resultados que se muestran en la Figura 1.
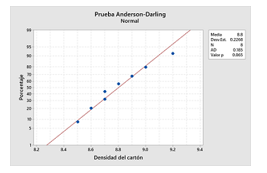
Nota: Adaptado de los datos proporcionados por Servicartón Cía. Ltda.
Si se considera que el valor p es una probabilidad que mide la evidencia en contra de la hipótesis nula. Un valor p más pequeño proporciona una evidencia más fuerte en contra de la hipótesis nula. Valores más grandes del estadístico de Anderson-Darling indican que los datos no siguen la distribución normal. En este caso, por cuanto el valor p resultante 0,865 es mayor que el nivel de significancia α de 0,01, existe suficiente evidencia para no rechazar la hipótesis nula y concluir que los datos siguen la distribución normal. Por lo tanto, la gerencia puede aplicar un estadístico paramétrico para contrastar la hipótesis de igualdad de las medias relacionada con la densidad de los cartones corrugados que está produciendo.
La gerencia de Servicartón Cía. Ltda. (2020) toma otra muestra con 20 observaciones, asimismo, de la densidad del cartón corrugado que está produciendo para determinar si dicha densidad se ajusta al estándar establecido. No obstante, previamente necesita comprobar que los datos siguen la distribución normal para aplicar un estadístico paramétrico. Se decide trabajar con un nivel de significancia de 0,01. Las medidas de densidad de la muestra seleccionada se muestran en la Tabla 2.
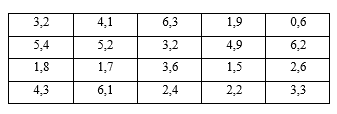
Utilizando el software Minitab se ingresan los datos en la hoja de trabajo y se corre la prueba de normalidad de Ryan-Joiner, obteniéndose los resultados que se muestran en la Figura 2.
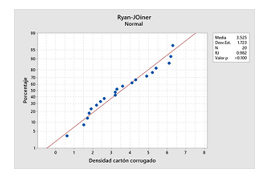
Adaptado de los datos proporcionados por Servicartón Cía. Ltda.
Esta prueba, Ryan-Joiner, evalúa la normalidad calculando la correlación entre los datos y las puntuaciones normales de los datos. Si el coeficiente de correlación se encuentra cerca de 1, es probable que la población sea normal. En esta muestra de 20 observaciones, como el valor RJ resultante es 0,982 se encuentra cercano a 1, se tiene suficiente evidencia para no rechazar la hipótesis nula y concluir que los datos siguen la distribución normal. Por lo tanto, la gerencia puede aplicar un estadístico paramétrico, como por ejemplo t-student, para contrastar la hipótesis de igualdad de las medias relacionada con la densidad de los cartones corrugados que está produciendo.
Si se aplica la ecuación 4 de la prueba de Ryan-Joiner, trabajando en Excel se tiene que, luego de encontrar los valores de las observaciones ordenadas, las puntuaciones normales de los datos ordenados y la varianza de la muestra, el valor RJ es similar al obtenido utilizando Minitab como se muestra en la ecuación Y, llegándose a la misma conclusión con respecto al contraste de la hipótesis de normalidad de datos, con la diferencia que este proceso en Excel sigue un mayor número de pasos y requiere una mayor cantidad de cálculos que en Minitab.
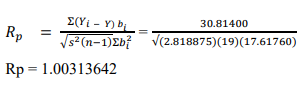
Por otra parte, como se explica en la fundamentación teórica del presente artículo, la prueba de Ryan-Joiner es similar a la de Shapiro-Wilk. Esto es, el software Minitab utilizado en este estudio de caso, utiliza el procedimiento similar tanto para calcular la prueba de normalidad de datos Ryan-Joiner como la Shapiro-Wilk.
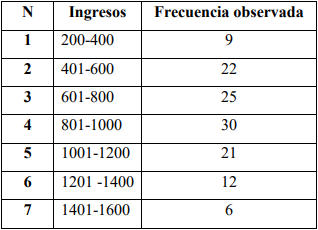
La gerencia de Servicartón Cía. Ltda. (2020) está interesada en conocer si los ingresos de la fuerza de ventas en un período determinado -septiembre del año 2020- están dentro de los rangos establecidos por la empresa. Se toma una muestra con 125 observaciones que se las distribuye por intervalos de clase, de acuerdo con la Tabla 3. No obstante, previo a aquello se necesita comprobar que los datos siguen la distribución normal para aplicar un estadístico ya sea paramétrico o no paramétrico, según sea el resultado de la prueba de normalidad aplicada. En este caso se decido utilizar la prueba de normalidad de Kolmogórov-Smirnov
Utilizando el software Minitab se ingresan los datos en la hoja de trabajo y se corre la prueba de normalidad de Kolmogórov-Smirnov, obteniéndose los resultados que se muestran en la Figura 3.
