

Herramienta de software para la detección de armas cortas en imágenes de rayos X.
Software tool for the detection of small arms in X-ray images.
Innovación tecnológica (Las Tunas)
Centro de Información y Gestión Tecnológica y Ambiental de Las Tunas, Cuba
ISSN-e: 1025-6504
Periodicidad: Trimestral
vol. 25, núm. 1, 2019
Recepción: 05 Octubre 2018
Aprobación: 24 Enero 2019
Resumen: En este trabajo se presenta el desarrollo de una herramienta de software que describe un procedimiento basado en el algoritmo Saco de Palabras Visuales para la detección de armas cortas. El sistema creado sirve de apoyo a los especialistas radiólogos en la exploración de bultos, mercancías y valijas en busca de objetos peligrosos en el proceso de inspección aduanal mediante equipos de rayos X, lo cual ha devenido en una importante tecnología para aplicaciones de seguridad. En los experimentos realizados se obtiene una razón de verdaderos positivos de un 93%. Además se logra reducir en un 65% el tiempo de ejecución del algoritmo propuesto a través de técnicas de ejecución multiproceso mediante la interfaz de programación System Threading Task para el lenguaje C#. Los resultados obtenidos demuestran que los valores de acierto del método implementado son coherentes con respecto a otros estudios realizados. De la misma forma exponen la factibilidad del uso de la programación concurrente en procesadores con varios núcleos con el propósito de alcanzar tiempos de ejecución más rápidos en un hardware convencional.
Palabras clave: imágenes de rayos X, saco de palabras visuales, rendimiento, C#.
Abstract:
This paper describes the development of a software tool that describes a procedure based on the Bags of Visual Words algorithm for detection of small arms is presented. The system created serves to support specialist radiologists in the exploration of packages, goods and bags for dangerous objects in the process of customs inspection by X-ray equipment, which has become an important technology for security applications. In experiments it is obtained a ratio of true positives of 93%. Moreover it is possible to reduce by 60% the time of execution of the algorithm proposed by multithreaded execution techniques using System. Threading. Task interface for the C# programming language. The results show that the values of success of implemented method are consistent with respect to other studies. Similarly expose the feasibility of using concurrent programming on multi-core processors in order to achieve faster execution times in a conventional hardware.
Keywords: X-ray images, bag of visual words, C#, performance.
INTRODUCCIÓN
En la actualidad, en contraste con la alta especialización de los técnicos radiólogos y la utilización de equipos de rayos X de última generación en la inspección de equipajes en puertos y aeropuertos, subsisten dificultades, que en ocasiones impiden el normal desarrollo de esta actividad. Cada vez más es deseable la implementación de herramientas que reduzcan la carga de trabajo de los especialistas, mejoren la eficiencia en la clasificación de objetos y aumente la velocidad del procedimiento, siempre teniendo como premisa que no se desea eliminar del todo la labor consiente del hombre sino humanizar, fortalecer y complementar su tarea (Bastan, Yousefi, & Breuel, 2011).
En los últimos años, se han llevado a cabo investigaciones científicas que viabilizan la detección de objetos peligrosos en imágenes de rayos X. Uno de los métodos empleados es el algoritmo Saco de Palabras Visuales o Bag of Visual Words (BoVW), propuesto en sus inicios por (Csurka, Dance, Fan, Willamowski, & Bray, 2004) para la búsqueda de imágenes por contenido. Más tarde (Bastan, Byeon, & M, 2013) y (Turcsany, Mouton, & Breckon, 2013) extienden la utilización de esta técnica a las imágenes de rayos X en sistemas de transmisión de energía simple para reconocer materiales ilícitos. Otra contribución en esta área del conocimiento la realiza (Castro, Sanabria, Marañón, & Rodriguez, 2016) con la utilización de imágenes de equipos de energía dual y el estudio de la influencia de diferentes kernels, funciones de pérdida y vocabularios en la clasificación de armas cortas.
