

Red de Administradores Compartidos y su Relación con el Desempeño Financiero en Empresas del Ecuador: ¿Cuál es el efecto de compartir Capital Humano?
X-Pedientes Económicos
Superintendencia De Compañias, Valores Y Seguros, Ecuador
ISSN-e: 2602-831X
Periodicidad: Cuatrimestral
vol. 3, núm. 7, 2019
Recepción: 02 Octubre 2019
Aprobación: 21 Noviembre 2019
Resumen: La información siempre ha sido una potencial fuente de ventaja comparativa entre empresas, por lo que conocerla en su totalidad se ha vuelto una necesidad para los tomadores de decisiones. Hoy en día, existen herramientas tal como el Social Network Analysis, que permiten tener un mayor alcance para conocer el impacto de las relaciones entre los individuos. En el presente proyecto, se cuantifica el efecto que tiene el desempeño financiero al compartir capital humano y ser una empresa prominente dentro del mercado. Asimismo, se identificó comunidades en la industria, utilizando la modularidad como medida de agrupación entre empresas. Con una muestra de 9070 firmas del Ecuador en el año 2018, se planteó indicadores basados tanto del historial de administradores y las medidas de centralidad de la teoría de grafos. Se escogió al ingreso como el indicador que representa de mejor manera el desempeño financiero. Los resultados encontrados demostraron que existe un considerable efecto positivo sobre el desempeño financiero cuando una empresa es prominente en el mercado. Por otro lado, se determinó que existe un efecto negativo sobre el desempeño financiero al compartir capital humano, cuando se contrata a un trabajador que labora o laboró en una empresa del mismo sector, así como de otros sectores. Finalmente, se encontró que los indicadores que cuantifican las conexiones con empresas representan una valiosa fuente de información para las firmas.
Palabras clave: Desempeño financiero, relaciones, análisis de redes sociales, teoría de grafos.
Abstract:
Information has always been a potential source of comparative advantage between companies, so knowing it in its entirety has become a necessity for decision makers. Today, there are tools such as Social Network Analysis, which may have a greater scope to know the impact of relationships between individuals. In this project, the effect of financial performance on sharing human capital and being a prominent company in the market is quantified. Likewise, communities in the industry were identified, using modularity as a measure of grouping between companies. With a sample of 9,070 signatures from Ecuador in 2018, indicators were proposed based on the history of administrators and the centrality measures of the graph theory. Income was chosen as the indicator that best represents financial performance. The results found showed that there is a considerable positive effect on financial performance when a company is prominent in the market. On the other hand, it is determined that there is a negative effect on financial performance by sharing human capital, when hiring a worker who works or worked in a company in the same sector, as well as in other sectors of the industry. Finally, it was found that the indicators that quantify connections with companies represent a valuable source of information for firms.
Keywords: Financial performance, relationships, social network analysis, graph theory.
I. INTRODUCCIÓN
El rol que desempeñan las redes que se forman entre los miembros de los mercados laborales deben ser considerados por al menos dos razones importantes. La primera es debido a la difusión de información de ofertas de trabajo, que determinan si los mercados laborales marchan de manera eficiente; la
segunda, es que la forma de la red tiene implicaciones como la inversión de capital humano y desigualdad (Jackson, 2011).
A través del uso del Social Network Analysis y la teoría de grafos se busca determinar el efecto de compartir administradores sobre el desempeño financiero en empresas del Ecuador. Aunque tradicionalmente los tomadores de decisiones se concentraban exclusivamente en actividades dentro de la empresa, actualmente se presta mayor atención al exterior dado que las asociaciones entre grupos ayudan a crear vínculos externos necesarios para eludir consecuencias nocivas (Wältermann, et al., 2019). Las firmas están tratando de integrarse con toda su cadena para lograr un desempeño superior (Chen, et al., 2018)
Más allá de generar nuevas ideas y fomentar innovación, la importancia del presente estudio se basa en determinar si existe una relación entre el desempeño financiero de una empresa y sus conexiones con demás firmas de la industria. Además, se pretende cuantificar el impacto, ya sea positivo o negativo, de establecer vínculos entre administradores y la diferencia que estos resultados pueden generar entre los diferentes sectores de la industria. Con resultados cuantitativos sobre estos efectos, se podría planificar mejores alianzas estratégicas a través de administradores de tal manera que se incremente la productividad y sacar ventaja del talento humano. Asimismo, se busca detectar comunidades que se asocian a través de sus interacciones.
Se procederá a desarrollar dos modelos de regresión que ayudarán a responder las preguntas fundamentales del presente trabajo. Para exponer ambos modelos, se utilizará el ingreso de las empresas como la variable que expone el desempeño financiero de las mismas dado que las comparaciones de empresas basadas en los ingresos son comunes al análisis de inversiones y negocios (Recober, et al., 2009).
Red de Administradores Compartidos y su Relación con el Desempeño Financiero en Empresas del Ecuador
•Vaca, Amaguaya y Lúa.
This HTML is created from PDF at https://www.pdfonline.com/convert-pdf-to-html/
78
Basado los argumentos anteriormente expuestos, se propone responder las siguientes preguntas formales en este proyecto:
P1: ¿Cuál es el impacto sobre el desempeño financiero al compartir capital humano entre empresas que pertenecen tanto al mismo sector como a otros sectores de la industria?