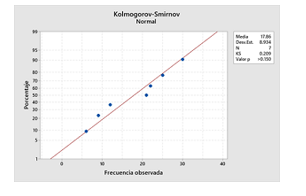
Nota: El estadístico KS tiene un valor de 0,209, el valor p es >0,150, número de observaciones 7, media aritmética 17,86 y el valor de la desviación estándar de 8,934.
Minitab utiliza el estadístico de Kolmogórov-Smirnov para calcular el valor p. El valor p es la probabilidad de obtener el estadístico de prueba Kolmogórov-Smirnov, que es por lo menos tan extremo como el valor que se calcula a partir de la muestra, cuando los datos son normales. Valores más grandes del estadístico de Kolmogórov-Smirnov indican que los datos no siguen la distribución normal. En esta muestra de 7 observaciones, como el valor de p resultante >0,150 es mayor que el nivel de significancia α de 0,01, existe suficiente evidencia para no rechazar la hipótesis nula y concluir que los datos siguen la distribución normal. Por lo tanto, la gerencia puede aplicar un estadístico paramétrico para determinar si los ingresos de la fuerza de ventas, durante el mes de septiembre del año 2020, están dentro de los rangos establecidos por la empresa.
La hipótesis de normalidad de datos en el presente caso de estudio ha sido confirmada para los datos estudiados, estableciéndose la posibilidad de aplicación de alguno de los estadísticos paramétricos que pueden utilizarse con los datos proporcionados por la empresa Servicartón Cía. Ltda., por ejemplo, la prueba t-student o cualquier otra prueba paramétrica pertinente, para contrastar la medias aritméticas de las densidades del producto cartón corrugado y si éstos se ajustan a un determinado estándar de variación definido por la empresa o si los ingresos de la fuerza de ventas en un período determinado están dentro de los rangos establecidos, entre otros procesos productivos y de gestión administrativa que pueden analizarse en una empresa. Evidenciándose, con ello, que los resultados del presente estudio son consistentes con la teoría explicada por Flores-Tapia & Flores-Cevallos (2017); Levin et al. (2014); Lind (2012a); Triola (2018), entre otros.
El artículo verifica que se pueden utilizar satisfactoriamente las pruebas de normalidad de datos, particularmente las aplicadas en esta investigación de caso. En tal sentido, a lo largo del artículo se ha ido alcanzando el objetivo de la investigación planteado, esto es, verificar el supuesto de normalidad en muestras de datos relacionados con procesos industriales de la empresa Servicartón Cía. Ltda., mediante la aplicación de las pruebas de Anderson-Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov.
Por otra parte, cabe señalar que la aplicación de las pruebas de Anderson-Darling, Ryan-Joiner, Shapiro-Wilk y Kolmogórov-Smirnov para la normalidad de datos con el apoyo de herramientas informáticas, como por ejemplo Minitab y otros programas especializados, agilizan los tiempos de procesamiento y ahorran costos significativos para las organizaciones que necesitan información oportuna para la toma de decisiones técnicas, confirmando su utilidad, más aún si las condiciones internas y del entorno empresarial resultan cada vez más complejas, tal como ocurre actualmente con la crisis generada por el COVID-19. No obstante, es necesario recordar que este tipo de técnicas tienen también limitaciones relacionadas con el tipo de muestreo, la recolección de datos, y otros aspectos inherentes al tratamiento estadístico. Lo señalado no significa que su utilidad es cuestionable, por cuanto los tomadores de decisiones empresariales utilizan esta información para diseñar modelos, sistemas y procesos que funcionen bien y contribuyan al logro de los objetivos de la organización.
Nota: Adaptado de los datos proporcionados por Servicartón Cía. Ltda.
Adaptado de los datos proporcionados por Servicartón Cía. Ltda.
Nota: El estadístico KS tiene un valor de 0,209, el valor p es >0,150, número de observaciones 7, media aritmética 17,86 y el valor de la desviación estándar de 8,934.