De forma general existe una bibliografía limitada sobre el tema y las investigaciones realizadas que utilizan este algoritmo difieren entre ellas, tanto en los experimentos realizados como en los tipos de imágenes empleadas. Además no se presentan datos relevantes acerca de los tiempos de ejecución de los algoritmos siendo este punto de vital importancia en la implantación de una solución informática. El presente trabajo tiene como objetivo la implementación de un componente de software que lleve a cabo un procedimiento basado en el algoritmo BoVW, teniendo en cuenta especial énfasis en la reducción del tiempo de ejecución mediante técnicas de programación multiproceso que permitan la utilización al máximo de las potencialidades de los procesadores con múltiples núcleos integrados en los equipos de cómputo de uso cotidiano hoy en día.
Método Saco de Palabras Visuales
El método Saco de Palabras Visuales está constituido por tres fases, en su desarrollo se utilizan tanto algoritmos de clasificación supervisada como no supervisada. La primera fase se basa en la construcción de un vocabulario de palabras visuales empleando como fuente una base de datos de imágenes.
La segunda etapa tiene como objetivo el entrenamiento de un clasificador binario a través de histogramas de palabras visuales, el más utilizado en este caso es la Maquina de Soporte Vectorial o Support Vector Machine (SVM), (Vapnik & Vapnik, 1998). Los histogramas se construyen mediante una cuantificación vectorial de los rasgos extraídos de la imagen con el vocabulario de palabras visuales.
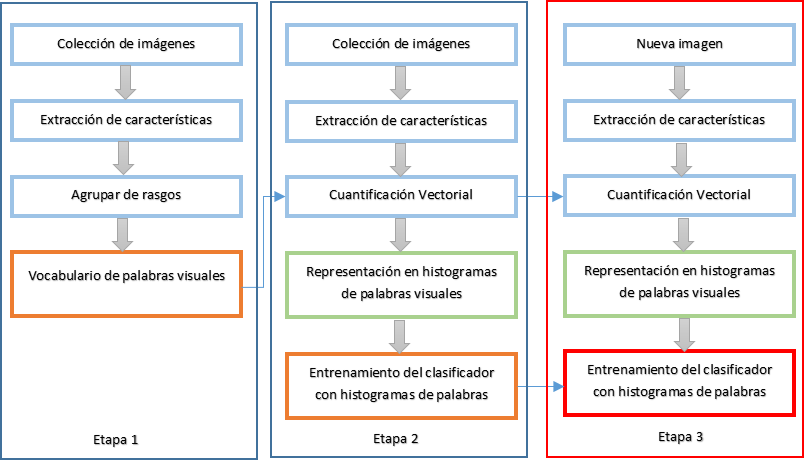
La tercera fase utiliza los datos de las dos etapas anteriores, el vocabulario de palabras visuales y el entrenamiento del clasificador basado en los histogramas del universo de imágenes. Es el proceso mediante el cual se logra la clasificación de una nueva imagen, no contenida en el proceso de entrenamiento. Para ello la nueva imagen es transformada en un histograma de palabras visuales, y comparada en el clasificador SVM quien determina si el histograma pertenece o no a la clase objetivo.
Las dos primeras etapas se caracterizan por una enorme sobrecarga computacional y se realizan de forma offline, o sea en el proceso de entrenamiento del algoritmo. Hasta aquí, la meta consiste en ajustar los parámetros de configuración del método con el propósito de lograr un porciento elevado de reconocimiento de los objetos que se desean identificar en las imágenes. La tercera etapa se realiza de forma online (en tiempo real) y se debe identificar por ser mucho más rápida que las fases anteriores. Esta última fase es la que se propone potenciar mediante una implementación robusta, extensible y con tiempos de respuesta cortos que permita su utilización por parte de los especialistas como ayuda en el proceso de inspección, ya que no resulta viable técnicamente un algoritmo con una alta tasa de reconocimiento si este se ejecuta lentamente.