P2: ¿Cuál es efecto cuantitativo sobre el desempeño financiero al ser una empresa prominente en la industria ecuatoriana?
II. TRABAJOS RELACIONADOS
Hay un gran número de literatura que examina factores que ayudan a incrementar la productividad de los individuos y las firmas, pero gran parte de ella no es actual y se concentra en industrias manufactureras donde es fácil medir la productividad mediante el conteo de bienes físicos producidos; sin embargo, con la significativa cantidad de información que crece a diario, se vuelve muy importante examinar cómo la información que intercambian los trabajadores se vuelve de gran valor (Wu, Ching-Yung, & Sinan, 2009).
El Social Network Analysis es capaz de sintetizar las relaciones en una red y puede mostrar una imagen completa tanto de estructura y calidad de la red, así como de las características de los actores (León, R.D et al., 2016). La información casual y formal en las redes de comunicación pueden ser utilizadas por los departamentos de recursos humanos para medir el nivel de las relaciones sociales que pueden mejorar el desempeño de la compañía (Zusrony et al., 2019). Los beneficios que se pudieran dar en una red dependerán del tipo de red, así como del tipo de relaciones que se tengan Warrick et al. (2019). Asimismo, Granovetter (1973) argumenta que las personas con un enlace no fuerte entre ellas son vistas como indispensables para que se desarrollen más oportunidades, y que la comunidad se integre dado que cuentan con información nueva y diferente del grupo con el que se relacionan con mayor y más frecuencia.
El círculo de influencia se define según la gran cantidad de enlaces con demás empresas; una observación interesante a partir del análisis de centralidad es que las empresas con un enlace indirecto entre ellas pueden facilitar la colusión o los comportamientos anticompetitivos (Mahdi et al., 2012). La evidencia también sugiere que la ubicación de las firmas en la red puede ser incluso más importante que el número de conexiones que esta tenga (Everad y Henry, 2002).
Aunque la evidencia expone que las relaciones que existen internamente en las firmas pueden reducir el desempeño de esta, otros estudios muestran que los enlaces externos también podrían implicar un daño (Brandes et al., 2014). Hay un rendimiento decreciente en las redes respecto a las experiencias y diversidad de información, sugiriendo que hay límites en los aprendizajes que pueden ocurrir entre las redes de comunicación (Powell et al., 1999)
III. DATASET
III.I Preprocesamiento del dataset
A través del portal web de la Superintendencia de Compañías, valores y seguros (Supercias) se obtuvo el historial de los principales administradores pertenecientes a 61,776 empresas, cantidad que correspondía al historial de empresas desde el año 1978 hasta el primer semestre del 2019.
Dado a que el estudio se centra en el periodo 2018, se realizó una primera modificación al dataset original. Para esta modificación se tomó en cuenta a aquellas personas que aparecían como administradores principales en el historial de las empresas durante el año 2018, obteniendo como resultado un total de 61,753 firmas. Se debe recalcar, que estas personas pudieron haber terminado su periodo de administración durante el año 2018 o que actualmente mantienen el cargo, por lo cual se consideró tanto la fecha de nombramiento como la de culminación de actividades en el cargo.
Posteriormente, se procedió a realizar una segunda modificación tomando en consideración la cantidad de empresas del ranking por sector, la cual brindaba información adicional sobre las características de estas. Además se realizó la eliminación de los datos vacíos para aquellas empresas en cuyo historial no contaban con el nombre de los administradores; tampoco se tomó en consideración a las empresas que poseían un ingreso por venta igual a cero, debido a que se podría perjudicar el rumbo de la investigación produciendo algún tipo de sesgo en el resultado final. Como resultado de esta segunda modificación se obtuvo un total de 15,015 empresas.
Finalmente, debido a que el estudio se basa en las relaciones entre empresas a través de los administradores compartidos, se efectuó una tercera modificación al dataset. Para esta modificación se consideró solo aquellas firmas que tuviesen en su historial durante el año 2018, al menos, más de un administrador en común con otras empresas, dando como resultado un total de 9,070 empresas para el dataset final.
III.II Descripción del dataset
Con un total de 9,070 firmas en el dataset, para la cual cada una de ellas cuenta con su respectivo historial de los principales administradores. Dicho historial contiene información, tal como el nombre del administrador, cédula del administrador, fecha de nombramiento, fecha de finalización en el cargo y tiempo de duración en el cargo.
El dataset contiene un porcentaje de empresas correspondientes a cada uno de los sectores económicos; las 9,070 empresas se encuentran desglosadas de la siguiente manera: 3,822 corresponden al sector comercio, 1,579 al sector inmobiliaria, 1,576 al sector agrícola, 1,375 al sector manufactura y 718 al sector construcción. Además, las empresas fueron separadas de acuerdo con su tamaño, en el que se tiene que 1,273 empresas grande, 2,003 empresas mediana, 32,82 empresas pequeña y 2,512 microempresas. La figura 1 se muestra los valores porcentuales acerca de la distribución de las empresas de acuerdo con su sector y tamaño.
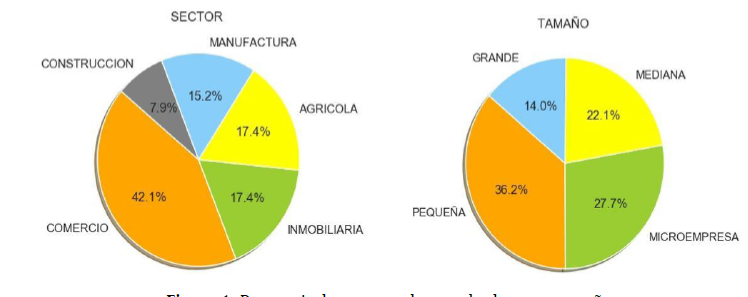
Para evaluar las relaciones entre compañías se usó variables construidas tanto con el historial de los principales administradores como las medidas de centralidad por parte de la teoría de grafos. Con dicho historial se realizó suma del total de conexiones basándose en la cantidad de administradores en común de cada empresa, posteriormente dicha sumatoria es separada para el total de conexiones con empresas que pertenecen al mismo sector y para el resto de los sectores. Por parte de la teoría de grafos, las medidas de centralidad utilizadas fueron eigen, betweenness y closeness centrality. El grupo de variables mencionadas anteriormente se las definirá como Métricas de Conexiones para futuras referencias.
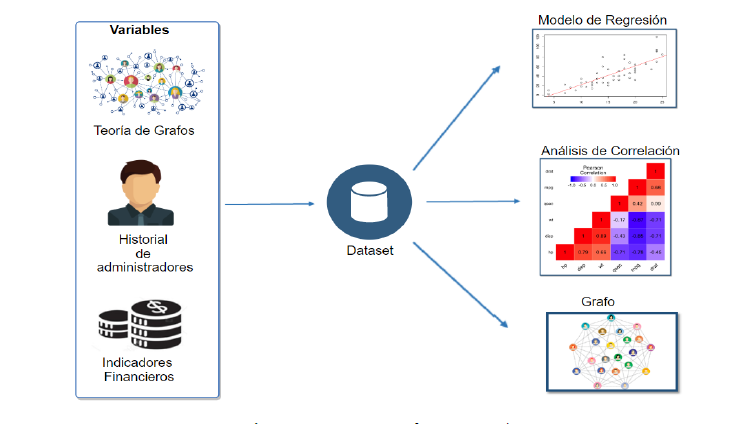
Los indicadores financieros utilizados durante este análisis fueron el nivel de ingreso por venta y utilidad. Además, se consideró las características que tiene cada empresa tales como el tamaño y sector al que pertenece. En la sección V se analizará y discutirá la influencia que tienen las variables que evalúan las relaciones entre empresas frente a los indicadores financieros. En la figura 2 se muestra el proceso usado para la obtención de los resultados en esta investigación.
En total se utilizó 9 variables para realizar esta investigación, 5 variables que cuantifican las relaciones entre empresas, 2 variables corresponden a indicadores financieros y 2 corresponden a características de las empresas. La tabla 1 muestra las principales variables utilizadas y su respectiva descripción.
A través de los modelos planteados se evalúa la relación entre el desempeño financiero con las variables construidas, tanto del
historial de administradores como de la teoría grafos.
| Variable | Descripción |
| Adm_mismo_sector | Cantidad de administradores compartidos con empresas que |
| pertenecen al mismo sector económico. | |
| Adm_otro_sector | Cantidad de administradores compartidos con empresas que |
| pertenecen a diferentes sectores económicos. | |
| Eigen_Centrality | Mide que tan influyente es una compañía en la industria. |
| Betweenness_Centrality | Mide el grado de intermediación de una empresa entre las |
| interacciones de las firmas en la red. | |
| Closeness_Centrality | Mide que tan estratégica es la posición de una empresa, de |
| tal manera que tenga acceso a la información en la red. | |
| Log_ingreso | Logaritmo natural del ingreso por venta |
| Log_utilidad | Logaritmo natural de la utilidad |
| Tamaño | Clasificación de la dimensión de una empresa, de acuerdo a |
| sus características. | |
| Sector | Clasificación del sector económico al que pertenece una |
| firma. | |
| Tabla 1. Descripción de variables. |
IV. METODOLOGÍA
Se utiliza las Métricas de Conexiones en base al historial de administradores y la teoría de grafos para estimar el efecto que tienen las relaciones entre empresas. La métrica construida con el historial de administradores para cada empresa presenta la siguiente fórmula:
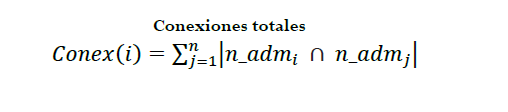 (1
(1Donde:
𝐶𝑜𝑛𝑒𝑥(𝑖): Es la cantidad total de conexiones de la empresa 𝑖 con el resto de las empresas.
𝑛_𝑎𝑑𝑚𝑖: Son los administradores que se encuentran en el historial de la empresa 𝑖 durante el periodo 2018.