MATERIALES Y MÉTODOS
En la fase de entrenamiento, pertenecientes a la etapa 1 y 2 del algoritmo BoVW se utilizó MATLAB 2014ª y la biblioteca de funciones VLFeat 0.9.18 (Vedaldi & Fulkerson, 2010), como herramientas para la creación de las matrices que representan al vocabulario de palabras visuales y el entrenamiento de clasificador SVM. Luego estas son cargadas para su utilización en la etapa 3, la cual fue implementada empleando el lenguaje de programación C# y el algoritmos de visión por computadoras contenidos en la librería OpenCV 2.4.11. Con el propósito de mejorar los tiempos de ejecución de la etapa 3 se explotaron las potencialidades que brinda el espacio de nombres System.Threading.Task del framework de .Net para la programación multiproceso de memoria compartida. En la ejecución se utiliza una ventana deslizante, para la detección de los objetos, la cual evalúa el clasificador en múltiples regiones de la imagen objetivo.
Entrenamiento del clasificador SVM
En la implementación se siguieron las pautas descritas por Castro para el método BoVW, debido a los buenos resultados del experimento aplicado y por el tipo de imágenes de rayos X con que se realizaron las pruebas. Estas imágenes pertenecen a equipos de inspección de energía dual, de amplia difusión en la actualidad; las cuales permiten una estimación de la densidad y el número atómico de los materiales mediante tonos de color que van desde el naranja para los materiales orgánicos hasta el azul para los materiales inorgánicos, pasando por el verde para los materiales intermedios (Bastan et al., 2011).
Se empleó en la extracción de características el algoritmo PHOW (Pyramid Histogram Of Visual Words) propuesto por (Bosch, Zisserman, & Munoz, 2007), con las opciones de configuración de Castro, teniendo en cuenta que los objetos en las imágenes de rayos X poseen poca textura y es necesario obtener mucha más información para su clasificación. En el agrupamiento de las características se recurrió al algoritmo kmeans y se construyó un vocabulario universal de 1000 palabras utilizando las características extraídas en las regiones metálicas de las imágenes en la base de datos.
Los histogramas se construyeron normalizados, usando asignación dura (hard assigment) y el kernel homogéneo aditivo 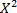 (chi-cuadrado) con la función de pérdida
(chi-cuadrado) con la función de pérdida
Square (L2). El parámetro de regularización λ del algoritmo de entrenamiento se determinó en valor de λ = 0,0001. En el proceso de entrenamiento del algoritmo clasificador no se utilizaron las imágenes originales, sino las instancias de la ventana deslizante.
Rendimiento de computadores paralelos
Una forma de medir la calidad de un sistema paralelizado consiste en comparar la velocidad conseguida en el sistema paralelo (con 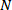 procesadores) con la velocidad
procesadores) con la velocidad
conseguida con un solo procesador (Berstein, 1966). Para ello se define la ganancia de velocidad o aceleración (speed up) de un sistema de 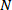 procesadores como:
procesadores como:

Donde 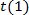 es el tiempo empleado para ejecutar el proceso si se utiliza un solo procesador
es el tiempo empleado para ejecutar el proceso si se utiliza un solo procesador 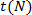 y es el tiempo empleado para ejecutarlo
en el sistema paralelo con procesadores. En condiciones ideales,
y es el tiempo empleado para ejecutarlo
en el sistema paralelo con procesadores. En condiciones ideales, 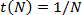 con lo que, en esas mismas condiciones, la ganancia de velocidad dada por la ecuación 1.1 será
con lo que, en esas mismas condiciones, la ganancia de velocidad dada por la ecuación 1.1 será

Una forma de medir el rendimiento de un sistema resulta de comparar la ganancia de velocidad del mismo con la ganancia de velocidad ideal dada por 1.2, a esta medida se le denomina eficiencia:

La ley de Amdahl (1967) pone un límite superior a la ganancia en velocidad, y por tanto también a la eficiencia, de un sistema paralelo atendiendo al hecho, de que los procesos suelen tener partes que no pueden ser ejecutadas en paralelo, sino solo de forma secuencial pura. De esta forma puede verse que:

Llamando 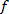 a la fracción de tiempo que no se puede paralelizar sobre el total del tiempo de ejecución.
a la fracción de tiempo que no se puede paralelizar sobre el total del tiempo de ejecución.
RESULTADOS Y DISCUSIÓN
En esta sección se describen los resultados obtenidos en distintos experimentos realizadas en la etapa 3 del algoritmo. Además se presenta el diagrama de bloques de la implementación creada, así como la dependencia de datos existente entre cada uno de los componentes que facilita la ejecución en paralelo del algoritmo. Se realiza un estudio del comportamiento en distintos procesadores y entornos de hardware y se calcula la medida de la mejora obtenida en cada arquitectura.