𝑛_𝑎𝑑𝑚𝑗: Son los administradores que se encuentran en el historial de la empresa 𝑗 durante el periodo 2018
Por otro lado, para el cálculo de las medidas de Centralidad de la teoría de grafos se construyó una red, la cual está conformada por nodos y arcos, donde los nodos representan a los actores en un grafo y los arcos son las relaciones entre estos actores. En el grafo definimos como nodos a las compañías y a los arcos como la cantidad total de administradores en común. Para el cálculo de las medidas de centralidad se utilizó un grafo no dirigido. Una vez construido el grafo se realizó el cálculo de las variables presentando la siguiente fórmula:
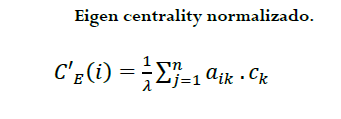 (2)
(2)Donde:
∙𝐶′𝐸(𝑖): Es el valor de eigen centrality normalizado para el nodo 𝑖
∙𝑐𝑘 : Es el valor de eigen centrality de los nodos vecinos de 𝐶′𝐸(𝑖)
∙𝜆: Es una constante equivalente al mayor valor absoluto del vector propio dominante de la matriz de adyacencia
∙𝑎𝑖𝑘: Son los valores de la matriz de adyacencia entre la empresa 𝑖 y 𝑘
Esta métrica fue propuesta por Philip Bonacich (1972), y para su cálculo se utilizó el método de potencia.
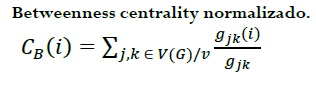 [3]
[3]
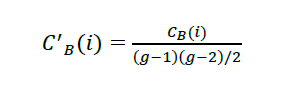 (4
(4Donde:
∙𝐶𝐵(𝑖): Es el betweenness centrality para el nodo 𝑖
∙𝐶′𝐵(𝑖): Es el betweenness centrality para el nodo 𝑖 normalizado
∙𝑔𝑗𝑘: Es el número de rutas más cortas que conectan cualquier par de nodos 𝑗 y 𝑘
∙𝑔𝑗𝑘(𝑖): Es el número de rutas más cortas que pasen a través de un nodo i para conectar a cualquier par de nodos j y k. Pero que el nodo i sea distinto de 𝑗 o 𝑘
∙𝑔: Es el número total de nodos en el grafo
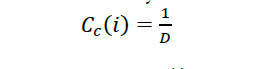 [5]
[5]
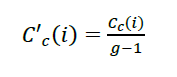 [6]
[6]Donde:
∙𝐶𝑐(𝑖): Es el closeness centrality para el nodo 𝑖
∙𝐶′𝑐(𝑖): Es el closeness centrality normalizado para el nodo i normalizado
∙𝐷: Suma de la distancia del nodo 𝑖 hasta un nodo 𝑗, cuando 𝑖 es distinto 𝑗
𝑔: Es el número total de nodos en el grafo
Betweenness centrality normalizado fue propuesto por Freeman (1978)y closeness centrality normalizado por Murray Beauchamp (1965). Ambas métricas fueron calculadas con el algoritmo de Brandes (2001) con un total de 100 iteraciones.
Con el propósito de evaluar la relación entre las Métricas de Conexiones y los indicadores financieros, se utiliza el coeficiente de correlación de Spearman (1904). El uso de este coeficiente es debido a que los supuestos de este método son menos estrictos, así como no asumir normalidad en los datos y además de ser robusto en presencia de valores atípicos. A continuación, se presenta la fórmula usada para el cálculo del coeficiente de correlación de Spearman:
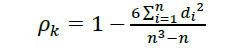 [7]
[7]Una vez analizadas las relaciones entre las métricas anteriormente mencionadas se proponen 2 modelos de regresión lineal múltiple. Estos modelos tienen como objetivo estimar el efecto que tienen las Métricas de Conexiones frente al desempeño financiero y encontrar buenas variables predictoras para este indicador.
En el primer modelo se emplea la cantidad total de conexiones y el nivel de ingreso, pero la variable total de conexiones se desagrega en total de conexiones con empresas del mismo sector y para otros sectores. Además, para este modelo se emplea la interacción de las variables desagregadas.
Por otro lado, en el segundo modelo se manejan las variables eigen centrality y el nivel de ingreso. En la figura 3 eigen centrality posee la mayor correlación con el nivel de ingreso entre las medidas de centralidad. En estos 2 modelos empleamos la variable de control que es el tamaño de las compañías, creando variables dummy para cada categoría.
 [8]
[8]
 [9]
[9]Donde:
∙𝐿𝑜𝑔_𝑖𝑛𝑔𝑟𝑒𝑠𝑜𝑖: Logaritmo del ingreso para la empresa 𝑖
∙𝐴𝑑𝑚_𝑚𝑖𝑠𝑚𝑜_𝑠𝑒𝑐𝑡𝑜𝑟𝑖: Cantidad total de administradores compartido de la empresa 𝑖 con otras que pertenecen al mismo sector de la industria
∙𝐴𝑑𝑚_𝑜𝑡𝑟𝑜_𝑠𝑒𝑐𝑡𝑜𝑟𝑖: Cantidad total de administradores compartido de la empresa 𝑖 con otras que pertenecen a otros sectores industriales
∙𝐸𝑖𝑔𝑒𝑛_𝐶𝑒𝑛𝑡𝑟𝑎𝑙𝑖𝑡𝑦_𝑁𝑜𝑟𝑚 𝑖: Valor de eigen centrality normalizado para la empresa 𝑖
∙𝑡𝑎𝑚𝑎ñ𝑜𝑖: Dimensionalidad de una empresa 𝑖
𝜏: Retorno porcentual sobre los ingresos cuando la empresa 𝑖 tiene conexiones más densas con las demás firmas.
∙𝛽, 𝜙: Efecto sobre los ingresos cuando una empresa 𝑖 es de tamaño mediano
∙𝛾: Retorno porcentual sobre los ingresos cuando se contrata a un administrador adicional que dirige o ha dirigido a una empresa en el mismo sector industrial
∙𝛿: Retorno porcentual sobre los ingresos cuando se contrata a un administrador adicional que dirige o ha dirigido a una empresa en otros sectores industriales
∙𝛼: Retorno porcentual sobre los ingresos cuando se contrata a un administrador adicional que dirige o ha dirigido tanto a una empresa en el mismo sector como en otros sectores industriales
∙𝜃, 𝜇 ∶ Efectos sobre los ingresos cuando una empresa 𝑖 es de tamaño grande, pequeño y micro
∙𝜀𝑖: Término de error del modelo 1
∙𝑣𝑖 : Término de error del modelo 2
Los resultados obtenidos del análisis de regresión y correlación serán expuestos con mayor detalle en la sección V.
Adicionalmente, se realizó la búsqueda de comunidades a través de la maximización de la modularidad. La modularidad es una característica en la estructura de las redes que se encarga de medir la fuerza de la división de una red en grupos. El método empleado es el algoritmo de Louvain, este algoritmo consiste en primero encontrar grupos pequeños al optimizar la modularidad local para cada uno de los nodos. Posteriormente cada grupo pequeño se lo agrupa a un nodo y se repite este proceso hasta alcanzar la convergencia. La modularidad presenta la siguiente formulación:
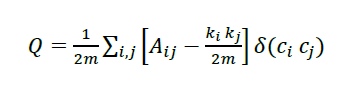 [10]
[10]V. RESULTADOS
V.I Análisis de correlación
Como primera etapa se analizó la correlación entre los indicadores financieros y las Métricas de Conexiones, dichos resultados se muestran en un mapa de calor de la figura 3. Cabe mencionar que los indicadores financieros fueron transformados de manera logarítmica. Además, se propuso las siguientes hipótesis:
H1. Existe una relación entre indicadores financieros y el número total de conexiones.
Se realizó la correlación entre la cantidad total de conexiones con cada uno de los indicadores financiero, y se halló que estas correlaciones fueron positivas para todos los casos. Los resultados de estas correlaciones
fueron 0.126 para el ingreso y 0.16 para la utilidad. Todas estas correlaciones fueron estadísticamente significativas al menos con un p-value del 0.05.
H2. Existe una relación entre indicadores financieros y medidas de centralidad.
∙Eigen centrality
Los resultados de la correlación entre eigen centrality y los indicadores financieros fueron 0.114 para el ingreso y 0.163 para la utilidad. Todas estas correlaciones fueron positivas y estadísticamente significativas al menos con un p-value del 0.05.
∙Betweenness centrality
Los resultados de la correlación entre betweenness centrality y los indicadores financieros fueron 0.11 para el ingreso y 0.128 para la utilidad. Todas estas correlaciones fueron positivas y estadísticamente significativas al menos con un p-value del 0.05.
∙Closeness centrality
Los resultados de la correlación entre closeness centrality y los indicadores financieros fueron - 0.133 para el ingreso y -0.094 para la utilidad. Todas estas correlaciones fueron positivas y estadísticamente significativas al menos con un p-value del 0.05.
Los resultados obtenidos de H1 y H2 a través del análisis de correlación demostraron que existe una relación positiva entre los indicadores financieros y las métricas de conexiones, a excepción de closeness centrality. Además, los resultados de las hipótesis muestran que para el indicador utilidad se encontró que existe una mayor relación con total de conexiones y eigen centrality en comparación con resto de Métricas de Conexiones.
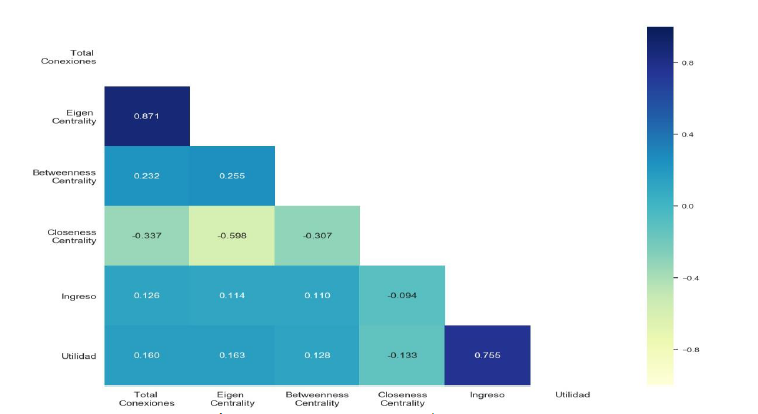
La máxima correlación negativa que se aprecia en el Mapa de Calor mostrado en la figura 3 se da entre las variables eigen centrality y closeness centrality, que tiene un valor de -0.598. Se observa una relación inversa entre estas variables debido a que empresas con una alta conexión con firmas prominentes, no necesariamente tienen un rápido acceso a la información dentro de la industria. Por otro lado, estas empresas resultan tener una moderada participación como intermediarias al interactuar con otras firmas, esto visualiza en la figura 3 al correlacionar eigen y betweenness centrality con un valor de 0.255.