Evaluación de la clasificación
Se emplearon 172 imágenes de rayos X en formato PNG que pertenecen a equipos de inspección de energía dual, estas no han sido utilizadas en el proceso de entrenamiento del algoritmo, contienen al menos un arma corta y tienen un tamaño promedio de 573x515 píxeles. Como promedio se ejecutan 116 ventanas deslizantes que evalúan el clasificador a lo largo y ancho de cada imagen.

Las armas en las imágenes de prueba aparecen en diversas condiciones con diferentes niveles de complejidad para la detección de los objetos que fueron catalogadas en los siguientes grupos, 1: objetos con oclusión propia, 2: solapadas con objetos metálicos, 3: partes no metálicas, 4: distorsión geométrica de la adquisición, 5: parcialmente desarmada y 6: visible frontal simple (Figura 2). Existen también armas que contienen una combinación de las situaciones que se describen.

2: Detección falsa positiva
Se alcanzó un 93.02% de reconocimiento de armas cortas como se observa en la tabla 1. El total de ventanas evaluadas (19952) se calculan multiplicando las 172 imágenes de la base de datos por las 116 ventanas deslizantes que se evalúan en cada imagen. Del total han sido marcadas como ventanas falsas positivas sólo 149 lo cual representa el 0.74%, las múltiples detecciones sobre un objeto son mezcladas para mostrar una sola detección (Figura 3). Comparando los resultados con otras implementaciones existe una diferencia de sólo un -3% respecto a lo logrado por Castro (2016), aunque se utilizan diferentes bases de datos para la evaluación se reafirma la viabilidad del método al considerarse buenos los resultados obtenidos.
| Imágenes | Imágenes clasificadas | % | Ventanas evaluadas | Ventanas Falsas Positivas |
| 172 | 160 | 93.02 | 19952 | 149 |
Análisis del desempeño
En la evaluación del desempeño se emplearon técnicas de programación paralela para determinar la ganancia de velocidad en el tiempo de ejecución en la etapa 3 del algoritmo. Las pruebas se realizaron en una computadora personal Core i3 de 4 núcleos a 3.1GHz, 4GB de RAM con sistema operativo Windows7. Se determinó el tiempo de ejecución en las 19952 ventanas deslizantes de las 172 imágenes de la base de datos y se obtuvo el promedio del tiempo para una sola ventana. Lo valores de tiempo en cada prueba fueron obtenidos variando los hilos de ejecución mediante el método 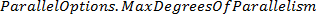 de
de 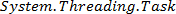
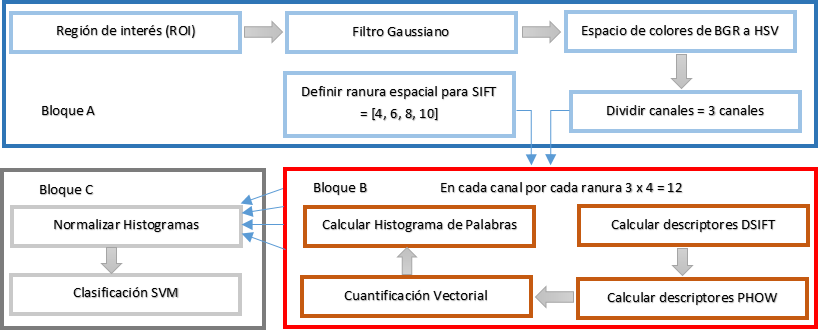
La figura 4 muestra el diagrama de bloques de la implementación realizada con algunos ajustes para permitir la división del problema en partes independientes que permitan su análisis. El bloque A corresponde a las tareas de inicialización de variables, donde se preparan las estructuras de datos necesarios para ejecutar la extracción de características que se realiza en el bloque B. Luego se construye el histograma de palabras visuales a partir de la normalización de los histogramas obtenidos en cada canal de la imagen por cada ranura espacial del SIFT y se entrega al clasificador para su evaluación (bloque C).