Para el caso del ingreso, se halló que tanto el total de conexiones y eigen centrality tienen las más altas correlaciones para este indicador, con valores de 0.126 y 0.114. Posteriormente estas métricas serán empleadas en los modelos de regresión.
V.II Análisis de regresión
En esta segunda etapa se cuantifica el efecto que tienen las Métricas de Conexiones y el desempeño financiero a través de los modelos de regresión lineal múltiple, por lo cual se utilizan las ecuaciones de la sección IV.
En el primer modelo se define como variable dependiente al nivel de ingreso y las variables independientes son la cantidad de administradores en común con empresas del mismo sector y otros sectores; adicionalmente, se incluye la interacción entre estas variables. Este modelo corresponde a la ecuación 8.
Para el segundo modelo se define como variable dependiente al nivel de ingreso y la variable independiente es eigen centrality, este modelo corresponde a la ecuación 9. Para ambos modelos se usó como variable de control el tamaño de las compañías. La variable dependiente empleada en los modelos fue transformada de forma logarítmica con el objetivo de reducir la varianza y además para facilitar la interpretación de los resultados.
Las variables independientes fueron seleccionadas para los modelos de acuerdo a los resultados obtenidos en el análisis de correlación, dado que estas variables presentaban la mayor correlación con el nivel de ingreso dentro de las Métricas de Conexiones. Los resultados obtenidos del análisis de regresión se muestran en la tabla 2 y fueron estadísticamente significativas al menos con un p-value del 0.05.
En el modelo 1 existen 3 interpretaciones principales. Al contratar a un administrador adicional que dirige o ha dirigido una empresa en el mismo sector, se esperaría que el nivel de ingreso aumente en promedio 1%. Por otro lado, si este administrador adicional compartido se lo tiene con una empresa que pertenece a otro sector, se esperaría que el ingreso aumente en promedio un 2%. Cuando este administrador adicional compartido trabaja o ha trabajado en una empresa que pertenece al mismo sector y a otros, se esperaría que el ingreso disminuya en promedio 0.1%. De esta manera se responde la pregunta P1 planteada en la sección I.
Por otro lado, existe una interpretación relevante para el segundo modelo. La variable independiente eigen centrality fue normalizada y representa hasta que punto una empresa prominente está conectada con otras empresas prominentes dentro de la industria. Por lo tanto, para responder la pregunta P2 de la sección I, se ha determinado que si las conexiones de una empresa se vuelven más densas en un 10% (es decir, que sus conexiones sean más influyentes), se esperaría que el ingreso en promedio aumente en 5.14%.

V.III Clusters
Para la detección de comunidades a través de la modularidad de un grafo, se utilizó el algoritmo de Louvain. Usando esta herramienta se encontró 3,146 comunidades conformadas desde 1 hasta 69 compañías.
Debido a la gran cantidad de comunidades, se escogió las primeras 20 agrupaciones que contenían el mayor número de empresas. Estas comunidades contenían 722 empresas que representan el 7.96% del total de compañías y dentro de cada comunidad se encontraban más de 20 compañías.
En las figuras que se realizó, la magnitud o tamaño de cada nodo está dado por el valor del indicador eigen centrality. En la figura 4 se muestra un gráfico general con las 20 comunidades, y el color de cada nodo representa la comunidad a la que pertenece cada empresa.
Para el caso de las 20 comunidades con mayor número de compañías, se realizó 2 gráficos adicionales de acuerdo con el sector y tamaño de las empresas. En la figura 5, el color representa tanto el tamaño de cada compañía, como al sector al que pertenece.
Red de Administradores Compartidos y su Relación con
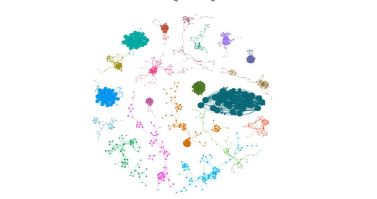
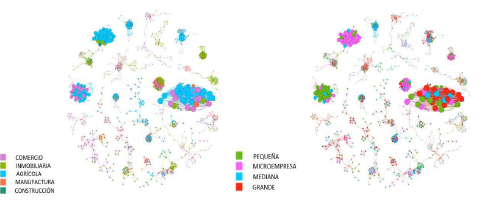
Al visualizar el gráfico 5 se descubrió que en las comunidades de las empresas con mayor valor de eigen centrality, el sector agrícola es el predominante al poseer el mayor número de empresas. Este hecho fue corroborado al realizar la correlación entre eigen centrality y las variables dummy creadas para cada sector, en la cual se obtuvo como resultado que la más alta correlación fue positiva y pertenecía al sector agrícola. El valor obtenido fue de 0.15 y estadísticamente significativo con un p-value de al menos 0.05.