| Algoritmo | Secuencial | 2 Thread | 3 Thread | 4 Thread |
| Bloque A | 3.1 | 3.1 | 3.1 | 3.1 |
| Bloque B | 99,2 | 52,34 | 40,28 | 31 |
| Bloque C | 2.4 | 2.4 | 2.4 | 2.4 |
| Total | 104.7 | 57.84 | 45.78 | 36.5 |
El bloque B efectúa un proceso repetitivo en el que no existen dependencias de datos entre una y otra iteración, lo que facilita su adecuación a un entorno de ejecución paralelo. En la tabla 2 se muestra el comportamiento de los tiempos de ejecución en milisegundos de los diferentes bloques y se observa la ganancia de velocidad cuando se aumenta el número de procesadores empleados comparando los datos con la ejecución secuencial.
Cuando se efectúa la versión secuencial se observa que la fracción de tiempo de los
bloques A y C (no paralelos) representan juntos el 5.7% del tiempo total y se
mantienen inalterables en las otras versiones. La ley de Amdahl establece una cota
superior en la ganancia máxima de velocidad cuando 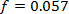 y
y 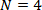 , que es
, que es 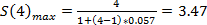 y
y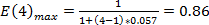 una eficiencia máxima ;
luego se comparan estos valores con la ganancia y la eficiencia obtenida en la mejor
de las pruebas. Empleando los 4 núcleos del procesador se logra una ganancia de
velocidad
una eficiencia máxima ;
luego se comparan estos valores con la ganancia y la eficiencia obtenida en la mejor
de las pruebas. Empleando los 4 núcleos del procesador se logra una ganancia de
velocidad 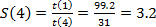 , con una eficiencia
, con una eficiencia 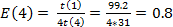 . La
. La
diferencia entre los valores máximos ideales y los obtenidos es pequeña, se encuentran en el orden de los 0.27 y 0.06 respectivamente, lo que indica que la implementación realizada aprovecha con efectividad los recursos de multiprocesamiento del procesador.
En términos de tiempo de ejecución se puede apreciar una notable mejora cuando se efectúa la versión paralela en comparación con la versión secuencial. Según la tabla 2, el procedimiento secuencial completo tarda unos 104.7 ms y ha sido mejorado hasta completar la tarea en 36.5 ms con 4 núcleos. Si se tiene en cuenta que se evalúan 116 ventanas deslizantes como promedio en cada imagen, se ha logrado reducir el tiempo de ejecución de 12.14 a 4.23 segundos, lo cual representa una mejora de un 65.15%.
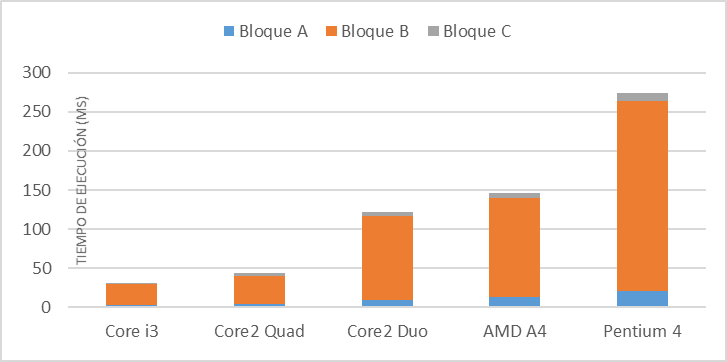
Luego de observar el comportamiento en un procesador Core i3, se realizaron pruebas en distintas configuraciones de hardware con el propósito de comparar el tiempo de ejecución del algoritmo y la ganancia de velocidad en la ejecución de la sección paralela del método implementado (Figuras 5, 6).