Además, se observó en el gráfico 5 que las comunidades cuentan con mayor presencia de empresas grandes, pero estas empresas de tamaño grande no necesariamente poseen con un valor de eigen centrality alto. Por lo tanto, al realizar la correlación entre eigen centrality y las variables dummy creadas para cada tamaño, se obtuvo como resultado que la más alta correlación fue positiva y correspondía a las empresas de tamaño grande. El valor obtenido fue de 0.15 y estadísticamente significativo con un p-value de al menos 0.05.
Adicionalmente, en la tabla 3 se muestra el top 10 de empresas según los valores de eigen, betweenness y closeness centrality. En la tabla se puede constatar que para el top de acuerdo al valor de eigen centrality, las empresas de tamaño grande y del sector agrícola son las de mayor frecuencia.
| Rango | Eigen | Betweenness | Closeness |
| 1 | BANANERA LAS MERCEDES S.A | INASA | BUSKARINA S.A. |
| (grande, agrícola) | (mediana, manufactura) | (grande, manufactura) | |
| 2 | CIUSAPLANEWSA S.A | LANGOSTINO S.A | OCRES CIA. LTDA |
| (micro, agrícola) | (grande, agrícola) | (micro, manufactura) | |
| 3 | CIA. AGRIC. LOMA LARGA S.A | ALM. JUAN ELJURI CIA.LTDA | IGLESIAS TAPIA CIA. LTDA |
| (grande, agrícola) | (grande, comercio) | (grande, comercio) | |
| 4 | AGRIMONT S.A | GOLDENSHRIMP S.A | PROMORYMAPI S.A |
| (mediana, agrícola) | (grande, agrícola) | (pequeña, inmobiliaria) | |
| 5 | IND. BANANERA ALAMOS S.A | RESINESA | BUNTER S.A |
| (grande, agrícola) | (grande, comercio) | (micro, inmobiliaria) | |
| 6 | CARIVESA | BOUTERRUASA | CONST. VIAS Y MAQUIN. CIA. LTDA. |
| (grande, comercio) | (micro, comercio) | (micro, construcción) | |
| 7 | CIA. AGRIC. LA JULIA S.A | SOLIDASA | PLANTEC CIA. LTDA |
| (grande, agrícola) | (mediana, manufactura) | (grande, agrícola) | |
| 8 | CAAMSA | CRISTATERRA S.A | URUGEQUIN S.A |
| (grande, agrícola) | (pequeña, inmobiliaria) | (micro, agrícola) | |
| 9 | FRUSHI S.A | INDUMOT S.A | CERANDINA CIA. LTDA |
| (mediana, agrícola) | (grande, manufactura) | (pequeña, manufactura) | |
| 10 | CABE | CORP. FAVORITA C.A | ATILEUBA CIA.LTDA |
| (mediana, agrícola) | (grande, comercio) | (pequeña, inmobiliaria) |
VI. CONCLUSIONES
Los resultados de esta investigación se orientan a encontrar la relación entre las Métricas de Conexiones e indicadores financieros y cuantificar el efecto de dicha relación. Los resultados obtenidos aportan para llegar a mercados laborales más eficientes a través del uso de conexiones sociales, de tal manera que se reduce el nivel de asimetría de información entre firmas. Sobremanera, otro objetivo de esta investigación fue encontrar comunidades dentro de la industria al evaluar las relaciones entre empresas y se determinó que en los grupos había tanto sector como tamaño de empresa predominante para el top 20 analizado.
En este estudio se está consciente de que la investigación podría tener dos limitaciones. La primera limitación se da debido a que el trabajo no abarca datos temporales, de tal manera que si se lo desarrollara, se podría ver el efecto de las métricas a través del tiempo. La segunda limitación surge por la cantidad de empresas utilizadas dado el número de modificaciones que se realizó al dataset original.
Los resultados obtenidos demuestran la existencia una correlación moderadamente positiva entre las Métricas de Conexiones y el desempeño financiero, a excepción de closeness centrality. Los modelos regresión planteados mostraron que tener conexiones con otras empresas, no necesariamente produce un efecto positivo sobre el desempeño financiero. El modelo propuesto es una herramienta útil, que además de
utilizar variables del campo de la teoría económica, también implementa instrumentos que miden las conexiones entre compañías. Este modelo puede ser utilizado por las empresas para predecir del desempeño financiero, dado ciertas especificaciones.
Referencias
Beauchamp, M. A. (1965). An improved index of centrality. Behavioral science, 10(2), 161-163.
Bloch, F., & Jackson, M. O. (2016). Centrality Measures in Networks. SSRN Electronic Journal. doi:10.2139/ssrn.2749124
Blondel, V. D., Guillaume, J.-L., Lambiotte, R., & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008(10), P10008. doi:10.1088/1742-5468/2008/10/p10008
Braha, D., Stacey, B., & Bar-Yam, Y. (2011). Corporate competition: A self-organized network. Social Networks, 33(3), 219–230.doi:10.1016/j.socnet.2011.05.004
Brandes, L., Brechot, M., & Franck, E. (2015). Managers’ external social ties at work: Blessing or curse for
Brandes, U. (2001). A faster algorithm for betweenness centrality. The Journal of Mathematical Sociology, 25.