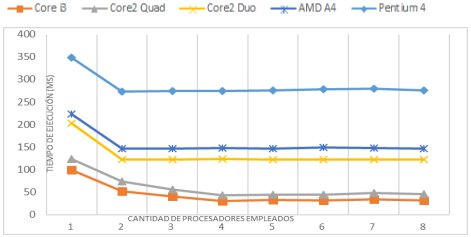
El procedimiento 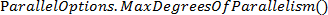 permite establecer un
permite establecer un
número mayor de hilos de ejecución que la cantidad de núcleos de procesamiento incluidos en un procesador, no obstante el algoritmo gana en velocidad hasta el número real de núcleos del procesador. De esta forma se observa una mejora en la aceleración hasta el procesador 2 en las configuraciones Pentium 4, AMD A4 3305,Core2 Duo, los cuales tienen 2 núcleos de procesamiento. En el caso del Core2 Quad y el Core i3 se observan ganancias hasta los 4 hilos de ejecución. La figura 7 muestra en perspectiva los tiempos de ejecución de cada uno de los bloques en los diferentes procesadores.
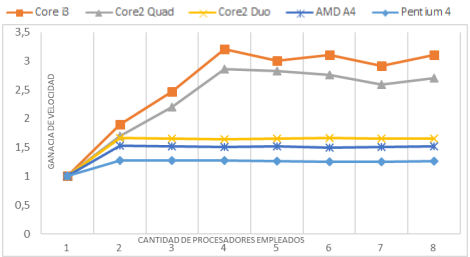
Si bien las ganancias en velocidad y la eficiencia de los procesadores en las diferentes arquitecturas de hardware dependen de otros factores como la velocidad del disco duro, la memoria RAM, la velocidad y caché del CPU, el coprocesador matemático o el sistema operativo empleado, los resultados alcanzados ofrecen una idea del comportamiento del algoritmo de forma general.
CONCLUSIONES
En este trabajo se mostró el desarrollo de un procedimiento para el reconocimiento de armas cortas en imágenes de rayos X utilizando el algoritmo Saco de Palabras Visuales. En la implementación de la herramienta de software se estableció especial énfasis en la etapa online del método que se ejecuta en tiempo real. Con el propósito de mejorar el tiempo de ejecución de la solución se identificaron los procedimientos que más tiempo consumían, se analizó la dependencia de datos existente y se llevaron a cabo mejoras con la adición de concurrencia en el procesamiento de datos. Se alcanzó una clasificación satisfactoria del 93.02% en imágenes que contenían armas de fuego, y se logró una reducción en el tiempo ejecución en paralelo de un 65.15% con respecto al tiempo de ejecución secuencial. Este trabajo, además de validar los resultados de investigaciones anteriores, contribuye a facilitar la implantación de un algoritmo de visión computacional en un entorno de producción;
donde se proporcione una ayuda más a los operadores de los equipos de rayos X, incidiendo en un proceso de inspección más rápido y preciso.
BIBLIOGRAFÍA
1. Amdahl, G. (1967). Validity of the Single Processor Aproach to Achieving Large Scale Computing Capabilities.
2. Bastan, M., Byeon, W., & M, B. T. (2013). Object Recognition in Multi-View Dual Energy X-ray Images.
3. Bastan, M., Yousefi, M. R., & Breuel, T. M. (2011). Visual words on baggage X- ray images. Springer, (págs. 360-368).
4. Berstein, A. (1966). Analysis of programs for parallel procesing. IEEE Transactions on Computers, Oct., 15.
5. Bosch, A., Zisserman, A., & Munoz, X. (2007). Image classification using random forests and ferns.
6. Castro, D., Sanabria, F., Marañón, E., & Rodriguez, F. (2016). Reconocimiento de armas en imágenes de rayos X mediante Saco de Palabras Visuales. Revista Cubana de Ciencias Informáticas, 1, 161.
Csurka, G., Dance, C., Fan, L., Willamowski, J., & Bray, C. (2004). Visual categorization with bags of keypoints., 1, págs. 1-2.
8. Jones, M., & Viola, P. (2001). Robust real-time object detection.
9. Turcsany, D., Mouton, A., & Breckon, T. P. (2013). Improving feature-based object recognition for X-ray baggage security screening using primed visualwords. IEEE, (págs. 1140-1145).
10. Vapnik, V. N., & Vapnik, V. (1998). Statistical learning theory (Vol. 1). Wiley New York.
11. Vedaldi, A., & Fulkerson, B. (2010). VLFeat: An open and portable library of computer vision algorithms. ACM, (págs. 1469-1472).