Calvó-Armengol, Antoni, and Matthew O. Jackson. (2004). "The Effects of Social Networks on Employment and Inequality." American Economic Review, 94 (3): 426-454. doi: 10.1257/0002828041464542
Chen, M., Liu, H., Wei, S., & Gu, J. (2018). Top managers’ managerial ties, supply chain integration, and firm performance in China: A social capital perspective. Industrial Marketing Management. doi:10.1016/j.indmarman.2018.04.013
Elouaer-Mrizak, S., & Chastand, M. (2013). Detecting Communities within French Intercorporate Network. Procedia - Social and Behavioral Sciences, 79, 82–100.doi:10.1016/j.sbspro.2013.05.058
Everard, A., & Henry, R. (2002). A social network analysis of interlocked directorates in electronic commerce firms. Electronic Commerce Research and Applications, 1(2), 225–234. doi:10.1016/s1567- 4223(02)00014-5
Freeman, L. C. (1978). Ceentrality ub Social Networks Conceptual Clarification. Social Networks, 215-239.
Granovetter, M. (1973) The Strength of Weak Ties. American Journal of Sociology, Vol. 78, No. 6 (May, 1973), pp. 1360-1380.
Jackson, M. O. (2011). An Overview of Social Networks and Economic Applications. Handbook of Social Economics, 511–585. doi:10.1016/b978-0-444-53187-2.00012-7
Jackson, M. O., & Golub, B. (2007). Naive Learning in Social Networks: Convergence, Influence and Wisdom of Crowds. SSRN Electronic Journal. doi:10.2139/ssrn.994312
Jackson, M. O., & Wolinsky, A. (1996). A Strategic Model of Social and Economic Networks. Journal of Economic Theory, 71(1), 44–74. doi:10.1006/jeth.1996.0108
Leon, R. – D., Rodríguez-Rodríguez, R., Gómez-Gasquet, P., & Mula, J. (2017). Social network analysis: A tool for evaluating and predicting future knowledge flows from an insurance organization. Technological Forecasting and Social Change, 114, 103–118. doi:10.1016/j.techfore.2016.07.032
Ma, Z., Sheng, O. R. L., & Pant, G. (2009). Discovering company revenue relations from news: A network approach. Decision Support Systems, 47(4), 408–414. doi:10.1016/j.dss.2009.04.007
Mahdi, K., Almajid, A., Safar, M., Riquelme, H., & Torabi, S. (2012). Social Network Analysis of Kuwait Publicly-Held Corporations. Procedia Computer Science, 10, 272–281. doi:10.1016/j.procs.2012.06.037
Mahdi, K., Almajid, A., Safar, M., Riquelme, H., & Torabi, S. (2012). Social Network Analysis of Kuwait Publicly-Held Corporations. Procedia Computer Science, 10, 272–281. doi:10.1016/j.procs.2012.06.037
Massó, M., & Arnulfo Ruiz-León, A. (2017). The configuration of a status based model of economic actors: The case of Spanish government debt market. Social Networks, 48, 23– 35.doi:10.1016/j.socnet.2016.07.004
Piccardi, C., Calatroni, L., & Bertoni, F. (2010). Communities in Italian corporate networks. Physica A: Statistical Mechanics and Its Applications, 389(22), 5247–5258. doi:10.1016/j.physa.2010.06.038
Powell, W., Koput, K., Smith, L. y Owen, J. (1999) Network Position and Firm Performance: Organizational Returns to Collaboration in the Biotechnology Industry. Research in the Sociology of Organizations, JAI Press Inc
Prem Sankar, C., Asokan, K., & Satheesh Kumar, K. (2015). Exploratory social network analysis of affiliation networks of Indian listed companies. Social Networks, 43, 113–120. doi:10.1016/j.socnet.2015.03.008
Recober, A., Kuburas, A., Zhang, Z., Wemmie, J. A., Anderson, M. G., & Russo, A. F. (8 de 07 de 2009). Role of Calcitonin Gene-Related Peptide in Light-Aversive Behavior: Implications for Migraine. The Journal od Neuroscience, 29(27), 8798-8804.
Spearman, C. (1904). The proof and measurement of association between two things. . Am. J. Psychol, 72- 101.
Spelta, A., Flori, A., & Pammolli, F. (2018). Investment communities: Behavioral attitudes and economic dynamics. Social Networks, 55, 170–188.doi:10.1016/j.socnet.2018.07.004
Wältermann, M., Wolff, G., & Rank, O. (2019). Formal and informal cross-cluster networks and the role of funding: A multi-level network analysis of the collaboration among publicly and privately funded cluster organizations and their managers. Social Networks, 58, 116–127. doi:10.1016/j.socnet.2019.03.003
Warrick, R., Zafeirios, F., Kyriacos, N., Bhowmik, D., Murray, S., & Seth, A. K. (17 de 01 de 2019). Activity in perceptual classification networks as a basis for human subjective time perception. Nature Communications, 10(267).
Wu, L., Ching-Yung, L., & Sinan, A. (2009). Value of Social Network -- A Large-Scale Analysis on Network Structure Impact to Financial Revenue of Information Technology Consultants.
Zusrony, E., Purnomo, H. y Yulianto, S. (2019). Network Mapping Analysis Communication Employees Use Social Network Analysis at Multifinance Companies. https://doi.org/10.29407/intensif.v3i2.12786 Red de Administradores Compartidos y su Relación con el Desempeño Financiero en Empresas del Ecuador

